
通过可能增加分区或任务的数量,提高 Spark 数据帧到 RDD 转换的速度

我在尝试将DF转换为RDD时遇到了一个问题。这个过程中的一个阶段总共使用了200个任务,而在此之前的大多数部分使用了更多的任务,我很难理解它为什么使用这个数字,以及我是否需要找到一种方法来提高性能。
该程序使用 Spark 版本 2.1.0,并在我使用 250 个执行器的 Yarn 集群上运行。
这些是将DF转换为RDD的行:
val predictionRdd = selectedPredictions
.withColumn("probabilityOldVector", convertToOldVectorUdf($"probability"))
.select("mid", "probabilityOldVector")
.rdd
这导致了前面提到的200个任务,如以下屏幕截图中的活动阶段所示。
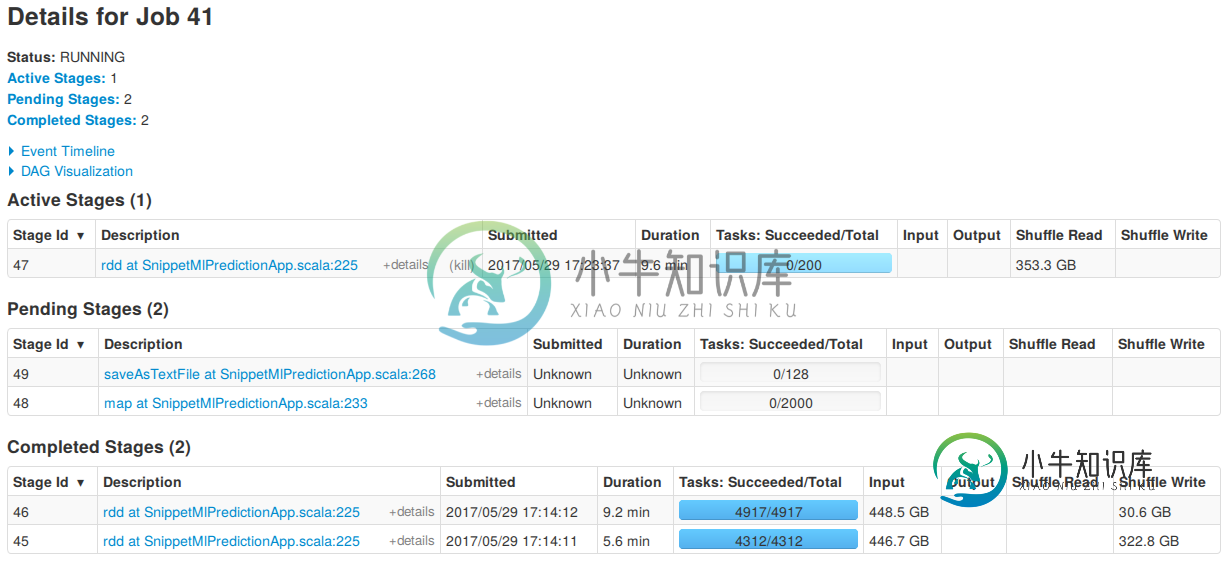
它基本上只是停留在这里,我不知道有多长时间,其他两个完成阶段使用了更多的任务。
我尝试过的一件事是在将其转换为RDD之前执行重新分区:
val predictionRdd = selectedPredictions
.withColumn("probabilityOldVector", convertToOldVectorUdf($"probability"))
.select("mid", "probabilityOldVector")
.repartition(2000)
.rdd
val avgPrehtml" target="_blank">dictions = predictionRdd
.map(row => (row.getAs[String]("mid"), row.getAs[OldVector]("probabilityOldVector")))
.aggregateByKey(new MultivariateOnlineSummarizer)(
(agg, v) => agg.add(v),
(agg1, agg2) => agg1.merge(agg2)
)
.map(p => (p._1, p._2.mean))
假设理想情况下,这将导致执行2000个任务。然而,这有一个(对我来说)意想不到的结果。这张图片(和以前一样)显示了这部分所属的整个作业。有趣的是,它仍然显示了200个任务,并且在将重新分区转换为RDD之前的2000个分区在用于待处理地图阶段的任务数量中是可见的。
对我来说,要提高这部分的速度,我需要增加正在执行的任务的数量,允许它以更少的内存并行运行。
所以我的问题基本上是:
- 我是否至少在某种程度上正确地理解了这种情况,或者问题完全出在别的地方,
- 增加正在执行的任务数量也会提高速度,
- 如何增加此部分的任务(或分区)数量,或者通过什么其他方式可以提高速度?
我对斯巴克还是有点陌生,我在更高的层次上知道自己的方法,但是实际的复杂性仍然让我困惑。
在撰写本文时,我注意到它在大约1.3小时后终于显示出一些进展,因为看似简单。
以下是按执行程序和任务汇总指标的一小部分:
Executor ID Address Task Time Total Tasks Failed Tasks Killed Tasks Succeeded Tasks Shuffle Read Size / Records Shuffle Write Size / Records Shuffle Spill (Memory) Shuffle Spill (Disk)
1 - 1.4 h 1 0 0 1 1810.3 MB / 8527038 2.1 GB / 2745175 5.9 GB 1456.3 MB
10 - 0 ms 0 0 0 0 1808.2 MB / 8515093 0.0 B / 1839668 5.9 GB 1456.7 MB
和
Index ID Attempt Status Locality Level Executor ID / Host Launch Time Duration Scheduler Delay Task Deserialization Time GC Time Result Serialization Time Getting Result Time Peak Execution Memory Shuffle Read Size / Records Write Time Shuffle Write Size / Records Shuffle Spill (Memory) Shuffle Spill (Disk) Errors
0 19454 0 RUNNING PROCESS_LOCAL 197 / worker176.hathi.surfsara.nl 2017/05/29 17:23:37 1.5 h 0 ms 0 ms 3.8 min 0 ms 0 ms 3.1 GB 1809.9 MB / 8525371 0.0 B / 1839667 5.9 GB 1456.0 MB
1 19455 0 SUCCESS PROCESS_LOCAL 85 / worker134.hathi.surfsara.nl 2017/05/29 17:23:37 1.5 h 42 ms 8 s 3.2 min 0 ms 0 ms 6.0 GB 1808.3 MB / 8519686 5 s 2.1 GB / 2742924 5.9 GB 1456.3 MB

