
从size_t到double的铸造性能

TL;DR:为什么size_t乘法/转换数据的速度很慢,为什么这因平台而异?
我遇到了一些不完全理解的性能问题。上下文是一个相机图像采集卡,其中以100 Hz的速率读取和后处理128x128 uint16_t图像。
在后处理中,我生成一个直方图帧-
double sum=0, sumsquared=0;
size_t thismaxval = 1 << 16;
for(size_t i = 0; i < thismaxval; i++) {
sum += (double)i * frame->histo[i];
sumsquared += (double)(i * i) * frame->histo[i];
}
用profile分析代码我得到了以下(示例、百分比、代码):
58228 32.1263 : sum += (double)i * frame->histo[i];
116760 64.4204 : sumsquared += (double)(i * i) * frame->histo[i];
或者,第一行占用32%的CPU时间,第二行占用64%。
我做了一些基准测试,似乎是数据类型/转换有问题。当我将代码更改为
uint_fast64_t isum=0, isumsquared=0;
for(uint_fast32_t i = 0; i < thismaxval; i++) {
isum += i * frame->histo[i];
isumsquared += (i * i) * frame->histo[i];
}
它的运行速度快了大约10倍。然而,这种性能损失也因平台而异。在工作站上,酷睿i7 CPU 950(3.07 GHz)的速度快了10倍。在我的Macbook8,1上,它的英特尔酷睿i7 Sandy Bridge 2.7 GHz (2620M)代码只快了两倍。
现在我在想:
为什么原始代码如此缓慢且容易加速?- 为什么每个平台的差异如此之大?
更新:
我编译了上面的代码
g++ -O3 -Wall cast_test.cc -o cast_test
更新2:
我通过分析器(Mac上的仪器,如Shark)运行优化代码,发现了两件事:
1)在某些情况下,循环本身需要相当长的时间。thismaxval 的类型为 size_t。
对于(size_ti=0; i
2) 数据类型和类型转换问题如下:
sumsquared=(double)(i*i)*历史[i] 15%(带有<代码>大小_t i)sumsquared=(double)(i*i)*历史[i] 36%(使用<代码>uint_fast32_t i)isumsquared=(i*i)*历史[i] 13%(与<代码>uint_fast32_t i,<代码>uint_fast 64_t isumsquaredisumsquared=(i*i)*历史[i] 11%(使用<代码>int i,<代码>uint_fast64_t isumsquared
