
if(A | B)总是比if(A | B)快吗?

我正在读费多尔·皮库斯的这本书,他有一些非常非常有趣的例子,对我来说是一个惊喜。
特别是这个基准抓住了我,唯一的区别是,在其中一个基准中,我们在if中使用||,在另一个基准中,我们使用|.
void BM_misspredict(benchmark::State& state)
{
std::srand(1);
const unsigned int N = 10000;;
std::vector<unsigned long> v1(N), v2(N);
std::vector<int> c1(N), c2(N);
for (int i = 0; i < N; ++i)
{
v1[i] = rand();
v2[i] = rand();
c1[i] = rand() & 0x1;
c2[i] = !c1[i];
}
unsigned long* p1 = v1.data();
unsigned long* p2 = v2.data();
int* b1 = c1.data();
int* b2 = c2.data();
for (auto _ : state)
{
unsigned long a1 = 0, a2 = 0;
for (size_t i = 0; i < N; ++i)
{
if (b1[i] || b2[i]) // Only difference
{
a1 += p1[i];
}
else
{
a2 *= p2[i];
}
}
benchmark::DoNotOptimize(a1);
benchmark::DoNotOptimize(a2);
benchmark::ClobberMemory();
}
state.SetItemsProcessed(state.iterations());
}
void BM_predict(benchmark::State& state)
{
std::srand(1);
const unsigned int N = 10000;;
std::vector<unsigned long> v1(N), v2(N);
std::vector<int> c1(N), c2(N);
for (int i = 0; i < N; ++i)
{
v1[i] = rand();
v2[i] = rand();
c1[i] = rand() & 0x1;
c2[i] = !c1[i];
}
unsigned long* p1 = v1.data();
unsigned long* p2 = v2.data();
int* b1 = c1.data();
int* b2 = c2.data();
for (auto _ : state)
{
unsigned long a1 = 0, a2 = 0;
for (size_t i = 0; i < N; ++i)
{
if (b1[i] | b2[i]) // Only difference
{
a1 += p1[i];
}
else
{
a2 *= p2[i];
}
}
benchmark::DoNotOptimize(a1);
benchmark::DoNotOptimize(a2);
benchmark::ClobberMemory();
}
state.SetItemsProcessed(state.iterations());
}
我不会详细介绍书中解释的为什么后者更快的所有细节,但我的想法是,在较慢的版本和|(按位或)版本中,硬件分支预测器有两次错误预测的机会。请参见下面的基准测试结果。
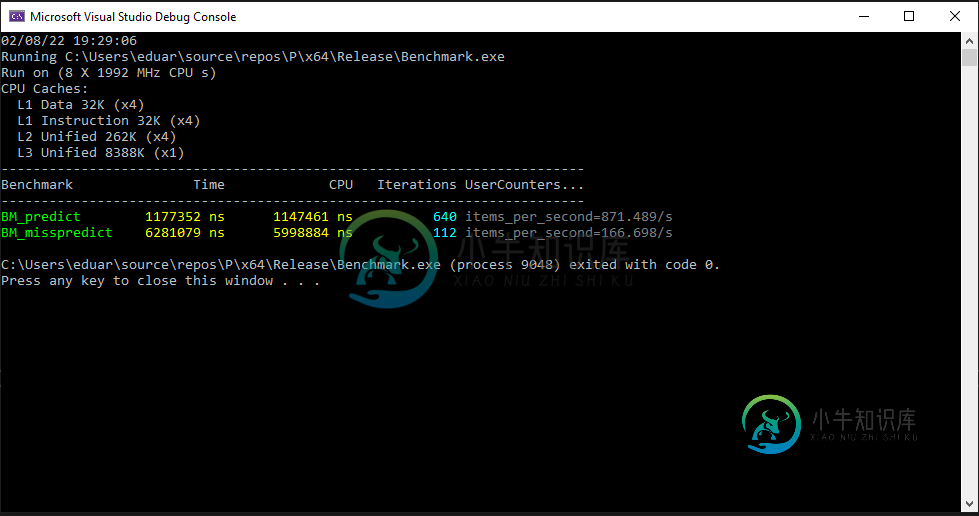
所以问题是为什么我们不在分支中总是使用|而不是| |?
共有3个答案

如果评估A是快的,B是慢的,并且当短路发生时(A返回true),那么If(A | | B)将避免If(A | B)不会出现的慢路径。
如果计算A几乎总是给出相同的结果,那么处理器的分支预测可能会给出If(A | | B)性能优于If(A | B),即使B速度很快。
正如其他人所提到的,在某些情况下,短路是强制性的:如果已知A评估为false,则只希望执行B:
if (p == NULL || test(*p)) { ... } // null pointer would crash on *p
if (should_skip() || try_update()) { ... } // active side effects

