
为什么给spark作业的executor内存参数与线程上分配的内存不匹配?

我有一个关于火花执行器内存的被遗忘已久的问题。我在代码中为火花作业提供了这些参数。
案例1:
object Pickup {
val conf = new SparkConf().setAppName("SPLINTER").set("spark.executor.heartbeatInterval", "120s")
.set("spark.network.timeout", "12000s")
.set("spark.sql.orc.filterPushdown", "true")
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.set("spark.kryoserializer.buffer.max", "512m")
.set("spark.serializer", classOf[org.apache.spark.serializer.KryoSerializer].getName)
.set("spark.html" target="_blank">streaming.stopGracefullyOnShutdown", "true")
.set("spark.yarn.driver.memoryOverhead", "8192")
.set("spark.yarn.executor.memoryOverhead", "8192")
.set("spark.shuffle.service.enabled", "true")
.set("spark.sql.tungsten.enabled", "true")
.set("spark.executor.instances", "4")
.set("spark.executor.memory", "2g")
.set("spark.executor.cores", "5")
.set("spark.files.maxPartitionBytes", "268435468")
.set("spark.sql.shuffle.partitions","20")
...
...
...
}
执行人

这是运行的执行器数量及其内存的样子
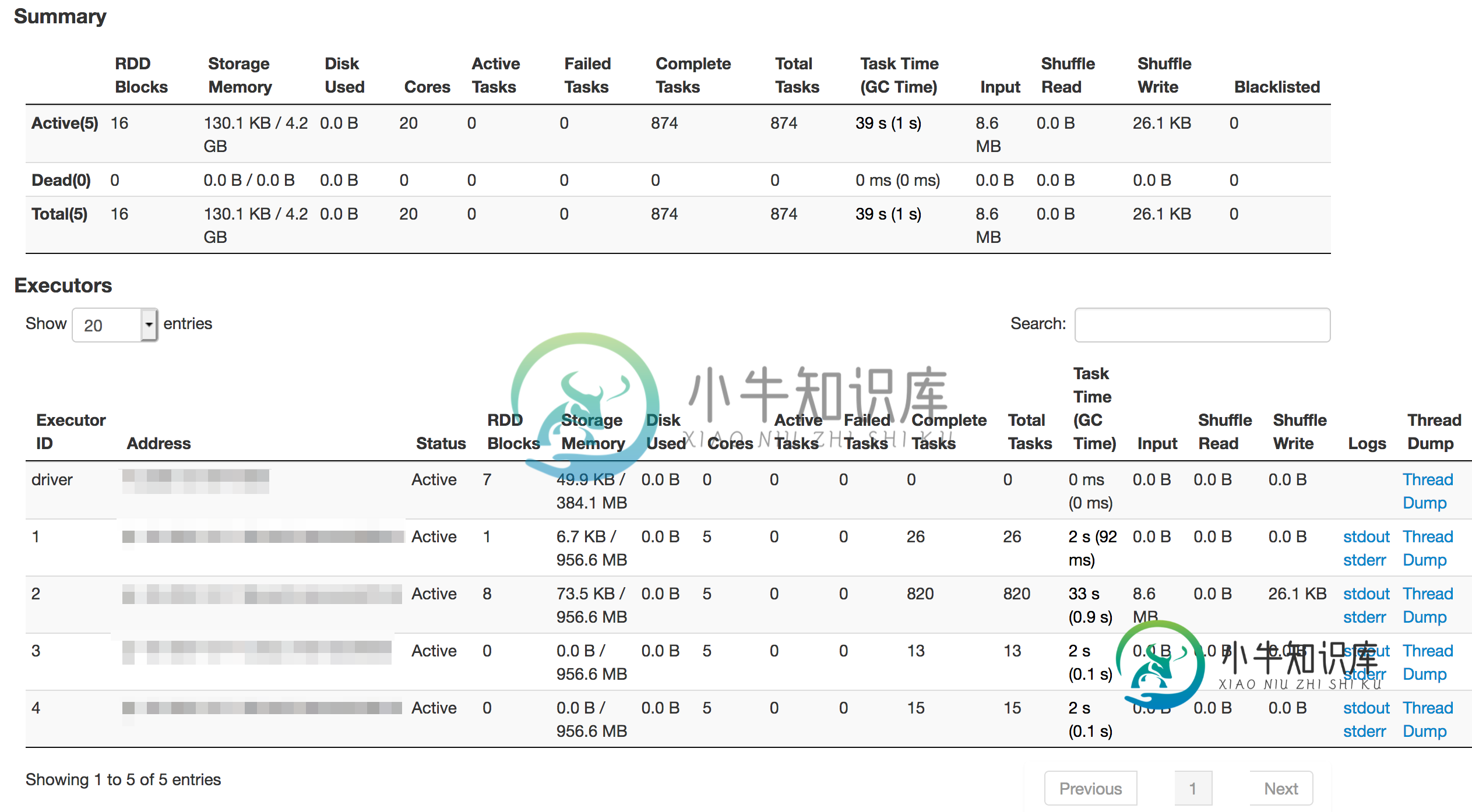
为什么分配的内存是53248MB(52GB)?它是否也与开销内存值相加?即使是这样=
因此,我再次更改了作业中的内存参数,如下所示:
案例2:这次我给了司机

后台的执行者:
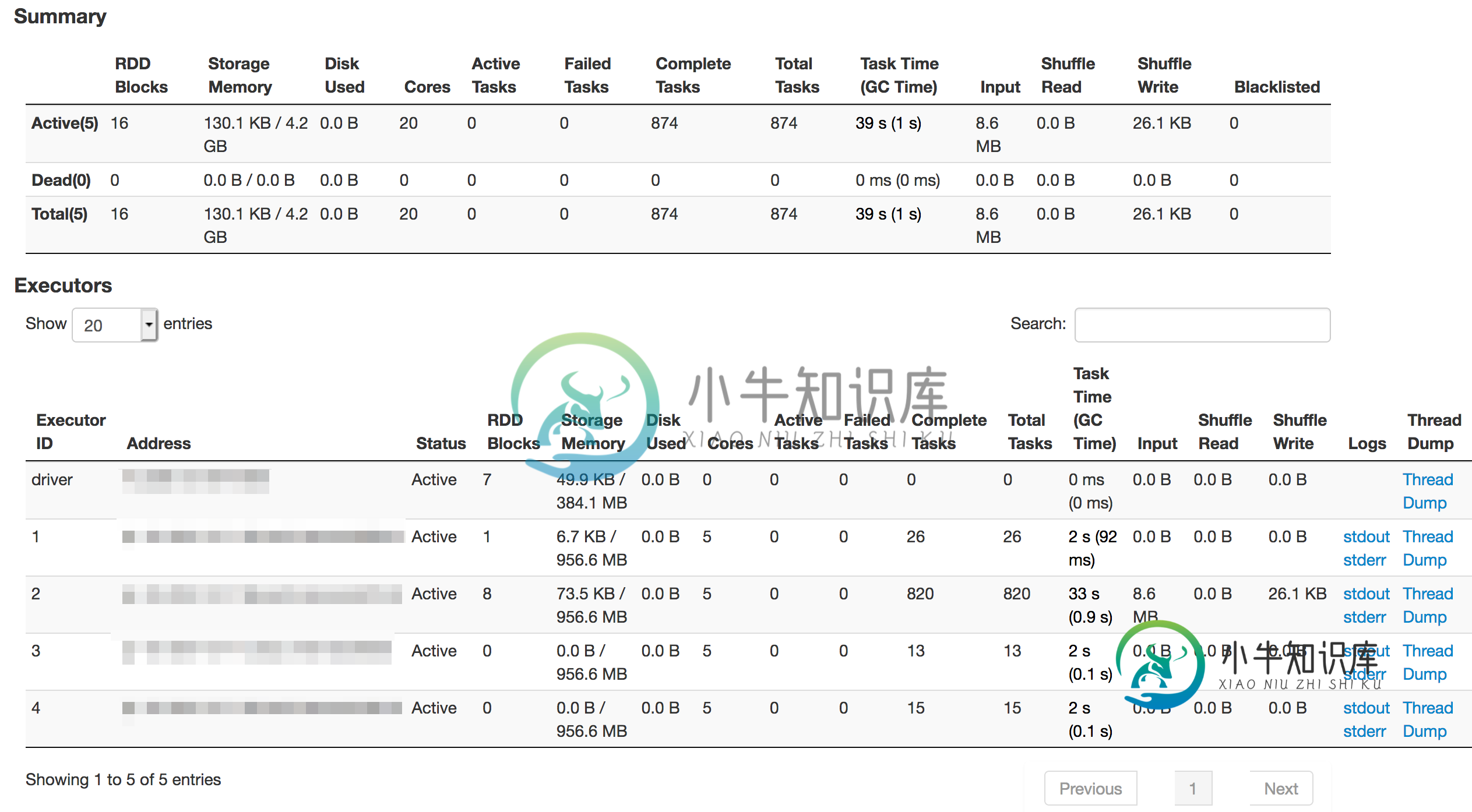
如果添加了所有内存编号,它仍会变为:4 个执行程序 * 每个执行程序 2gb =
火花提交命令:
SPARK_MAJOR_VERSION=2 spark-submit --class com.partition.source.Pickup --master=yarn --conf spark.ui.port=4090 --driver-class-path /home/username/jars/greenplum.jar:/home/username/jars/postgresql-42.1.4.jar:/home/username/ReconTest/inputdir/myjars/hive-jdbc-2.3.5.jar --conf spark.jars=/home/username/jars/greenplum.jar,/home/username/jars/postgresql-42.1.4.jar,/home/username/ReconTest/inputdir/myjars/hive-jdbc-2.3.5.jar --executor-cores 4 --executor-memory 2G --keytab /home/username/username.keytab --principal username@DEVUSR.COM --files /$SPARK_HOME/conf/hive-site.xml,testconnection.properties --name Splinter --conf spark.executor.extraClassPath=/home/username/jars/greenplum.jar splinter_2.11-0.1.jar SSS
我在网上搜索,看看执行器内存在作业中的分布情况。大部分信息是关于如何调整它,而不是解释它是如何分发的。最令人困惑的部分是红色框中标记的工作卡中分配的内存参数中显示的数字。我不明白53248MB(52GB)是如何分配给4个执行器,每个执行器2gb。
我错过了任何链接吗?谁能告诉我为什么这个数字这么大?执行器内存在后台是如何分布的?
共有1个答案

每个执行器的实际内存为:
<code>spark.executor。内存spark.yarn.executor.memory开销
<code>spark.yarn.executor。内存开销(如果未指定)=MAX(384MB,spark.executor.memory的7%)
因此,您有4个执行器~40G。和1个驱动程序(1G 8GB)==
在您的案例#2:~20GB(4个执行器:4*4=16G,1个驱动程序:1 2=3G)中也是如此
-
我有四个问题。假设在spark中有3个worker节点。每个工人节点有3个执行器,每个执行器有3个核心。每个执行器有5 gb内存。(总共6个执行器,27个内核,15GB内存)。如果: > 我有30个数据分区。每个分区的大小为6 GB。最佳情况下,分区的数量必须等于核心的数量,因为每个核心执行一个分区/任务(每个分区执行一个任务)。在这种情况下,由于分区大小大于可用的执行器内存,每个执行器核心将如何
-
5个节点各有4个内核和32GB内存,其中一个节点(节点4)有8个内核和32GB内存。 所以我总共有6个节点-28个核,192GB RAM。(我想使用一半的内存,但要使用所有的内核) 计划在集群上运行5个spark应用程序。 我的spark\u默认值。配置如下: 我想在每个节点上使用16GB max,并通过设置以下配置在每台机器上运行4个工作实例。所以,我希望(4个实例*6个节点=24个)集群上的工
-
问题内容: 我的问题是关于将数据从内核传递到用户空间程序。我想实现一个系统调用“ get_data(size,char * buff,char ** meta_buf)”。在此调用中,buff由用户空间程序分配,并且其长度在size参数中传递。但是,meta_buf是可变长度的缓冲区,已分配(在用户空间程序的vm页面中)并由内核填充。用户空间程序将释放该区域。 (我无法在用户空间中分配数据,因为用
-
如何增加Apache spark executor节点可用的内存? 我有一个2 GB的文件,适合加载到Apache Spark。我目前正在1台机器上运行apache spark,因此驱动程序和执行程序在同一台机器上。这台机器有8 GB内存。 我尝试了这里提到的各种东西,但我仍然得到错误,并没有一个明确的想法,我应该改变设置。 我正在从spark-shell交互地运行我的代码
-
为什么会这样?最后,还有其他类似的功能我应该知道是不允许的。
-
我想了解为什么多次动态分配调用的数据比直接在代码中指定的或通过的单个调用分配的数据使用如此多的内存。 例如,我用C编写了以下两个代码: 测试1.c:int x用malloc分配 我在这里没有使用free来保持简单。当程序等待交互时,我查看另一个终端中的顶级功能,它向我显示了以下内容: test2. c: int x不是动态分配的 顶部显示: 我还编写了第三个代码,其结果与test2相同,我在tes