令人惊讶的是,int比uint_fast32_t?
更新4:
我在一台机器上用不同的数据类型和不同的编译器又做了一些测试。结果如下。
对于testd 0 - 2,相关代码为
for(loop_t i = 0; i < thismaxval; i++)
sumsquared += (double)(i * i) * histo[i];
求和平方为双精度,loop_t size_t,uint_fast32_t和 int 用于检验 0、1 和 2。
对于测试3--5,代码是
for(loop_t i = 0; i < thismaxval; i++)
isumsquared += (i * i) * histo[i];
使用 uint_fast64_t 型的等方形,loop_t再次size_t、uint_fast32_t 和 int 进行检验 3、4 和 5。
我使用的编译器是gcc 4.2.1、gcc 4-4.7、gcc-4.6.3和gcc-7.0。计时是以代码总cpu时间的百分比表示的,因此它们显示的是相对性能,而不是绝对性能(尽管运行时间在21秒时非常恒定)。cpu时间用于两行代码,因为我不太确定探查器是否正确地分隔了两行代码。
gcc: 4.2.1 4.4.7 4.6.3 4.7.0 ---------------------------------- test 0: 21.85 25.15 22.05 21.85 test 1: 21.9 25.05 22 22 test 2: 26.35 25.1 21.95 19.2 test 3: 7.15 8.35 18.55 19.95 test 4: 11.1 8.45 7.35 7.1 test 5: 7.1 7.8 6.9 7.05
或者:
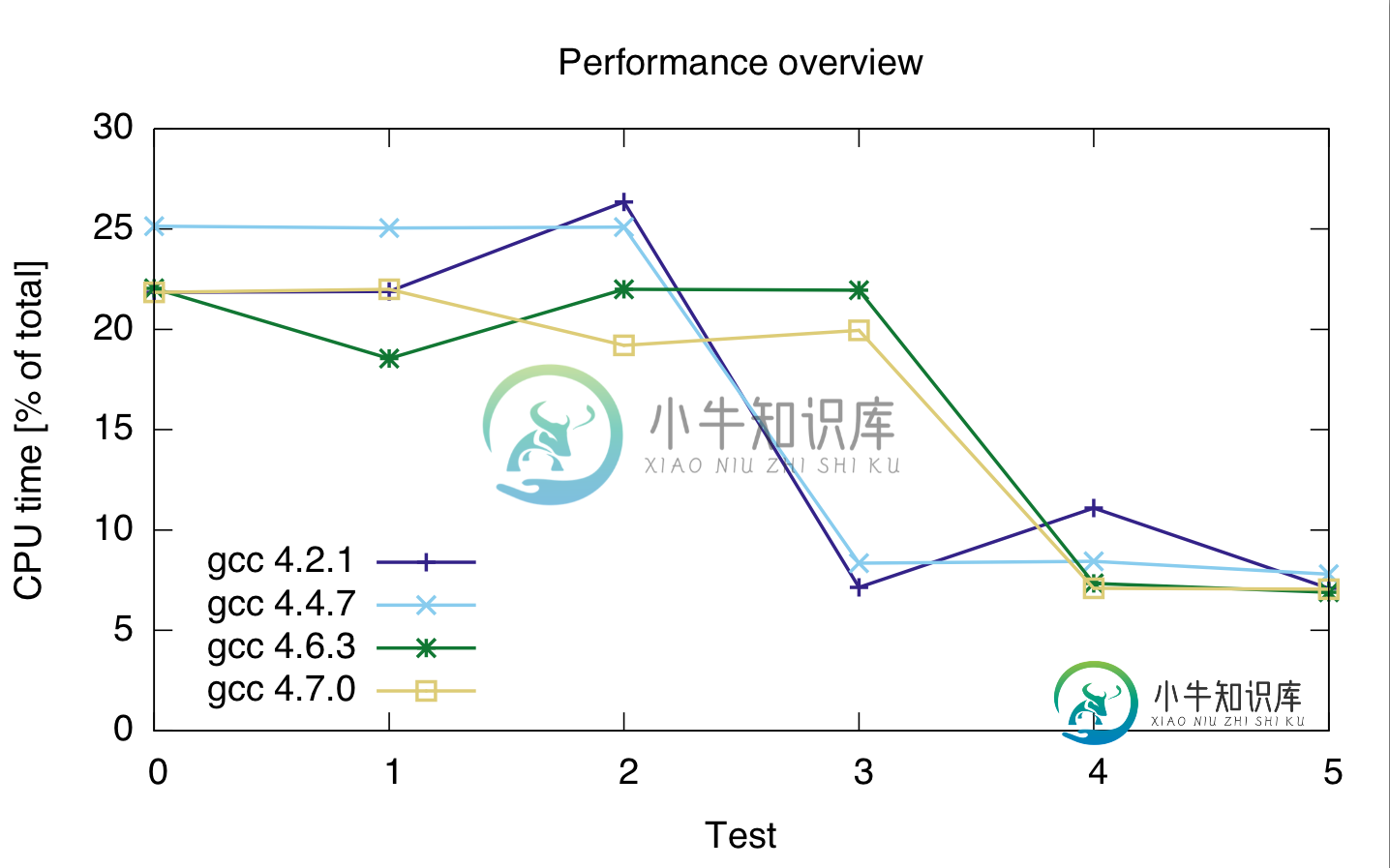
基于此,似乎铸造是昂贵的,不管我使用什么整数类型。
此外,gcc 4.6和4.7似乎无法正确优化循环3 (size_t和uint_fast64_t)。
共有2个答案

在x86上,将<code>uint64_t、<code>int32_t和<code>int16_tint16_t和在32位模式下int64_t只能使用x87指令而不是SSE进行转换。
当将<code>uint64_t
uint32_t首先扩展为int64_t。
在具有特定64位功能的处理器上以32位模式转换64位整数时,存储到加载的转发问题可能会导致暂停。64位整数以两个32位值的形式写入,以一个64位值的形式读回。如果转换是长依赖链的一部分,这可能非常糟糕(在本例中并非如此)。

对于您最初的问题:
对于其他问题:
-
< li >“想不到int比uint_fast32_t还快”?你们平台上的sizeof(size_t)和sizeof(int)是什么?我可以做出的一个猜测是,两者都可能是64位的,因此转换为32位不仅会导致计算错误,还会导致不同大小的转换损失。
