
如何从文件中读取两行并在for循环中创建动态键?

在以下数据中,我试图运行一个简单的markov模型。
说我有以下结构的数据:
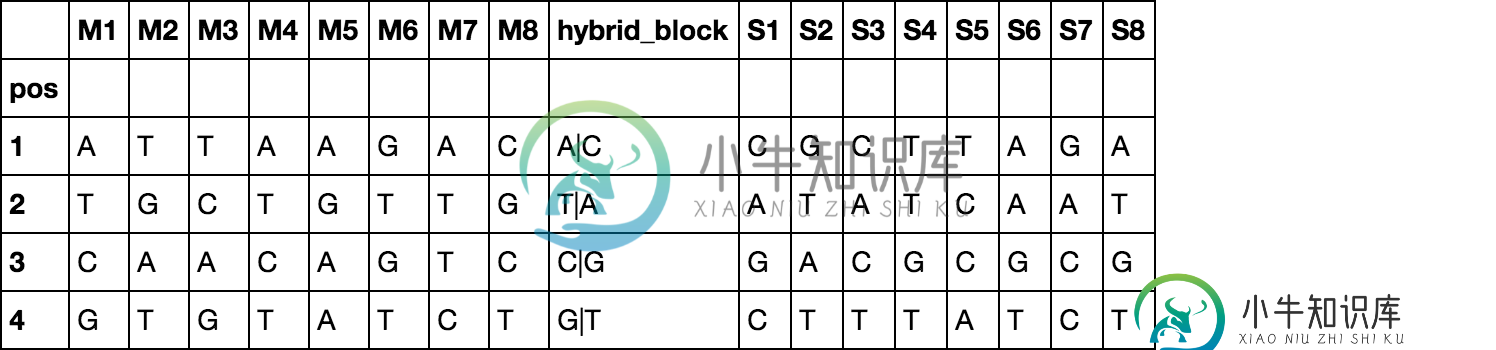
pos M1 M2 M3 M4 M5 M6 M7 M8 hybrid_block S1 S2 S3 S4 S5 S6 S7 S8
1 A T T A A G A C A|C C G C T T A G A
2 T G C T G T T G T|A A T A T C A A T
3 C A A C A G T C C|G G A C G C G C G
4 G T G T A T C T G|T C T T T A T C T
块M 代表一组类别的数据, 块S 也是如此。
数据是strings通过沿位置线连接字母而得到的。因此, M1 的 字符串值是ATCG ,其他所有块的 字符串值也是 如此。
还有一个hybrid block具有两个以相同方式读取的字符串。 问题是我想找到混合块中的哪个字符串最有可能来自哪个块(M对S)?
我正在尝试建立一个markov模型,该模型可以帮助我确定哪个字符串hybrid block来自哪个块。在这个例子中,我可以说in 混合块
ATCG来自block M和CAGT来自block S。
我将问题分为不同的部分 来读取和挖掘数据:
问题级别01:
- 首先,我阅读第一行(标题)并
unique keys为所有列创建。 - 然后,我读第二行(
pos值为 1 )并创建另一个键。在同一行中,我从中hybrid_block读取值并读取其中的字符串值。该pipe |只是一个分隔符,这样两个字符串是在index 0 and 2为A和C。所以,我想从这行开始的是
defaultdict(<class 'dict'>, {'M1': ['A'], 'M2': ['T'], 'M3': ['T']...., 'hybrid_block': ['A'], ['C']...}
在阅读该行的过程中,我想添加每列中的字符串值并最终创建。
defaultdict(<class 'dict'>, {'M1': ['A', 'T', 'C', 'G'], 'M2': ['T', 'G', 'A', 'T'], 'M3': ['T', 'C', 'A', 'G']...., 'hybrid_block': ['A', 'T', 'C', 'G'], ['C', 'A', 'G', 'T']...}
问题级别02:
-
我
hybrid_block在第一行读取数据A and C。 -
现在,我要创建
keys' but unlike fixed keys, these key will be generated while reading the data fromhybrid_blocks. For the first line since there are no preceding line the键will simply beAgAandCgCwhich means (A given A, and C given C), and for the values I count the number ofAin块Mand块S`。因此,数据将存储为:
defaultdict(<class 'dict'>, {'M': {'AgA': [4], 'CgC': [1]}, 'S': {'AgA': 2, 'CgC': 2}}
作为,我通读了其他各行,我想根据字符串中的内容创建新键,hybrid block并在M vs S给定字符串在前一行中的情况下,计算该字符串在块中存在的次数。这意味着该行的keyswhile读数line 2为TgA' which means (T given A) and AgC. For the values inside this key I count the number of times I foundT,在前一行and same forAcG`中的A之后。
在defaultdict看完后3行会。
defaultdict(<class 'dict'>, {'M': {'AgA': 4, 'TgA':3, 'CgT':2}, {'CgC': [1], 'AgC':0, 'GgA':0}, 'S': {'AgA': 2, 'TgA':1, 'CgT':0}, {'CgC': 2, 'AgC':2, 'GgA':2}}
我知道这看起来太复杂了。我通过几个去dictionary和defaultdict教程,但找不到这样做的方式。
高度赞赏对任何部分(如果不是全部)的解决方案。
问题答案:
from io import StringIO
import pandas as pd
import numpy as np
txt = """pos M1 M2 M3 M4 M5 M6 M7 M8 hybrid_block S1 S2 S3 S4 S5 S6 S7 S8
1 A T T A A G A C A|C C G C T T A G A
2 T G C T G T T G T|A A T A T C A A T
3 C A A C A G T C C|G G A C G C G C G
4 G T G T A T C T G|T C T T T A T C T """
