
了解日期并在R中使用ggplot2绘制直方图

当我试图用ggplot2制作柱状图时,我在理解为什么日期、标签和中断的处理不像我在R中预期的那样有效时遇到了问题。
我正在寻找:
- 我约会频率的柱状图
- 匹配条下居中的勾号
- 日期标签采用
%Y-b格式 - 适当的限制;最小化网格空间边缘和最外层条之间的空白空间
我已经将我的数据上传到pastebin,以使其可复制。我已经创建了几个专栏,因为我不确定这样做的最佳方式:
> dates <- read.csv("http://pastebin.com/raw.php?i=sDzXKFxJ", sep=",", header=T)
> head(dates)
YM Date Year Month
1 2008-Apr 2008-04-01 2008 4
2 2009-Apr 2009-04-01 2009 4
3 2009-Apr 2009-04-01 2009 4
4 2009-Apr 2009-04-01 2009 4
5 2009-Apr 2009-04-01 2009 4
6 2009-Apr 2009-04-01 2009 4
以下是我尝试过的:
library(ggplot2)
library(scales)
dates$converted <- as.Date(dates$Date, format="%Y-%m-%d")
ggplot(dates, aes(x=converted)) + geom_histogram()
+ opts(axis.text.x = theme_text(angle=90))
这就产生了这个图表。不过,我想要%Y-%b格式,因此我四处寻找并尝试了以下方法,基于此,所以:
ggplot(dates, aes(x=converted)) + geom_histogram()
+ scale_x_date(labels=date_format("%Y-%b"),
+ breaks = "1 month")
+ opts(axis.text.x = theme_text(angle=90))
stat_bin: binwidth defaulted to range/30. Use 'binwidth = x' to adjust this.
这给了我这个图表
- 正确的x轴标签格式
- 频率分布已改变形状(Bin宽问题?)
- 滴答的痕迹不会出现在栏杆的中心
- xlims也变了
我在ggplot2文档的scale\u x\u date部分完成了该示例,当我使用相同的x轴数据时,geom\u line()显示为正确断开、标记和居中刻度。我不明白为什么柱状图不同。
我最初认为高登的回答帮助我解决了我的问题,但现在仔细观察后感到困惑。请注意代码后两个答案的结果图之间的差异。
假设两者都是:
library(ggplot2)
