
Spring Kafka事务导致每个消息的生产者偏移增加了两个

我在一个使用Spring(boot)Kafka的微服务中有一个消费-转换-生产工作流。我需要实现Kafka交易提供的精确一次scemantics。下面是代码片段:
配置
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
props.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);
props.put(ProducerConfig.MAX_REQUEST_SIZE_CONFIG, 1024 * 1024);
DefaultKafkaProducerFactory<String, String> defaultKafkaProducerFactory = new DefaultKafkaProducerFactory<>(props);
defaultKafkaProducerFactory.setTransactionIdPrefix("kafka-trx-");
return defaultKafkaProducerFactory;
}
@Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, bootstrapServers);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 5000);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
props.put(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed");
return new DefaultKafkaConsumerFactory<>(props);
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
@Bean
public KafkaTransactionManager<String, String> kafkaTransactionManager() {
return new KafkaTransactionManager<>(producerFactory());
}
@Bean
@Qualifier("chainedKafkaTransactionManager")
public ChainedKafkaTransactionManager<String, Object> chainedKafkaTransactionManager(KafkaTransactionManager<String, String> kafkaTransactionManager) {
return new ChainedKafkaTransactionManager<>(kafkaTransactionManager);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<?, ?> concurrentKafkaListenerContainerFactory(ChainedKafkaTransactionManager<String, Object> chainedKafkaTransactionManager) {
ConcurrentKafkaListenerContainerFactory<String, String> concurrentKafkaListenerContainerFactory = new ConcurrentKafkaListenerContainerFactory<>();
concurrentKafkaListenerContainerFactory.setConsumerFactory(consumerFactory());
concurrentKafkaListenerContainerFactory.setBatchListener(true);
concurrentKafkaListenerContainerFactory.setConcurrency(nexusConsumerConcurrency);
//concurrentKafkaListenerContainerFactory.setReplyTemplate(kafkaTemplate());
concurrentKafkaListenerContainerFactory.getContainerProperties().setAckMode(AbstractMessageListenerContainer.AckMode.BATCH);
concurrentKafkaListenerContainerFactory.getContainerProperties().setTransactionManager(chainedKafkaTransactionManager);
return concurrentKafkaListenerContainerFactory;
}
听众
@KafkaListener(topics = "${kafka.xxx.consumerTopic}", groupId = "${kafka.xxx.consumerGroup}", containerFactory = "concurrentKafkaListenerContainerFactory")
public void listen(@Payload List<String> msgs, @Header(KafkaHeaders.RECEIVED_PARTITION_ID) List<Integer> partitions, @Header(KafkaHeaders.OFFSET) List<Integer> offsets) {
int i = -1;
for (String msg : msgs) {
++i;
LOGGER.debug("partition={}; offset={}; msg={}", partitions.get(i), offsets.get(i), msg);
String json = transform(msg);
kafkaTemplate.executeInTransaction(kt -> kt.send(producerTopic, json));
}
}

