
尝试使用Python和Selenium迭代滚动和刮擦网页

我最近问了一个问题(这里引用:Python Web Scring(Beautiful Soup、Selenium和PhantomJS):只刮整页的一部分),这有助于确定我在滚动时动态更新的页面上刮所有内容时遇到的问题。然而,我仍然无法使用selenium来使用代码指向正确的元素,并迭代地向下滚动页面。我还发现,当我手动向下滚动页面时,有一些原始内容在页面加载时消失,而新内容则更新。例如,看下面的图像...
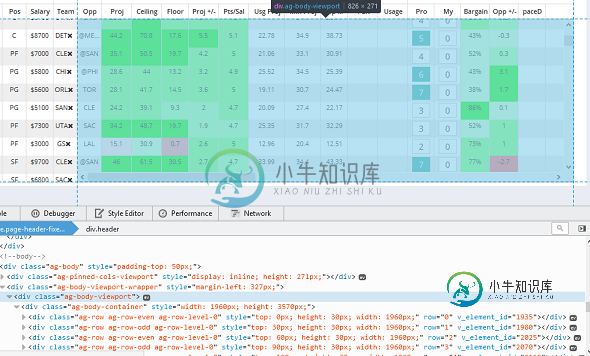
首先,我很难选择正确的元素向下滚动页面,因为我以前从来没有这样做过。我认为我必须使用selenium来定位容器,然后使用“execute_script”函数向下滚动页面,因为这个表嵌入在web页面的主体中。然而,我似乎无法让它发挥作用。
scroll = driver.find_element_by_class_name("ag-body-viewport")
driver.execute_script("arguments[0].scrollIntoView();", scroll)
第二,一旦我有了滚动的能力,我将需要每次向下滚动一点,并迭代地刮。我的意思是,如果您在图像中查看,您将看到一堆“div”标记在
长话短说,我想要的是能够刮图像中提供的所有内容,然后使用selenium向下滚动大约40行,刮下40行,然后向下滚动并刮下40行等等...关于如何让selenium在这个嵌入式容器中滚动以及如何迭代向下滚动以捕获容器中的所有数据的提示。任何额外的帮助都将不胜感激。
共有1个答案

从我在屏幕截图上看到的情况来看,您似乎需要反复滚动到表中的最后一行--带有ag-row类的最后一个元素:
import time
while True:
rows = driver.find_elements_by_css_selector("tr.ag-row")
driver.execute_script("arguments[0].scrollIntoView();", rows[-1])
time.sleep(1)
# TODO: collect the rows
您还需要确定循环退出条件。
-
我试图刮所有可用的赔率为每个游戏在这个网页上找到:https://www.sportsbookreview.com/betting-odds/nfl-football/?date=20170917 我知道网页是动态加载的,所以我尝试插入一个滚动条,希望它在滚动时加载所有可用的赔率,但不幸的是,情况似乎并非如此,因为它只是在继续滚动时删除先前加载的数据。 我尝试过实现有这个问题的类似帖子,(比如这个
-
问题内容: 我已经写了很多刮板,但是我不确定如何处理无限滚动条。如今,大多数网站,Facebook,Pinterest等都有无限滚动条。 问题答案: 您可以使用硒来刮除Twitter或Facebook之类的无限滚动网站。 步骤1:使用pip安装Selenium 第2步:使用下面的代码自动执行无限滚动并提取源代码 步骤3:根据需要打印数据。
-
但是我不想做一个循环,而是想触发一个事件,比如,如果用户手动按下load more Post按钮,新页面被加载,我得到页面的页面源。有什么办法可以做到吗?如有任何帮助,不胜感激。
-
> 取文本文件booktitle.txt,它是书名列表。 然后使用Python/Selenium在网站goodreads.com中搜索该标题。 获取结果的URL并创建一个新的.csv文件,其中列1=书名,列2=站点URL
-
问题内容: 我收到一个元素不可见的错误: 对于运行此代码时的每个find元素行: 页面登录部分的HTML如下所示: 问题答案: Selenium与用户与Web浏览器的交互方式类似。因此,如果您尝试与之交互的html元素不可见,那么最简单的解释是,当您编写硒代码时,您不会像普通用户那样与网页进行交互。 最后,这与网页的html无关,与DOM和元素的hidden属性无关。我建议您下载Firebug或其
-
问题内容: 我正在抓取此网页中的用户名,该用户名在滚动后会加载用户 转到页面的网址:“ http://www.quora.com/Kevin- Rose/followers ” 我知道页面上的用户数量(在这种情况下,编号为43812)如何滚动页面,直到所有用户加载完毕?我在互联网上搜索了相同的代码,到处都可以找到几乎相同的代码行: driver.execute_script(“ window.sc