library(scales)
dates <- read.csv("http://pastebin.com/raw.php?i=sDzXKFxJ", sep=",", header=T)
根据下面@edgester的回答,我能够做到以下几点:
freqs <- aggregate(dates$Date, by=list(dates$Date), FUN=length)
freqs$names <- as.Date(freqs$Group.1, format="%Y-%m-%d")
ggplot(freqs, aes(x=names, y=x)) + geom_bar(stat="identity") +
scale_x_date(breaks="1 month", labels=date_format("%Y-%b"),
limits=c(as.Date("2008-04-30"),as.Date("2012-04-01"))) +
ylab("Frequency") + xlab("Year and Month") +
theme_bw() + opts(axis.text.x = theme_text(angle=90))
以下是我根据高登的回答所做的尝试:
dates$Date <- as.Date(dates$Date)
ggplot(dates, aes(x=Date)) + geom_histogram(binwidth=30, colour="white") +
scale_x_date(labels = date_format("%Y-%b"),
breaks = seq(min(dates$Date)-5, max(dates$Date)+5, 30),
limits = c(as.Date("2008-05-01"), as.Date("2012-04-01"))) +
ylab("Frequency") + xlab("Year and Month") +
theme_bw() + opts(axis.text.x = theme_text(angle=90))
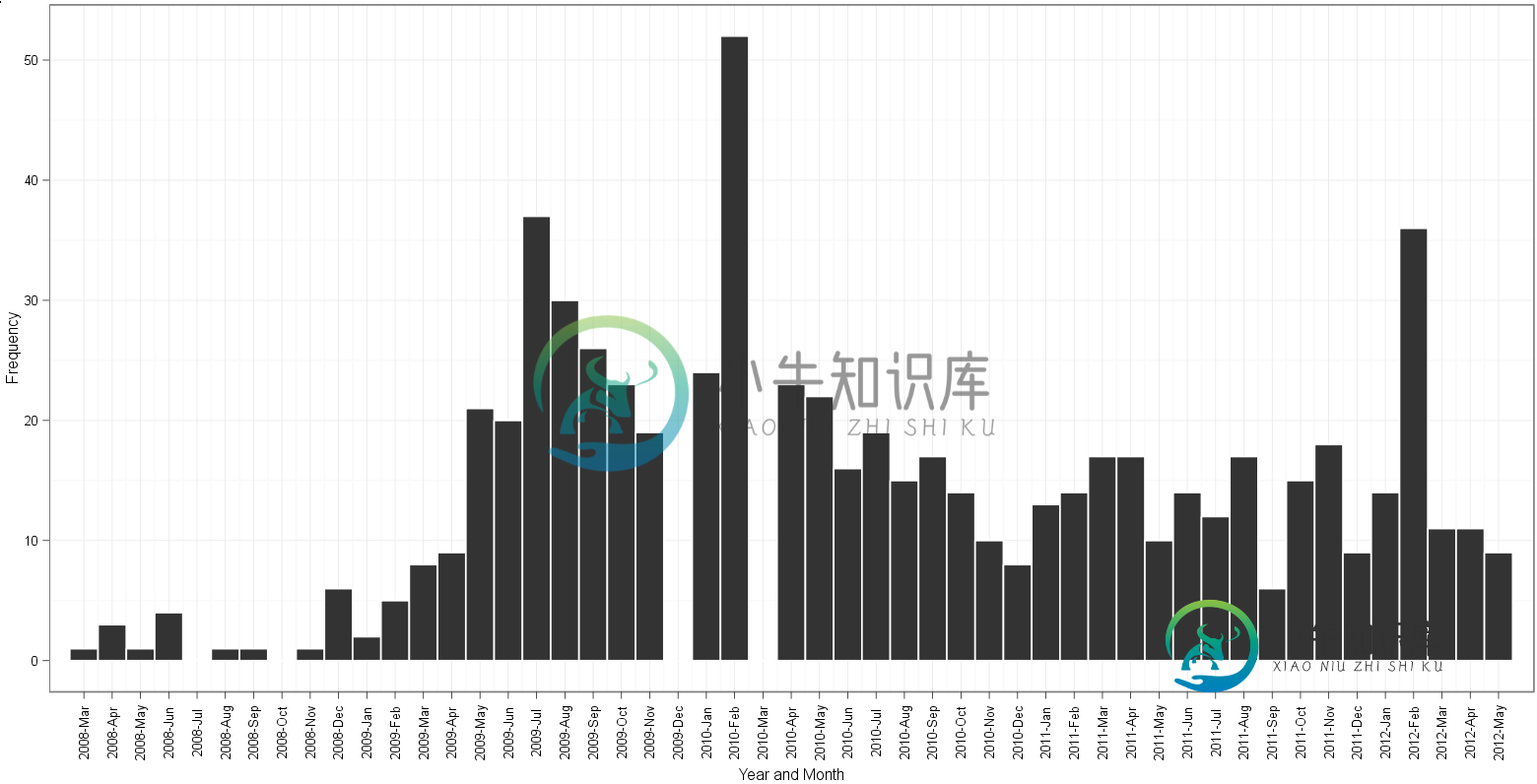
根据edgester的方法绘制:

根据gauden的方法绘制:
注意以下几点:
- 在2009年12月和2010年3月高登的图的差距;
表(日期$Date)显示有19个实例2009-12-01和26个实例2010-03-01在数据 - edgester的情节从2008年4月开始,到2012年5月结束。根据2008-04-01数据中的最小值和2012-05-01的最大日期,这是正确的。出于某种原因,高登的阴谋始于2008年3月,但仍设法在2012年5月结束。在数了数箱子并沿着月份标签阅读后,对于我来说,我不知道哪个情节有多余的或者缺少直方图的一个箱子!