按位or是对应于单个ALU指令的无分支算术运算符。逻辑or被定义为暗示快捷方式求值,它涉及(代价高昂的)条件分支。当操作数的求值有副作用时,这两种方法的效果可能不同。
在两个布尔变量的情况下,聪明的编译器可能会计算逻辑-或按位-或,或使用条件移动,但谁知道呢...

if(A|B)总是比if(A||B)快吗?
不,if(A | B)并不总是比if(A | B)快。
考虑一个代码< > < < /代码>是真的,并且<代码> b>代码>表达式是一个非常昂贵的操作。不做手术可以节省费用。
所以问题是为什么我们不在分支中总是使用|而不是| |?
除了逻辑or更有效的情况外,效率并不是唯一的问题。通常存在具有先决条件的操作,并且存在左手操作的结果指示右手操作是否满足先决条件的情况。在这种情况下,我们必须使用逻辑运算符。
if (b1[i]) // maybe this exists somewhere in the program
b2 = nullptr;
if(b1[i] || b2[i]) // OK
if(b1[i] | b2[i]) // NOT OK; indirection through null pointer
当优化html" target="_blank">程序无法用位替换逻辑时,这种可能性通常就是问题所在。在if(b1[i]| | b2[i])的例子中,只有在能够证明b2至少在b1[i]!=0。在你的例子中,这种情况可能不存在,但这并不意味着乐观主义者要证明它不存在一定很容易,有时甚至是可能的。
此外,还可以依赖于操作的顺序,例如,如果一个操作数修改另一个操作数读取的值:
if(a || (a = b)) // OK
if(a | (a = b)) // NOT OK; undefined behaviour
此外,还有一些类型可以转换为bool,因此是| |的有效操作数,但不是|的有效运算符:
if(ptr1 || ptr2) // OK
if(ptr1 | ptr2) // NOT OK; no bitwise or for pointers
TL;DR如果我们总是可以使用按位或代替逻辑运算符,那么就不需要逻辑运算符了,它们可能也不会出现在语言中。但是这种替换并不总是可能的,这就是我们使用逻辑运算符的原因,也是优化器有时不能使用更快选项的原因。
-
本文向大家介绍if(a-b <0)和if(a 相关面试题,主要包含被问及if(a-b <0)和if(a 时的应答技巧和注意事项,需要的朋友参考一下 并且可能意味着两个不同的东西。考虑以下代码: 运行时,将仅打印。发生的事情显然是错误的,但是溢出并变为,这是负面的。 话虽如此,请考虑一下数组的长度确实接近。中的代码如下所示: 确实接近,所以(是)可能溢出并变成(即负数)。然后,将 下溢 相减回正数。
-
问题内容: 我尝试了一些代码,使用XOR在Java中交换两个整数而不使用第三个变量。 这是我尝试的两个交换函数: 这段代码产生的输出是这样的: 我很好奇,为什么这样说: 与这个不同吗? 问题答案: 问题是评估的顺序: 参见JLS第15.26.2节 首先,对左操作数求值以产生一个变量。 如果该评估突然完成,则赋值表达式由于相同的原因而突然完成;右边的操作数不会被评估,并且不会发生赋值。 否则,将保存
-
问题内容: 这是我的第一个问题,我开始学习Python。之间有什么区别: 和 在下面的示例中编写时,它显示不同的结果。 和 问题答案: 在中,在将右侧的表达式赋给左侧之前对其求值。因此,它等效于: 在第二个示例中,运行时已更改的值。因此,结果是不同的。
-
我尝试了一些代码在Java中交换两个整数,而不使用第三个变量,即使用XOR。 以下是我尝试的两个交换函数: 该代码产生的输出如下: 我很想知道,为什么会有这样的说法: 和这个不一样?
-
然而,今天我在处理一些代码时,意外地发现以下两个交换给出了不同的结果: 这让我难以置信。有人能给我解释一下这里发生了什么吗?
-
问题内容: 今天,我发现了python语言一个有趣的“功能”,这让我感到非常悲伤。 那个怎么样?我以为两者是等同的!更糟糕的是,这是我调试时遇到的麻烦的代码 WTF!我的代码中包含列表和字典,并且想知道我到底怎么把dict的键附加到列表上而又没有调用.keys()。事实证明,这就是方法。 我认为这两个陈述是等效的。即使忽略这一点,我也可以理解将字符串追加到列表的方式(因为字符串只是字符数组),但是