以下是其他几张截图,作为链接添加,以免这篇文章太长:
- DAG阶段45
- DAG阶段46
- 整个作业概述
第45阶段和第46阶段在第47阶段之前同时运行。源代码的主要部分可以在GitHub上的这个片段中查看。它加载了一个以前训练过的CrossValidatorModel,该CrossValidatorModel由一个包含五个步骤的管道组成:CharNGram、CountVectorizer、IDF、随机森林分类器和IndexToString。它预测了200个类对最大长度为550个字符的大约5.5亿文本片段的概率。然后将这些预测按每个输入类分组,然后取平均值。
共有1个答案

您可以使用以下命令设置任务数:
val spConfig = (new SparkConf).setMaster("local[*]").setAppName("MoviesRec")
// Spark UI available at port 4040.. check here also
spark = SparkSession.builder().appName("Movies").config(spConfig)
.config("spark.ui.enabled", true)
.config("spark.sql.shuffle.partitions", "100")
在日志中,您将获得如下内容:[阶段9:======================================================================
-
Spark中的任务数由阶段开始时的RDD分区总数决定。例如,当Spark应用程序从HDFS读取数据时,Hadoop RDD的分区方法继承自MapReduce中的,它受HDFS块的大小、的值和压缩方法等的影响。 截图中的任务花了7,7,4秒,我想让它们平衡。另外,阶段被分成3个任务,有什么方法可以指定Spark的分区/任务数吗?
-
我是scala/sark世界的新手,最近开始了一项任务,它读取一些数据,处理数据并将其保存在S3上。我阅读了一些关于stackoverflow的主题/问题,这些主题/问题涉及重分区/合并性能和最佳分区数(如本例)。假设我有正确的分区数,我的问题是,在将rdd转换为数据帧时,对它进行重新分区是个好主意吗?下面是我的代码目前的样子: 这是我打算做的(过滤后重新分区数据): 我的问题是,这样做是个好主意
-
我有一个如下的CSV文件。 我想把这个转化成下面。 基本上,我想在输出数据帧中创建一个名为idx的新列,该列将填充与键=idx,value=“n”后面的行相同的值“n”。
-
我正在查看代码中的一个错误,其中一个数据框被分成了太多的分区(超过700个),当我试图将它们重新分区为48个时,这会导致太多的洗牌操作。我不能在这里使用coalesce(),因为我想在重新分区之前首先拥有更少的分区。 我正在寻找减少分区数量的方法。假设我有一个 spark 数据帧(具有多个列),分为 10 个分区。我需要根据其中一列进行 orderBy 转换。完成此操作后,生成的数据帧是否具有相同
-
有人能解释一下将为Spark Dataframe创建的分区数量吗。 我知道对于RDD,在创建它时,我们可以提到如下分区的数量。 但是对于创建时的Spark数据帧,看起来我们没有像RDD那样指定分区数量的选项。 我认为唯一的可能性是,在创建数据帧后,我们可以使用重新分区API。 有人能告诉我在创建数据帧时,我们是否可以指定分区的数量。
-
我正在尝试将RDD[String]转换为数据框。字符串是逗号分隔的,所以我希望逗号之间的每个值都有一列。为此,我尝试了以下步骤: 但我明白了: 这不是这篇文章的副本(如何将rdd对象转换为火花中的数据帧),因为我要求RDD[字符串]而不是RDD[行]。 而且它也不是火花加载CSV文件作为DataFrame的副本?因为这个问题不是关于将CSV文件读取为DataFrame。