
UDF
基于spring boot / spring cloud 的基础项目,脚手架,主要用于学习和实践
按照spring boot的思想,将各个不同的功能按照starter的形式拆分开来,做到灵活组合
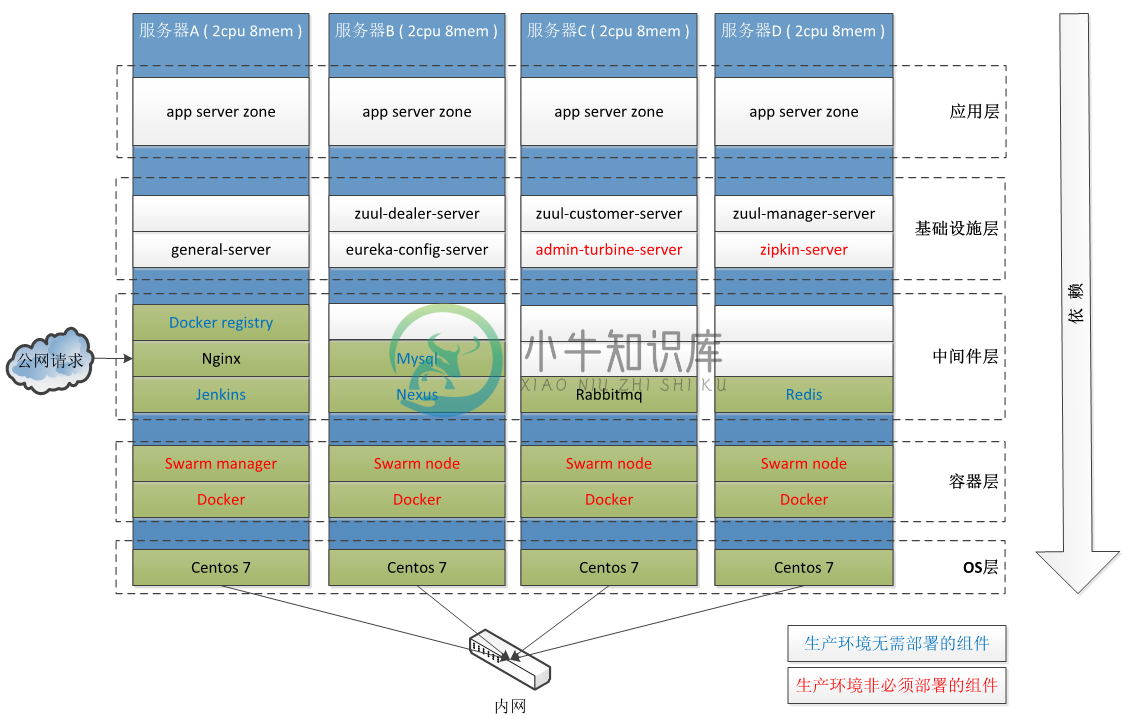
物理架构示意
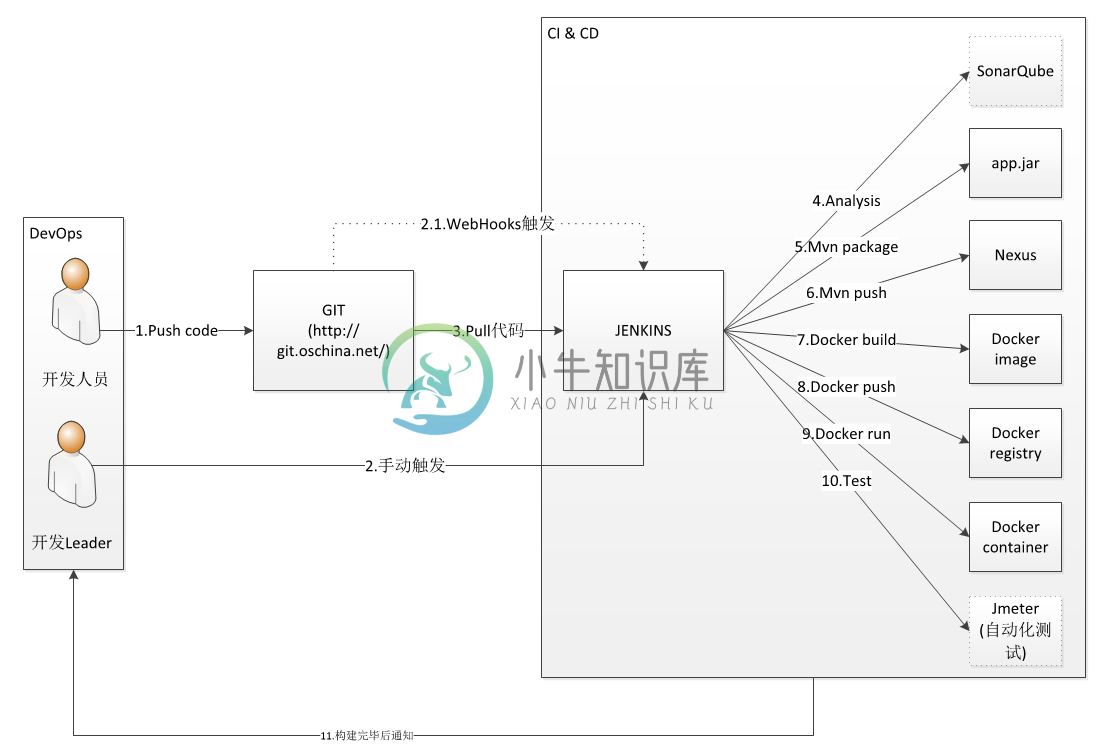
CI & CD 示意
代码仓库 (点击跳转)
项目博客 (点击跳转)
项目包说明
udf-starter
udf-start-core : 核心包,包含统一异常处理,标准json输出,在线api文档,线程池配置,xss处理,等
udf-starter-cors : 跨域请求配置
udf-starter-file : 文件服务
udf-starter-id : 分布式ID服务
udf-starter-mail : 邮件服务
udf-starter-qrcode : 二维码服务
udf-starter-rms : rest远程调用服务,包含服务间认证和治理
udf-starter-scheduler : 分布式调度服务
udf-starter-scheduler-client : 分布式调度客户端
udf-starter-datasource : 数据源
udf-starter-connection-pool-druid : druid数据源
udf-starter-amqp-rabbitmq : 消息中间件
udf-starter-auth : 用户认证服务
udf-starter-datasource-dynamic : 动态数据源
udf-sample
udf-eureka-config-server-demo : 服务注册中心 和 配置中心
udf-admin-server-demo : 监控中心 和 断路器看板
udf-config-hub : 配置文件仓库
udf-zuul-server-demo : 网关
udf-general-server-demo : 公共服务
udf-service-a-demo : demo服务
-
终于发现了篇不错的Mysql开发的文章 曾以为Windows版本的MySQL存在不能使用UDF的BUG诸提交了一个bug报告。不过 似乎发现是我搞错了,MySQL的技术支持人员给了非常完美的解答,同大家分享 一下。下边是原文回复 :) Sorry this isn't a bug. Below I pasted a sample I did sometime ago for another use
-
--指数化处理 热度*(π-1.8),然后四舍五入后分段 分段规则:【<=50(1/段),>50&<=100(10/段),>100&<=1000(30/段),>1000&<=5000(100/段),>5000(1000/段)】向上取段 结果在50以下的 ,每1为一个段 结果在50-100之间的,每10为一个段, 结果在100和1000之间的,每30为一个段 结果在1000和5000之间,每10