对这里的差异有什么想法吗?edgester创建单独计数的方法
另一方面,这里还有其他一些位置,为寻求帮助的路人提供有关日期和ggplot2的信息:
- 从learnr开始。wordpress,一个流行的博客。它说我需要将数据转换成POSIXct格式,我现在认为这是错误的,浪费了我的时间
- 另一篇learnr帖子在ggplot2中重新创建了一个时间序列,但并不适用于我的情况
- r-bloggers对此发表了一篇文章,但似乎已经过时了。简单的
format=选项对我不起作用 - 所以,这个问题是玩Rest和标签。我试着把我的
日期向量看作是连续的,但觉得效果不太好。它看起来像是一次又一次地覆盖着相同的标签文本,所以字母看起来有点奇怪。分布有点正确,但有奇数的中断。我基于公认答案的尝试是这样的(结果在这里)
共有3个答案

我认为关键是你需要在ggplot之外进行频率计算。将aggregate()与geom_bar(stat=“identity”)一起使用,以获得没有重新排序因子的直方图。下面是一些示例代码:
require(ggplot2)
# scales goes with ggplot and adds the needed scale* functions
require(scales)
# need the month() function for the extra plot
require(lubridate)
# original data
#df<-read.csv("http://pastebin.com/download.php?i=sDzXKFxJ", header=TRUE)
# simulated data
years=sample(seq(2008,2012),681,replace=TRUE,prob=c(0.0176211453744493,0.302496328928047,0.323054331864905,0.237885462555066,0.118942731277533))
months=sample(seq(1,12),681,replace=TRUE)
my.dates=as.Date(paste(years,months,01,sep="-"))
df=data.frame(YM=strftime(my.dates, format="%Y-%b"),Date=my.dates,Year=years,Month=months)
# end simulated data creation
# sort the list just to make it pretty. It makes no difference in the final results
df=df[do.call(order, df[c("Date")]), ]
# add a dummy column for clarity in processing
df$Count=1
# compute the frequencies ourselves
freqs=aggregate(Count ~ Year + Month, data=df, FUN=length)
# rebuild the Date column so that ggplot works
freqs$Date=as.Date(paste(freqs$Year,freqs$Month,"01",sep="-"))
# I set the breaks for 2 months to reduce clutter
g<-ggplot(data=freqs,aes(x=Date,y=Count))+ geom_bar(stat="identity") + scale_x_date(labels=date_format("%Y-%b"),breaks="2 months") + theme_bw() + opts(axis.text.x = theme_text(angle=90))
print(g)
# don't overwrite the previous graph
dev.new()
# just for grins, here is a faceted view by year
# Add the Month.name factor to have things work. month() keeps the factor levels in order
freqs$Month.name=month(freqs$Date,label=TRUE, abbr=TRUE)
g2<-ggplot(data=freqs,aes(x=Month.name,y=Count))+ geom_bar(stat="identity") + facet_grid(Year~.) + theme_bw()
print(g2)

我知道这是一个古老的问题,但是对于2021(或以后)的任何人来说,使用<代码> Stuts= < /Cord>参数> <代码> GEOMYSCORGROM()/代码>,并创建一个小的快捷功能来生成所需的序列,可以做得更容易。
dates <- read.csv("http://pastebin.com/raw.php?i=sDzXKFxJ", sep=",", header=T)
dates$Date <- lubridate::ymd(dates$Date)
by_month <- function(x,n=1){
seq(min(x,na.rm=T),max(x,na.rm=T),by=paste0(n," months"))
}
ggplot(dates,aes(Date)) +
geom_histogram(breaks = by_month(dates$Date)) +
scale_x_date(labels = scales::date_format("%Y-%b"),
breaks = by_month(dates$Date,2)) +
theme(axis.text.x = element_text(angle=90))

使现代化
我更新了这个例子来演示对齐标签和设置绘图的限制。我还演示了as。Date在一致使用时确实有效(实际上,它可能比我之前的例子更适合您的数据)。
下面是(有些过度)注释的代码:
library("ggplot2")
library("scales")
dates <- read.csv("http://pastebin.com/raw.php?i=sDzXKFxJ", sep=",", header=T)
dates$Date <- as.Date(dates$Date)
# convert the Date to its numeric equivalent
# Note that Dates are stored as number of days internally,
# hence it is easy to convert back and forth mentally
dates$num <- as.numeric(dates$Date)
bin <- 60 # used for aggregating the data and aligning the labels
p <- ggplot(dates, aes(num, ..count..))