一般来说,如果没有必要,尽量避免可见和隐藏的强制转换。例如,尝试找出您的环境(gcc)中隐藏在“size_t”后面的实际数据类型,并将其用于循环变量。在您的示例中,uint的平方不能是浮点数据类型,因此在这里使用double没有意义。坚持使用整数类型以实现最大性能。
-
另外,每当调用paint方法并再次绘制相同的屏幕时,Java是否会进行任何优化?例如,如果您只在屏幕上移动一个元素,那么通常只需要更新该元素。似乎每次调用paint方法时,java都会重新绘制和处理整个屏幕。对我来说,这一切似乎都是不必要的处理密集。 示例代码:
-
我试图从一个Cloud Foundry Java应用程序中调用javac,以便在应用程序运行时编译一个Java文件。我有一个关于正在使用哪个JDK的问题。 为了测试这一点,在我的应用程序中,我使用语句ToolProvider.getSystemJavaCompiler()实例化了一个JavaCompiler,并打印出编译器实例。应用程序部署在CF上并打印出来:com.sun.tools.javac
-
我目前在辅导一个高中生AP Java,她问了我一个关于“双选”的问题。我以前从未听说过这个术语,但显然她的老师希望她在即将到来的期末考试中知道这个术语。 她的老师提供的例子是,如果你想将一个整数转换成一个字符串,你必须执行以下操作才能避免编译器错误: 问题是:你想在现实生活中什么时候这样做? 老师只提供了导致运行时错误的示例。此外,我从来不知道有一个术语,但这样做似乎是个坏主意,因为只有当两种类型
-
在最近的一个问题中,有人提到,当使用printf打印指针值时,调用方必须将指针强制转换为void*,如下所示: 为了我的生命,我不知道为什么。我发现这个问题,几乎是一样的。这个问题的答案是正确的——它解释了整数和指针的长度不一定相同。 当然,这是正确的,但是当我已经有了指针,就像上面的例子一样,为什么我要从转换到?什么时候int*与void*不同?事实上,什么时候生成的机器代码不同于简单的? 更新
-
嗨,我最近看到了一个类似这样的问题 在我回答了这个问题后,事实证明我弄错了,我回答了整数。MIN_VALUE但正确的答案是整数。MAX_VALUE。经过进一步的测试,我意识到我对大于整数的int施加的任何双精度。MAX_VALUE只是使int等于整数。MAX_VALUE。例如 经过进一步的测试,我意识到如果你试图将long转换为int,似乎会将int分配给一个看似随机的数字。 所以我的问题是。到底
-
我正在使用Java Mysql连接器,并且在提取结果时遇到问题: 这是需要执行的查询和准备好的语句: 现在我尝试在数组中获取结果,所以我使用: (1) 返回mysql。数组,该数组包含一个定位器,它是指向服务器上的SQL array的逻辑指针,并且(2)应该对temp进行类型转换并返回一个String[],但是我收到了这个错误 有什么想法吗?