
gbdt推导和适用场景

参考回答:
1)明确损失函数是误差最小
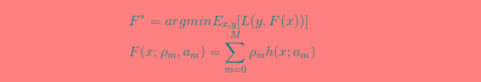
2)构建第一棵回归树
3)学习多棵回归树

迭代:计算梯度/残差gm(如果是均方误差为损失函数即为残差)
步长/缩放因子p,用 a single Newton-Raphson step 去近似求解下降方向步长,通常的实现中 Step3 被省略,采用 shrinkage 的策略通过参数设置步长,避免过拟合:第m棵树fm=pgm;模型Fm=Fm-1+pgm
4)F(x)等于所有树结果累加
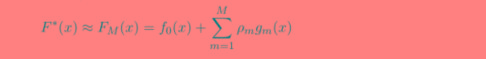
适用场景:GBDT几乎可用于所有回归问题(线性/非线性),GBDT的适用面非常广。亦可用于二html" target="_blank">分类问题(设定阈值,大于阈值为正例,反之为负例)。
-
本文向大家介绍gbdt推导相关面试题,主要包含被问及gbdt推导时的应答技巧和注意事项,需要的朋友参考一下 参考回答: GBDT 全称为 Gradient Boosting Decision Tree。顾名思义,它是一种基于决策树(decision tree)实现的分类回归算法。 Gradient Descent: method of steepest descent 梯度下降作为求解确定可微方程
-
本文档所描述的 API 接口,仅限用于数据的查询,适用于 百度移动统计 站点的用户使用,适用场景有如下: 获取 百度移动统计 站点的报告数据,用于邮件发送 获取 百度移动统计 站点的报告数据,用于二次开发 查询 百度移动统计 站点中用户或应用相关的配置信息 其余需要基于百度移动统计的报表数据的业务场景
-
MIP 适用于所有需要加速的站点。 如果您的站点响应速度慢,如果您的 CDN 速度慢,如果您希望广告有更高的 ROI,那 MIP 就非常适合您的站点。 MIP 最核心,也是我们一直尽力遵守的原则是:速度最快和体验最好。 截至到目前,有超过 1w 个站点接入 MIP,他们使用 MIP 获得了极致的用户体验并且带来了客观的广告收入。 谁最应该关注 MIP 呢? 资讯阅读类的站点 电商网站 广告主 其他
-
本文向大家介绍xgboost和lightgbm的区别和适用场景?相关面试题,主要包含被问及xgboost和lightgbm的区别和适用场景?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: (1)xgboost采用的是level-wise的分裂策略,而lightGBM采用了leaf-wise的策略,区别是xgboost对每一层所有节点做无差别分裂,可能有些节点的增益非常小,对结果影响不大,但
-
本文向大家介绍AdaBoost和GBDT的区别,AdaBoost和GBDT的区别?相关面试题,主要包含被问及AdaBoost和GBDT的区别,AdaBoost和GBDT的区别?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: AdaBoost通过调整错分的数据点的权重来改进模型,而GBDT是从负梯度的方向去拟合改进模型。 AdaBoost改变了训练数据的权值,即样本的概率分布,减少上一轮被正
-
GBDT on Spark on Angel GBDT(Gradient Boosting Decision Tree):梯度提升决策树 是一种集成使用多个弱分类器(决策树)来提升分类效果的机器学习算法,在很多分类和回归的场景中,都有不错的效果。 1. 算法介绍 如图1所示,这是是对一群消费者的消费力进行预测的例子。简单来说,处理流程为: 在第一棵树中,根节点选取的特征是年龄,年龄小于30的被分为