-
1. 简介 MySQL的UDF(User Defined Function)类似于一种API, 用户根据一定的规范用C/C++(或采用C调用规范的语言)编写一组函数(UDF),然后编译成动态链接库,通过CREATE FUNCTION和DROP FUNCTION语句来加载和卸载UDF。UDF被加载后可以像调用MySQL的内置函数一样来调用它,并且服务器在启动时会自动加载原来存在的UDF。 2. 特性
-
最开始spark版本为2.4.3,因业务需要升级为3.1.0,版本升级时踩了几个坑,将这些错误记录下来,供大家参考 1.udf返回类型问题 spark2.4.3版本中需要我们指定该方法的返回类型,但正因为这个, 导致在Spark3中报错 def udfGenPartitionWindow(features: Array[FeatureInfo]): UserDefinedFunction = {
-
create database testdb; 自定义UDF 1.把程序打包放到目标机器上:hiveserver(hive使用端) 2.进入hive客户端,添加jar包 hive>add jar /usr/jar/hivetest.jar 3.创建临时函数 hive>create temporary function add_example as 'hive.udf.Add'; 4.查询HQL语句
-
第8章 函数 8.1 系统内置函数 (1) 查看系统自带的函数 hive> show functions; (2) 显示自带的函数的用法 hive> desc function upper; (3) 详细显示自带的函数的用法 hive> desc function extended upper; 8.2 常用内置函数 8.2.1 空字段赋值 (1) 函数说明 NVL:给值为 NULL 的数据
-
--指数化处理 热度*(π-1.8),然后四舍五入后分段 分段规则:【<=50(1/段),>50&<=100(10/段),>100&<=1000(30/段),>1000&<=5000(100/段),>5000(1000/段)】向上取段 结果在50以下的 ,每1为一个段 结果在50-100之间的,每10为一个段, 结果在100和1000之间的,每30为一个段 结果在1000和5000之间,每10
-
我们以气温统计和词频统计为例,讲解以下三种用户自定义函数。 用户自定义函数 什么时候需要用户自定义函数呢?和其它语言一样,当你希望简化程序结构或者需要重用程序代码时,函数就是你不二选择。 Pig的用户自定义函数可以用Java编写,但是也可以用Python或Javascript编写。我们接下来以Java为例。 自定义过滤函数 我们仍然以先前的代码为例: records = load 'hdfs://
-
