
AWS Athena从GLUE Crawler从S3输入csv创建的表返回零记录

我已经阅读了以下问题的答案:AWS Athena从S3的GLUE Crawler输入csv创建的表返回零记录
问题https://aws.amazon.com/de/premiumsupport/knowled-center/athena-empty-results/
按照建议
-
null
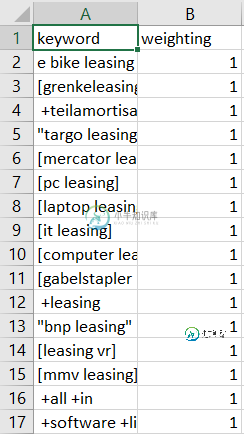

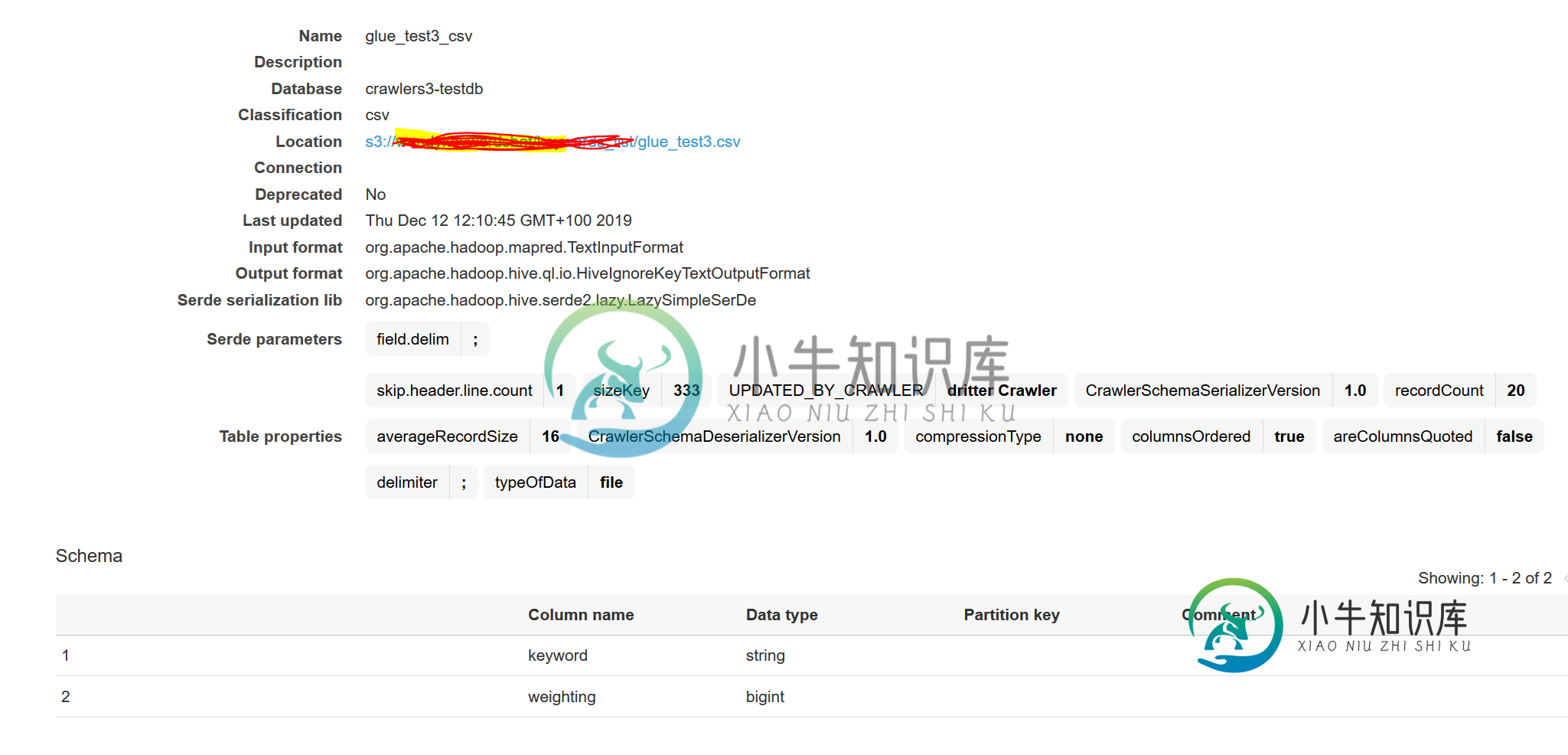
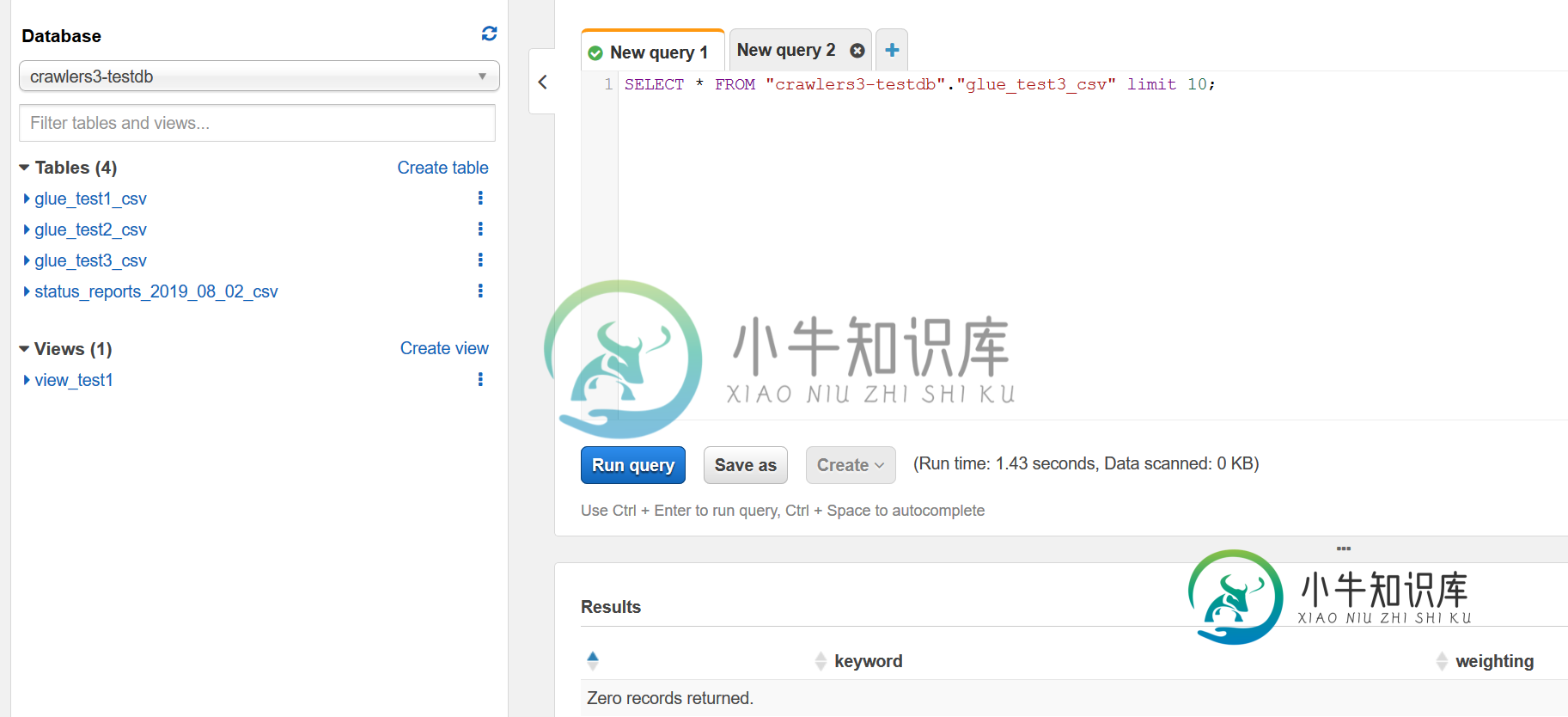
有人知道为什么胶水爬行器不能转换数据吗?
谢了!
共有1个答案

