
无法正确识别车牌(蟒蛇、开放电脑、泰瑟拉克特)

我试图识别车牌,但遇到错误,如错误/未读取字符
下面是每个步骤的可视化:
从颜色阈值化变形关闭获得蒙版

以绿色突出显示的车牌轮廓过滤器

将板轮廓粘贴到空白遮罩上

Tesseract OCR的预期结果
BP 1309 GD
但我得到的结果是
BP 1309 6D
我尝试将轮廓切片为3切片


是的,它是有效的,但是如果我将差异图像插入到这个方法中,一些图像就无法识别,例如这个

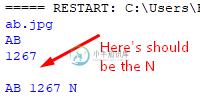
字母N无法识别,但如果使用第一种方法,它的工作原理
这是密码
import numpy as np
import pytesseract
import cv2
import os
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files\Tesseract-OCR\tesseract.exe"
image_path = "data"
for nama_file in sorted(os.listdir(image_path)):
print(nama_file)
# Load image, create blank mask, convert to HSV, define thresholds, color threshold
I = cv2.imread(os.path.join(image_path, nama_file))
dim = (500, 120)
I = cv2.resize(I, dim, interpolation = cv2.INTER_AREA)
(thresh, image) = cv2.threshold(I, 127, 255, cv2.THRESH_BINARY)
result = np.zeros(image.shape, dtype=np.uint8)
result = 255 - result
hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
lower = np.array([0,0,0])
upper = np.array([179,100,130])
mask = cv2.inRange(hsv, lower, upper)
slices = []
slices.append(result.copy())
slices.append(result.copy())
slices.append(result.copy())
i = 0
j = 0
xs = []
# Perform morph close and merge for 3-channel ROI extraction
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3,3))
close = cv2.morphologyEx(mask, cv2.MORPH_CLOSE, kernel, iterations=1)
extract = cv2.merge([close,close,close])
# Find contours, filter using contour area, and extract using Numpy slicing
cnts = cv2.findContours(close, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
boundingBoxes = [cv2.boundingRect(c) for c in cnts]
(cnts, boundingBoxes) = zip(*sorted(zip(cnts, boundingBoxes),
key=lambda b:b[1][0], reverse=False))
for c in cnts:
x,y,w,h = cv2.boundingRect(c)
area = w * h
ras = format(w / h, '.2f')
if h >= 40 and h <= 70 and w >= 10 and w <= 65 and float(ras) <= 1.3:
cv2.rectangle(I, (x, y), (x + w, y + h), (36,255,12), 3)
result[y:y+h, x:x+w] = extract[y:y+h, x:x+w]
# Slice
xs.append(x)
if i > 0:
if (xs[i] - xs[i-1]) > 63:
j = j+1
i = i + 1
slices[j][y:y+h, x:x+w] = extract[y:y+h, x:x+w]
# Split throw into Pytesseract
j=0
for s in slices:
cv2.imshow('result', s)
cv2.waitKey()
if j != 1 :
data = pytesseract.image_to_string(s, lang='eng',config='--psm 6 _char_whitelist=ABCDEFGHIJKLMNOPQRTUVWXYZ')
else :
data = pytesseract.image_to_string(s, lang='eng',config='--psm 6 _char_whitelist=1234567890')
print(data)
# Block throw into Pytesseract
data = pytesseract.image_to_string(result, lang='eng',config='--psm 6')
print(data)
cv2.imshow('image', I)
cv2.imshow('close', close)
cv2.imshow('extract', extract)
cv2.imshow('result', result)
cv2.waitKey()
也许有人知道为什么会发生这种情况,该怎么办?
预先感谢
共有2个答案

我可以通过在ubuntu shell中使用一个简单的命令立即解码板。但为了做到这一点,您必须将tesseract从版本4升级到5。
车牌
tesseract a364k.png stdout -l eng --oem 3 --psm 7 -c tessedit_char_whitelist="ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789 "
BP 1309 GD
在您的代码中,您可以将其添加到配置
-l eng --oem 3 --psm 7 -c tessedit_char_whitelist="ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789 "

我尝试了很多事情,找到了某种解决方案:
应用扩张形态学操作使字母变细:
# Split throw into Pytesseract
j=0
for s in slices:
cv2.imshow('result', s)
cv2.waitKey(1)
if j != 1:
data = pytesseract.image_to_string(s, config="-c tessedit"
"_char_whitelist=ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890"
" --psm 6"
" ")
if data=='':
s = cv2.dilate(s, cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (5,5)))
cv2.imshow('cv2.dilate(s)', s)
cv2.waitKey(1)
data = pytesseract.image_to_string(s, config="-c tessedit"
"_char_whitelist=ABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890"
" --psm 6"
" ")
else:
pytesseract.pytesseract.tessedit_char_whitelist = '1234567890'
data = pytesseract.image_to_string(s, lang='eng',config='--psm 6 _char_whitelist=1234567890')
print(data)
这种行为非常奇怪。
有很多抱怨,建议的解决方案不起作用。
请看下面的帖子:宇宙魔方不识别单个字符
至少我学会了如何使用< code>_char_whitelist选项(您需要添加< code>-c tessedit)...
我认为解决方案不够强大(可能是偶然的)。
我认为在当前版本的泰瑟拉克特中没有简单的解决方案。
-
我是一名程序员,但我之前没有使用Python或其任何库的经验,甚至没有OCR/ALPR的整体经验。我有一个脚本,我做的(基本上复制和粘贴其他脚本在整个网络上),我假装用来识别车牌。但事实是我的代码现在非常糟糕。它可以很好地识别图像中的文本,但它很难捕捉车牌。我很少能用它拿到牌照。 因此,我需要一些帮助,说明我应该如何更改代码以使其更好。 在我的代码中,我只需选择一个图像,将其转换为二进制和BW,然
-
我正在从事一个关于识别摩洛哥车牌的项目,看起来像这张图片: 摩洛哥车牌 请问我如何使用OpenCV来切割车牌,而Tesseract来读取中间的数字和阿拉伯字母。 我看了这篇研究论文:https://www.researchgate.net/publication/323808469_Moroccan_License_Plate_recognition_using_a_hybrid_method_a
-
我尝试了镶嵌,结果是:7G285274-AF现在我真的不知道该怎么办,如果有人知道请告诉我 首先,我从汽车图像中检测车牌,然后我必须从车牌中识别字符。这是我的代码:
-
我已经在python中安装和安装了pocketsphinx和sphinxbase包。我还为github获取了语音识别代码,并根据需要更改了数据和模式目录,但当我试图通过“python test.py”运行它时,它仍然无法通过语音进行流式传输。下面是代码: 请告诉我如何执行它。
-
我在Windows 10中使用Python 3.6,并且已经安装了Pytesseract,但我在代码Tessercr中找到了一个代码,顺便说一下,我无法安装。有什么区别?
-
1.1. cirtus_lpr_sdk 1.1.1. SDK接口说明 1.2. android_demo Rokid Plate Recognition SDK and demo project. Author Email cmxnono cmxnono@rokid.com 1.1. cirtus_lpr_sdk Version:1.0 1.1.1. SDK接口说明 初始化 public long