p <- p + geom_histogram(binwidth = bin, colour="white")
# The numeric data is treated as a date,
# breaks are set to an interval equal to the binwidth,
# and a set of labels is generated and adjusted in order to align with bars
p <- p + scale_x_date(breaks = seq(min(dates$num)-20, # change -20 term to taste
max(dates$num),
bin),
labels = date_format("%Y-%b"),
limits = c(as.Date("2009-01-01"),
as.Date("2011-12-01")))
# from here, format at ease
p <- p + theme_bw() + xlab(NULL) + opts(axis.text.x = theme_text(angle=45,
hjust = 1,
vjust = 1))
p
我尝试了一个解决方案,它可以在ggplot2中完成所有事情,在没有聚合的情况下绘制,并在2009年初和2011年底之间设置x轴的限制。
library("ggplot2")
library("scales")
dates <- read.csv("http://pastebin.com/raw.php?i=sDzXKFxJ", sep=",", header=T)
dates$Date <- as.POSIXct(dates$Date)
p <- ggplot(dates, aes(Date, ..count..)) +
geom_histogram() +
theme_bw() + xlab(NULL) +
scale_x_datetime(breaks = date_breaks("3 months"),
labels = date_format("%Y-%b"),
limits = c(as.POSIXct("2009-01-01"),
as.POSIXct("2011-12-01")) )
p
当然,它可以通过在轴上玩标签选项来完成,但这是在绘图包中使用一个干净的短例程来完成绘图。
-
我想用R随机构造自由度为5的卡方分布,有100个观测量。这样做之后,我想计算这些观测的平均值,并使用ggplot2用条形图绘制卡方分布。以下是我的代码: 首先,构造一个df=5,obs=100的随机卡方分布的数据帧。 但是,我得到的结果如下: 我被这个问题困了几个小时,在我的全局环境中找不到任何列表。如果有人能帮助我,给我一些建议,将不胜感激。
-
我有一个“长”格式的数据框,它包含两列:第一列值,第二列性别[Male-1/Female-2]。我编写了一些代码来制作整个数据集的直方图(下面的代码)。 但是,我还想在直方图上添加一个密度,以强调性别之间的差异,即我想组合3个图:整个数据集的直方图,以及每个性别的2个密度图。我尝试使用一些示例(一、二、三、四),但仍然不起作用。“密度”代码仅起作用,而“历史密度”的组合不起作用。 P. S.一些例
-
我有一个三维阵列。列的标题是“身高”、“体重”和“年龄”。如何使用或任何其他可用功能绘制三维直方图? 我从这段代码开始,但后来我陷入了如何绘制三维直方图的困境。谢谢你宝贵的时间
-
numpy.histogram()函数将输入数组和作为两个参数。 bin数组中的连续元素用作每个bin的边界。 Matplotlib 可以将直方图的数字表示转换为图形。 pyplot子模块的plt()函数将包含数据和数组的数组作为参数,并转换为直方图。
-
我正在尝试使用 marplot.lib 库在 Python 中绘制直方图;但是,我一直收到此错误:“属性错误:箱必须单调增加。 这是我目前的代码: 传入的参数是信息。“信息”是一个元组列表,可能如下所示: [(4, 0.7984031936127745), (5, 0.5988023952095809), (5, 0.8739076154806492), (5, 0.736454497632824
-
问题内容: 我有一个固定宽度的数据文件,其中包含日期,但是当我尝试绘制数据时,日期无法在x轴上正确显示。 我的档案看起来像 等等 我用 熊猫 读文件 所以我想这里的问题是从熊猫到matplotlib日期时间的转换,如何进行转换? 我也直接尝试了熊猫: 但这失败了 TypeError:空的“ Series”:没有要绘制的数字数据 问题答案: 如果您使用包含列名而不是字符串的列表,则data.set_