
斯帕克日食中的斯卡拉插件问题

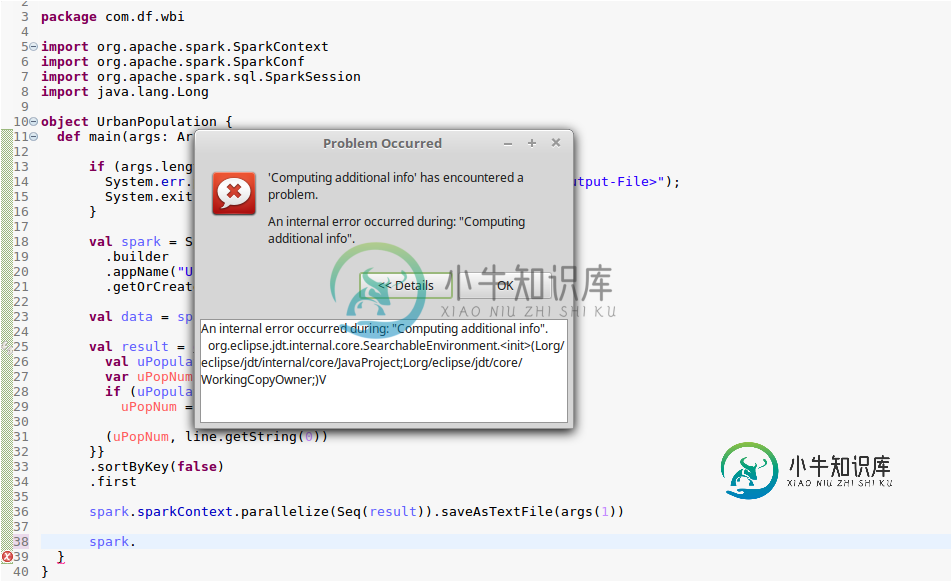
在计算附加信息时发生内部错误。org.eclipse.jdt.internal.core.SearchableEnvironment.(Lorg/eclipse/jdt/内部/核心/JavaProject; Lorg/eclipse/jdt/核心/WorkingCopyOwner;)
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import java.lang.Long
object UrbanPopulation {
def main(args: Array[String]) {
val spark = SparkSession
.builder
.appName("UrbanPopulation")
.getOrCreate()
val data = spark.read.csv(args(0)).rdd
val result = data.map { line => {
val uPopulation = line.getString(10).replaceAll(",", "")
var uPopNum = 0L
if (uPopulation.length() > 0)
uPopNum = Long.parseLong(uPopulation)
(uPopNum, line.getString(0))
}}.sortByKey(false).first
spark.sparkContext.parallelize(Seq(result)).saveAsTextFile(args(1))
spark.stop
}
}
[![enter image description here][1]][1]
[1]: https://i.stack.imgur.com/aTGbp.png
共有1个答案

这看起来像Eclipse bug 546156,它说Scala的代码完成在Eclipse 2019-03中由于Eclipe JDT中的不兼容变化而中断。
该错误在计划于2019年4月19日上市的Eclipse 2019-06(2019-06M1)的第一个里程碑版本中被标记为已修复。
-
我在eclipse中将scala项目转换为使用Maven(只需右键单击project并配置Maven build),这就创建了pom。xml,添加了正确的依赖项,它从maven存储库中提取了所需的JAR,但每当我尝试编译时,我都看不到在target\classes文件夹中生成类文件。然而,我在target\classes文件夹下的相应目录中看到了scala文件的实际源代码。我不确定它为什么要复制t
-
我有一个用斯卡拉写的UDF,我希望能够通过Pyspark会话调用它。UDF 采用两个参数:字符串列值和第二个字符串参数。我已经能够成功地调用UDF,如果它只需要一个参数(列值)。如果需要多个参数,我很难调用UDF。以下是到目前为止我在斯卡拉和Pyspark中能够做的事情: Scala UDF: 在Scala中使用它时,我已经能够注册和使用这个UDF: Scala主类: 以上工作成功。下面是Pysp
-
我正在尝试使用ScalaTest和ScalaCheck进行基于属性的测试。我的测试概述如下: 现在我看到的是,如果我一遍又一遍地运行PropSpec1中的测试,有时第二个测试会通过,但大多数时候会失败。现在,如果0没有被b测试,那么很明显它会通过,但我认为这是它会一直尝试的事情之一。重复运行sbt clean test时,我看到了相同的行为;有时两项测试都通过了。 这对于基于属性的测试是正常的吗,
-
请看下面的代码,让我知道我哪里做错了? 使用: DSE版本-5.1.0 172.31.16.45:9042连接到测试群集。[cqlsh 5.0.1|Cassandra3.10.0.1652|DSE 5.1.0|CQL规范3.4.4|本地协议v4]使用HELP寻求帮助。 谢谢 斯卡拉 斯卡拉 斯卡拉 我在这里什么都得不到?甚至没有错误。
-
我想用scala中的jackson反序列化json json_结构: {“type”:“struct”,“fields”:[{“name”:“code_role”,“type”:“string”,“nullable”:true,“metadata”:{“HIVE_type_string”:“string”},{“name”:“libelle_role”,“type”:“string”,“nulla
-
基本上,我在cassandra上运行两个期货查询,然后我需要做一些计算并返回值(值的平均值)。 这是我的代码: 那么问题出在哪里呢? skus.foreach 在 ListBuffer 中追加结果值。由于一切都是异步的,当我尝试在我的主数据库中获取结果时,我得到了一个错误,说我不能被零除。 事实上,由于我的Sku.findSkusByProduct返回一个Future,当我尝试计算平均值时,卷是空