查看生成的表名后,在传递给Glue Crawler的文件夹路径中似乎有多个具有不同架构的文件。如果您希望在Athena中查询这些表,那么您必须将这些具有不同模式的CSV文件放在不同的文件夹中。
虽然您将文件夹路径传递给了粘合爬虫,但它会为Athena表创建具有完整文件路径的表。您可以通过运行show create table
来验证这一点。
-
问题内容: 我已经阅读了从平面csv创建嵌套JSON的内容,但对我而言没有帮助。 我有一个很大的电子表格,它是由Google文档创建的,包含11行和74列(某些列未占用)。 我在Google云端硬盘上创建了一个示例。导出为a时,它看起来像这样: 现在,我想要一个结构,如下所示: 以此类推。 我的理论方法是逐行遍历文件(这是第一个问题:现在每一行等于一行,但有时是几行,因此我需要计算逗号?)。每行等
-
问题内容: 我目前有一种方法可以检查3x3网格中中心项周围的内容,如果8个相邻位置中的内容包含我要检查的内容,我想在长度为7的数组上将该正方形标记为1。 为此,我需要在我的方法中创建并返回一个数组,这可能吗? 问题答案: 不知道是什么问题。你是这个意思?
-
我有一个返回dict对象的函数,我想利用pandas/numpy在数据帧的每一行上为该函数执行列操作/向量化的能力。函数的输入在dataframe中指定,我希望函数的输出成为现有dataframe上的新列。下面是一个例子。 期望输出: 我读了这个答案,大部分内容都是这样的,但是当函数返回一个dict对象,其中包含所需的列名作为dict中的键时,我不太明白该怎么做。
-
我尝试使用ffmpeg转换一个带有AVC编码的小(2帧)MP4文件,如下所示: ffmpeg-y-noautorotate-loglevel 99-i输入文件。mp4-线程0-map_chapters-1-写入tmcd 0-元数据位置=-max_muxing_queue_size 2000-f mpegts-过滤器复杂“[0:v:0]yadif=deint=Intersected,scale=16
-
问题内容: 我正在尝试从csv文件创建字典。csv文件的第一列包含唯一键,第二列包含值。csv文件的每一行代表字典中的唯一键,值对。我尝试使用类,但是我只能弄清楚如何为每一行生成一个新的字典。我要一部字典。这是我尝试使用的代码: 当我运行上面的代码时,我得到一个。如何从csv文件创建一个字典? 问题答案: 我相信你正在寻找的语法如下: 或者,对于,你需要: