
Google PubSub和自动伸缩计算引擎实例(Python)

from google.cloud import pubsub_v1
from google.cloud.pubsub_v1.subscriber.message import Message
def handle_message(message: Message):
# do your stuff here (max. 600sec)
message.ack()
return
def receive_messages(project, subscription_name):
subscriber = pubsub_v1.SubscriberClient()
subscription_path = subscriber.subscription_path(project, subscription_name)
flow_control = pubsub_v1.types.FlowControl(max_messages=5)
subscription = subscriber.subscribe(subscription_path, flow_control=flow_control)
future = subscription.open(handle_message)
# Blocks the thread while messages are coming in through the stream. Any
# exceptions that crop up on the thread will be set on the future.
# The subscriber is non-blocking, so we must keep the main thread from
# exiting to allow it to process messages in the background.
try:
future.result()
except Exception as e:
# do some logging
raise
因为我正在处理这么多PubSub消息,所以我正在为计算引擎创建一个模板,该模板以以下两种方式中的任何一种方式使用自动缩放:
gcloud compute instance-groups managed create my-worker-group \
--zone=europe-west3-a \
--template=my-worker-template \
--size=0
gcloud beta compute instance-groups managed set-autoscaling my-worker-group \
--zone=europe-west3-a \
--max-num-replicas=50 \
--min-num-replicas=0 \
--target-cpu-utilization=0.4
gcloud beta compute instance-groups managed set-autoscaling my-worker-group \
--zone=europe-west3-a \
--max-num-replicas=50 \
--min-num-replicas=0 \
--update-stackdriver-metric=pubsub.googleapis.com/subscription/num_undelivered_messages \
--stackdriver-metric-filter="resource.type = pubsub_subscription AND resource.label.subscription_id = my-pubsub-subscription" \
--stackdriver-metric-single-instance-assignment=10
到目前为止,一切都很好。选项一可扩展到大约8个实例,而第二个选项将启动最大数量的实例。现在我发现有些奇怪的事情会发生,这就是我在这里发帖的原因。也许你能帮我?!
消息重复:每个实例中的PubSub服务(compute engine中docker容器内的Python脚本)似乎在某种程度上像缓冲区一样读取一批消息(~10),并将它们交给我的代码。看起来所有同时旋转的实例都将读取所有相同的消息(2.000条中的前10条),并开始处理相同的内容。在我的日志中,我看到大多数消息被不同的机器处理了3次。我希望PubSub知道是否某个用户缓冲了10条消息,这样另一个用户将缓冲10条不同的消息,而不是相同的消息。
确认截止日期:由于缓冲区的原因,进入缓冲区末尾的消息(假设消息8或9)必须在缓冲区中等待,直到前面的消息(消息1到7)被处理完毕。等待时间加上它自己的处理时间的总和可能会达到600sec的超时。
负载平衡:由于每台机器缓冲了如此多的消息,负载只被几个实例消耗,而其他实例则完全空闲。这种情况发生在使用PubSub stackdriver度量的伸缩选项二中。
人们告诉我,我需要使用Cloud SQL或其他一些东西来实现手动同步服务,其中每个实例都指示它在哪个消息上工作,这样其他实例就不会启动相同的服务。但我觉得这不可能是真的--因为那样我就不明白PubSub是怎么回事了。

更新:我找到了Gregor Hohpe的一个很好的解释,他是2015年《企业集成模式》一书的合著者。实际上我的观察是错误的,但观察到的副作用是真实的。
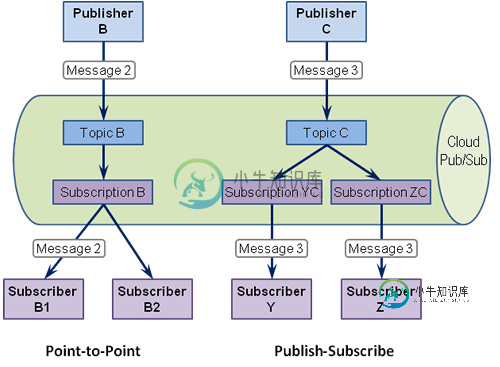
我观察到的副作用是关于每个订阅者(他们订阅了相同的订阅,点对点==竞争消费者)中的消息缓冲和消息流控制。Python客户机库的当前版本包装了PubSub REST API(和RPC)。如果使用该包装,则在以下方面没有控件:
- 在一个VM上启动多少个容器;如果CPU尚未充分利用,则可能启动多个容器
- 一次从订阅中提取多少消息(缓冲);完全无法控制
- 容器内部启动多少线程,用于处理拉出的消息;如果值低于固定值,flow_control(max_messages)将不起作用。
我们观察到的副作用是:
-
null
-
null
共有1个答案

我认为你可以用两种方法来处理这个问题。
1)不是直接推到工作进程,而是推到负载平衡器。
或
-
问题内容: 使用flexbox时遇到问题。 我正在使用容器,因此我的内部项目实际上可以放在多列中。 问题是浏览器仍将容器的宽度计算 为内部项目宽度的总和 ! 我的容器块应具有较小的宽度(基于内容大小),但实际上很大。 无论如何,使用列而不是行时以这种方式计算容器的宽度也是非常不自然的。 看看我的代码中的绿色块。它具有巨大的优势,但事实并非如此。另外,当您从容器中取出物品时,它会变小。 我期望容器的
-
我在GCE上使用麋鹿堆叠。一切正常。但后来我安装了NGINX,后来卸载了它。之后,Kibana在卸载NGINX后无法启动。 Elasticsearch版本:2.4.5 Kibana版本:4.6 KibanaSTDOUT日志是: {“类型”:“日志”,“时间戳”:“2017-06-06T08:13:06Z”,“标签”:[“状态”,“插件:kibana@1.0.0“,“信息”],“pid”:364,“
-
伸缩是对该应用所启动的pods数量进行一个控制。 同样进入应用的详情页页,在右上角找到“伸缩”按钮并点开。 在弹出来的对话框中选择启动的POD数量,如下图: 提交之后若数量大于之前的数量,则会启动缺少的POD数量,若小于之前的值,将会逐步减少应用的POD。 目前给的最大值是8个pod,资源可使用的内存是16G,若您的应用超过我们所设定的最大值。想办法优化吧,64核128G内存都不够用,这种级别的应
-
有没有一种方法可以暂停Dataproc群集,这样当我不积极运行火花外壳或火花提交作业时就不会收到账单?此链接处的群集管理说明:https://cloud.google.com/sdk/gcloud/reference/beta/dataproc/clusters/ 仅演示如何销毁群集,但我安装了spark cassandra连接器API。这是我创建每次都需要安装的映像的唯一选择吗?
-
本文向大家介绍微服务领域Spring Boot自动伸缩的实现方法,包括了微服务领域Spring Boot自动伸缩的实现方法的使用技巧和注意事项,需要的朋友参考一下 前言 自动伸缩是每个人都想要的,尤其是在微服务领域。让我们看看如何在基于Spring Boot的应用程序中实现。 我们决定使用Kubernetes、Pivotal Cloud Foundry或HashiCorp's Nomad等工具的一