df = pd.read_csv(StringIO(txt), delim_whitespace=True, index_col='pos')
df
解
大多pandas与numpy
- 拆分混合柱
- 在相同的第一行之前
- 加上self的偏移版本以获取
'AgA'类型字符串
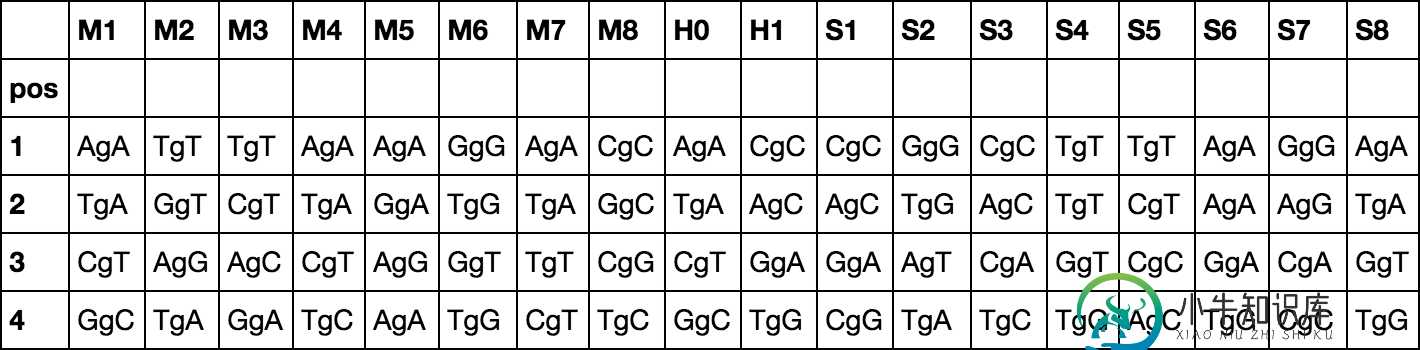
d1 = pd.concat([df.loc[[1]].rename(index={1: 0}), df])
d1 = pd.concat([
df.filter(like='M'),
df.hybrid_block.str.split('|', expand=True).rename(columns='H{}'.format),
df.filter(like='S')
], axis=1)
d1 = pd.concat([d1.loc[[1]].rename(index={1: 0}), d1])
d1 = d1.add('g').add(d1.shift()).dropna()
d1
将方便的块分配给自己的变量名
m = d1.filter(like='M')
s = d1.filter(like='S')
h = d1.filter(like='H')
计算每个块中有多少并连接
mcounts = pd.DataFrame(
(m.values[:, :, None] == h.values[:, None, :]).sum(1),
h.index, h.columns
)
scounts = pd.DataFrame(
(s.values[:, :, None] == h.values[:, None, :]).sum(1),
h.index, h.columns
)
counts = pd.concat([mcounts, scounts], axis=1, keys=['M', 'S'])
counts

如果你真的想要字典
d = defaultdict(lambda:defaultdict(list))
dict_df = counts.stack().join(h.stack().rename('condition')).unstack()
for pos, row in dict_df.iterrows():
d['M']['H0'].append((row.loc[('condition', 'H0')], row.loc[('M', 'H0')]))
d['S']['H0'].append((row.loc[('condition', 'H0')], row.loc[('S', 'H0')]))
d['M']['H1'].append((row.loc[('condition', 'H1')], row.loc[('M', 'H1')]))
d['S']['H1'].append((row.loc[('condition', 'H1')], row.loc[('S', 'H1')]))
dict(d)
{'M': defaultdict(list,
{'H0': [('AgA', 4), ('TgA', 3), ('CgT', 2), ('GgC', 1)],
'H1': [('CgC', 1), ('AgC', 0), ('GgA', 0), ('TgG', 1)]}),
'S': defaultdict(list,
{'H0': [('AgA', 2), ('TgA', 1), ('CgT', 0), ('GgC', 0)],
'H1': [('CgC', 2), ('AgC', 2), ('GgA', 2), ('TgG', 3)]})}
-
问题内容: 我一直在尝试并行化以下脚本,特别是for循环。我怎样才能做到这一点? 问题答案: 更换 与
-
问题内容: 我刚接触Python,但仍处于学习曲线的艰难阶段。感谢您的任何评论。 我有一个很大的for循环要运行(在许多迭代中都很大),例如: 我虽然认为这将是一个如何并行化的常见问题,但在Google上搜索了数小时后,我使用“多重处理”模块找到了解决方案,如下所示: 当循环较小时,此方法有效。但是,如果循环很大,这确实很慢,或者如果循环太大,有时会发生内存错误。看来python会首先生成参数列表
-
任何帮助都是非常感谢的
-
问题内容: 无论如何,我可以写到tempfile并将其包含在命令中,然后关闭/删除它。我想执行命令,例如:some_command / tmp / some-temp-file。 提前谢谢了。 问题答案: 如果需要带有名称的临时文件,则必须使用该功能。然后就可以使用了。有关详细信息,请阅读 http://docs.python.org/library/tempfile.html。
-
我想在Python2.7中并行化两个嵌套的for循环,但我自己没有成功。我不知道如何接近什么是并行化的定义。 总之,这里是单处理器代码:
-
我的第一个java程序… 所以我试图用java创建一个文件并存储在我的pc中 我仍然得到这个错误 错误:未解决的编译问题:未处理的异常类型IOException未处理的异常类型FileNotFoundException未处理的异常类型IOException未处理的异常类型IOException未处理的异常类型IOException未处理的异常类型IOException未处理的异常类型IOExcep