共有1个答案

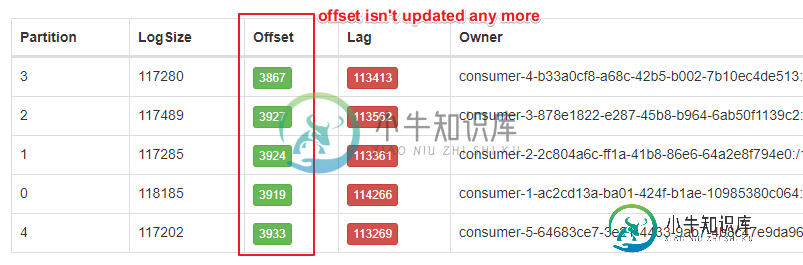
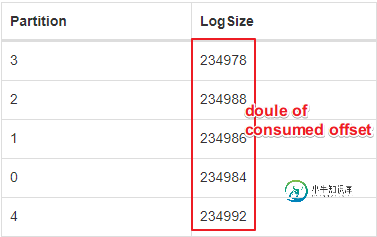
它就是这样设计的。Kafka日志是不可变的,所以在事务结束时使用一个额外的“槽”来指示事务是提交还是回滚。这允许具有read_committe隔离级别的使用者跳过回滚事务。
如果在一个事务中发布10条记录,您将看到偏移量增加11。如果你只发布一个,它会增加两个。
如果希望发布参与消费者启动的事务(确切地说一次),则不应使用executeintransaction;那将开始一个新的交易。
/**
* Execute some arbitrary operation(s) on the operations and return the result.
* The operations are invoked within a local transaction and do not participate
* in a global transaction (if present).
* @param callback the callback.
* @param <T> the result type.
* @return the result.
* @since 1.1
*/
<T> T executeInTransaction(OperationsCallback<K, V, T> callback);
@SpringBootApplication
public class So59152915Application {
public static void main(String[] args) {
SpringApplication.run(So59152915Application.class, args);
}
@Autowired
private KafkaTemplate<String, String> template;
@KafkaListener(id = "foo", topics = "so59152915-1", clientIdPrefix = "so59152915")
public void listen1(String in, @Header(KafkaHeaders.OFFSET) long offset) throws InterruptedException {
System.out.println(in + "@" + offset);
this.template.send("so59152915-2", in.toUpperCase());
Thread.sleep(2000);
}
@KafkaListener(id = "bar", topics = "so59152915-2")
public void listen2(String in) {
System.out.println(in);
}
@Bean
public NewTopic topic1() {
return new NewTopic("so59152915-1", 1, (short) 1);
}
@Bean
public NewTopic topic2() {
return new NewTopic("so59152915-2", 1, (short) 1);
}
@Bean
public ApplicationRunner runner(KafkaListenerEndpointRegistry registry) {
return args -> {
this.template.executeInTransaction(t -> {
IntStream.range(0, 11).forEach(i -> t.send("so59152915-1", "foo" + i));
try {
System.out.println("Hit enter to commit sends");
System.in.read();
}
catch (IOException e) {
e.printStackTrace();
}
return null;
});
};
}
}
@Component
class Configurer {
Configurer(ConcurrentKafkaListenerContainerFactory<?, ?> factory) {
factory.getContainerProperties().setCommitLogLevel(Level.INFO);
}
}
spring.kafka.producer.transaction-id-prefix=tx-
spring.kafka.consumer.properties.isolation.level=read_committed
spring.kafka.consumer.auto-offset-reset=earliest
和
foo0@56
2019-12-04 10:07:18.551 INFO 55430 --- [ foo-0-C-1] essageListenerContainer$ListenerConsumer : Sending offsets to transaction: {so59152915-1-0=OffsetAndMetadata{offset=57, leaderEpoch=null, metadata=''}}
foo1@57
FOO0
2019-12-04 10:07:18.558 INFO 55430 --- [ bar-0-C-1] essageListenerContainer$ListenerConsumer : Sending offsets to transaction: {so59152915-2-0=OffsetAndMetadata{offset=63, leaderEpoch=null, metadata=''}}
2019-12-04 10:07:20.562 INFO 55430 --- [ foo-0-C-1] essageListenerContainer$ListenerConsumer : Sending offsets to transaction: {so59152915-1-0=OffsetAndMetadata{offset=58, leaderEpoch=null, metadata=''}}
foo2@58
-
我有一个生产者/消费者场景,我不希望一个生产者交付产品,多个消费者消费这些产品。然而,常见的情况是,交付的产品只被一个消费者消费,而其他消费者从未看到过这个特定的产品。我不想实现的是,一个产品被每个消费者消费一次,而没有任何形式的阻碍。 我的第一个想法是使用多个BlockingQueue,每个消费者使用一个,并使生产者将每个产品按顺序放入所有可用的BlockingQueues中。但是,如果其中一个
-
这是一个一般性问题,因为它不仅适用于我的场景(使用Azure服务总线),而且适用于带有事件的发布/订阅服务器上下文中的任何事件总线。 主题是一对多通信的输出框(我将其解释为一个事件发布者,多个订阅者) 主题可以处理不同类型的事件消息,只要它们在某种程度上是相关的(当然,这是非常相关的) 在DDD中,有一个有界上下文的概念,我喜欢将微服务/模块作为实现这些有界上下文的一种方式。因此,即使其他一些服务
-
我有一个消费转换产品应用程序,在Kafka中有一次精确的权杖。(事务性)生成阶段在同一主题上生成新消息,然后使用该消息(事务性=read_committed)。只有一个线程执行此操作,并确保消费者轮询在生产者的事务提交之后发生。现在我每轮只有一份民意调查报告。 当我运行我的测试用例时,有时可能会有其他生产者在我的生产者的事务提交之前发送的消息。然后我经历了以下情况: 我的单个poll语句只返回这个
-
本周早些时候,我在这里获得了一些关于Stackoverflow的帮助,这导致了一个生产者/消费者模式的发展,用于加载处理并将大型数据集导入RavenDb。CPU受限任务的并行化与IO受限任务的并行化 我现在希望限制生产商提前准备的工作单元的数量,以管理内存消耗。我已经使用一个基本信号量实现了节流,但在某个点上实现死锁时遇到了问题。 我无法找出导致死锁的原因。以下是代码摘录: 这是对LoadData
-
假设,我有多个Kafka制作者同时为单个Kafka主题生成数据。 有可能得到哪个是给定生产者生产的最后一个偏移吗? 例如: 生产者: 我想找出分别由P1和P2发布的最后一条记录的偏移量。 请注意,我不是在要求全局主题分区偏移量。
-
我有一个使用ActiveMQ的消息队列。web请求用persistency=true将消息放入队列。现在,我有两个消费者,它们都作为单独的会话连接到这个队列。使用者1总是确认消息,但使用者2从不这样做。 JMS队列实现负载平衡器语义。一条消息将被一个使用者接收。如果在发送消息时没有可用的使用者,它将被保留,直到有可以处理消息的使用者可用为止。如果使用者接收到一条消息,但在关闭之前没有确认它,那么该