
派斯帕克:在 UDF 中传递多列

我正在编写一个用户定义的函数,它将接受数据帧中除第一列之外的所有列,并进行求和(或任何其他操作)。现在,数据帧有时可以有3列或4列或更多。会有所不同。
我知道我可以在UDF中硬编码4个列名作为传递,但在这种情况下它会有所不同,所以我想知道如何完成它?
这里有两个示例,第一个示例中我们有两列要添加,第二个示例中有三列要添加。
共有3个答案

使用结构而不是数组
from pyspark.sql.types import IntegerType
from pyspark.sql.functions import udf, struct
sum_cols = udf(lambda x: x[0]+x[1], IntegerType())
a=spark.createDataFrame([(101, 1, 16)], ['ID', 'A', 'B'])
a.show()
a.withColumn('Result', sum_cols(struct('A', 'B'))).show()

另一种没有数组和结构的简单方法。
from pyspark.sql.types import IntegerType
from pyspark.sql.functions import udf
def sum(x, y):
return x + y
sum_cols = udf(sum, IntegerType())
a=spark.createDataFrame([(101, 1, 16)], ['ID', 'A', 'B'])
a.show()
a.withColumn('Result', sum_cols('A', 'B')).show()

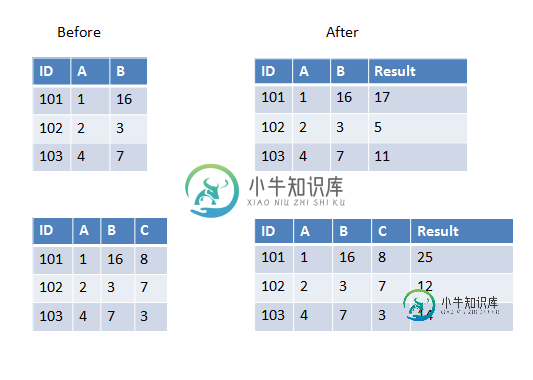
如果要传递到UDF的所有列都具有相同的数据类型,则可以使用数组作为输入参数,例如:
>>> from pyspark.sql.types import IntegerType
>>> from pyspark.sql.functions import udf, array
>>> sum_cols = udf(lambda arr: sum(arr), IntegerType())
>>> spark.createDataFrame([(101, 1, 16)], ['ID', 'A', 'B']) \
... .withColumn('Result', sum_cols(array('A', 'B'))).show()
+---+---+---+------+
| ID| A| B|Result|
+---+---+---+------+
|101| 1| 16| 17|
+---+---+---+------+
>>> spark.createDataFrame([(101, 1, 16, 8)], ['ID', 'A', 'B', 'C'])\
... .withColumn('Result', sum_cols(array('A', 'B', 'C'))).show()
+---+---+---+---+------+
| ID| A| B| C|Result|
+---+---+---+---+------+
|101| 1| 16| 8| 25|
+---+---+---+---+------+
-
我有一个用斯卡拉写的UDF,我希望能够通过Pyspark会话调用它。UDF 采用两个参数:字符串列值和第二个字符串参数。我已经能够成功地调用UDF,如果它只需要一个参数(列值)。如果需要多个参数,我很难调用UDF。以下是到目前为止我在斯卡拉和Pyspark中能够做的事情: Scala UDF: 在Scala中使用它时,我已经能够注册和使用这个UDF: Scala主类: 以上工作成功。下面是Pysp
-
我正在尝试将两个PySpark数据帧与仅位于其中一个上的列连接起来: 现在我想生成第三个数据帧。我想要像熊猫这样的东西: 这可能吗?
-
我想计算PySpark数据帧的两列之间的Jaro Winkler距离。Jaro-Winkler距离可通过所有节点上的pyjarowinkler包获得。 pyjarowinkler的工作原理如下: 输出: 我试图编写一个UDF,将两列作为序列传递,并使用lambda函数计算距离。我是这样做的: 我应该能够在上述函数中传递任意两个字符串列。我得到以下输出: 预期产出: 我怀疑这可能是因为不正确。它包含
-
我有一个包含两列的数据帧,一列是数据,另一列是该数据字段中的字符计数。 我想根据count列中的值更改列数据的值。如何实现这一点?我尝试使用一个udf: 这似乎是失败的,这是正确的做法吗?
-
在计算附加信息时发生内部错误。org.eclipse.jdt.internal.core.SearchableEnvironment.(Lorg/eclipse/jdt/内部/核心/JavaProject; Lorg/eclipse/jdt/核心/WorkingCopyOwner;)
-
我正在编写一个udf,它将包含两个dataframe列以及一个额外的参数(常量值),并将向dataframe添加一个新列。我的函数如下所示: 此外,我还做了以下工作来传入多个列: 除非我删除作为函数第三个参数的< code>constant_var,否则现在这种方法不起作用,但是我真的需要这样做。所以我试着做了如下的事情: 和 以上这些都不适合我。我是根据这个和这个stackoverflow帖子得