一.定义schema的三种方法 //1.编程法(复杂不易维护) val schema = StructType( List( StructField("id",StringType,true), StructField("type",StringType,true), StructField("loation",StringType(List( StructField("lititude",Dou
-
UDF 基于 Spring Boot / Spring Cloud 的基础项目、脚手架,主要用于学习和实践 按照 Spring Boot 的思想,将各个不同的功能按照 starter 的形式拆分开来,做到灵活组合。 项目包说明 udf-starter udf-start-core : 核心包,包含统一异常处理,标准json输出,在线api文档,线程池配置,xss处理,等 udf-starter-c
-
format-udf Bash script to format a block device (hard drive or Flash drive) in UDF. The output is a drive that can be used for reading/writing across multiple operating system families: Windows, macOS
-
可运行和可调用 如果你在Runnable或Callable中包含你的逻辑,就可以将这些类包装在他们的Sleuth代表中。 Runnable的示例: Runnable runnable = new Runnable() { @Override public void run() { // do some work } @Override public String toString()
-
Jinja2 提供了一些代码来继承到其它工具,诸如框架、 Babel 库或你偏好的编辑器 的奇特的代码高亮。这里是包含的这些的简要介绍。 帮助继承的文件在 这里 可 用。 Babel 集成 Jinja 提供了用 Babel 抽取器从模板中抽取 gettext 消息的支持,抽取器的接入点 名为 jinja2.ext.babel_extract 。 Babel 支持的被作为 i18n 扩展 的 一部分
-
Jinja2 提供了一些代码来继承到其它工具,诸如框架、 Babel 库或你偏好的编辑器 的奇特的代码高亮。这里是包含的这些的简要介绍。 帮助继承的文件在 这里 可 用。 Babel 集成 Jinja 提供了用 Babel 抽取器从模板中抽取 gettext 消息的支持,抽取器的接入点 名为 jinja2.ext.babel_extract 。 Babel 支持的被作为 i18n 扩展 的 一部分
-
我是spring集成和缓存新手,想知道如何将从出站网关接收到的对象添加到缓存中。无法确定所需的配置。 从以下配置,我从rest api收到的对象正在被记录: INFO:com.domain.IpAddress@74589991 我计划使用ehcache/caffiene,任何提示都会有帮助。 编辑2: 现在,我按照建议更改了出站网关: 并将ehache配置定义如下: 在我的服务类中,定义了可缓存的