
LSTM和GRU?

lstm如何来防止梯度爆炸和梯度消失的?
针对RNN, 要解决梯度爆炸可以使用梯度裁剪的方式来进行,而对于梯度消失,由于
传统的RNN是用覆盖的的方式计算状态: ,也就是说,这有点类似于复合函数,那么根据链式求导的法则,复合函数求导:设f和g为x的可导函数,则 ,他们是一种乘积的方式,那么如果导数都是小数或者都是大于1的数的话,就会使得总的梯度发生vanishing或explosion的情况,当然梯度爆炸(gradient explosion)不是个严重的问题,一般靠裁剪后的优化算法即可解决,比如gradient clipping(如果梯度的范数大于某个给定值,将梯度同比收缩),但是梯度消失做不到,这个时候就要用lstm了。
在lstm中,我们发现,状态S是通过累加的方式来计算的, 。那这样的话,就不是一直复合函数的形式了,它的的导数也不是乘积的形式,这样就不会发生梯度消失的情况了。
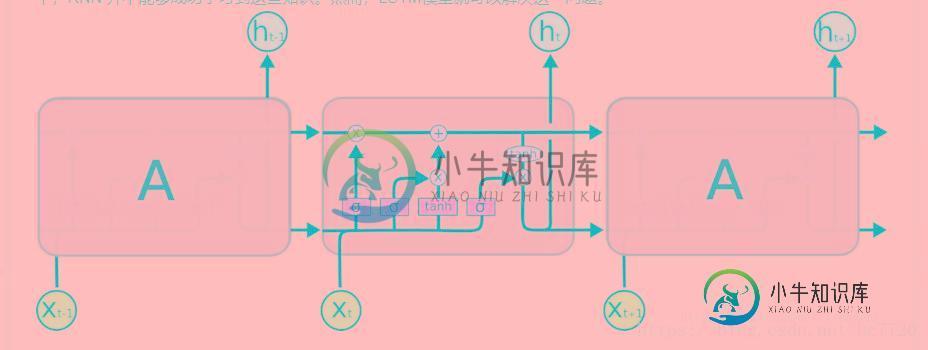
如果只是对gru和lstm来说的话,一方面GRU的参数更少,因而训练稍快或需要更少的数据来泛化。另一方面,如果你有足够的数据,LSTM的强大表达能力可能会产生更好的结果。GRU作为LSTM的一种变体,将忘记门和输入门合成了一个单一的更新门。同样还混合了细胞状态和隐藏状态,加诸其他一些改动。最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。
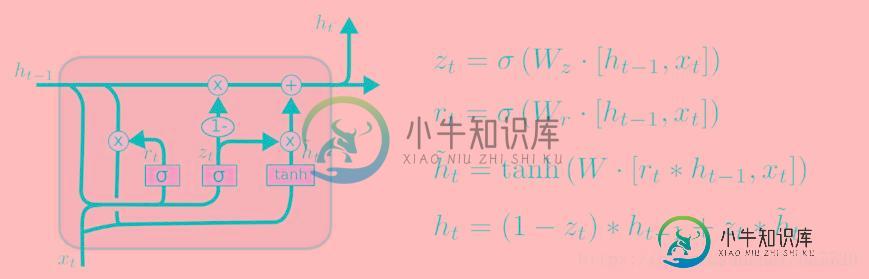
-
本文向大家介绍Lstm和Gru的原理相关面试题,主要包含被问及Lstm和Gru的原理时的应答技巧和注意事项,需要的朋友参考一下 参考回答: Lstm由输入门,遗忘门,输出门和一个cell组成。第一步是决定从cell状态中丢弃什么信息,然后在决定有多少新的信息进入到cell状态中,最终基于目前的cell状态决定输出什么样的信息。 Gru由重置门和跟新门组成,其输入为前一时刻隐藏层的输出和当前的输入,
-
本文向大家介绍LSTM和Naive RNN的区别相关面试题,主要包含被问及LSTM和Naive RNN的区别时的应答技巧和注意事项,需要的朋友参考一下 参考回答: RNN和LSTM内部结构的不同: RNN LSTM 由上面两幅图可以观察到,LSTM结构更为复杂,在RNN中,将过去的输出和当前的输入concatenate到一起,通过tanh来控制两者的输出,它只考虑最近时刻的状态。在RNN中有两个输
-
有关 Keras LSTM 模型的更多文档 在输入/输出对上训练模型,其中输入是生成的长度为 input_len 的均匀分布随机序列, 输出是窗口长度为 tsteps 的输入的移动平均值。input_len 和 tsteps 都在 "可编辑参数" 部分中定义。 较大的 tsteps 值意味着 LSTM 需要更多的内存来确定输入输出关系。 该内存长度由 lahead 变量控制(下面有更多详细信息)。
-
Output after 4 epochs on CPU: ~0.8146. Time per epoch on CPU (Core i7): ~150s. 在 CPU 上经过 4 个轮次后的输出:〜0.8146。 CPU(Core i7)上每个轮次的时间:〜150s。 from __future__ import print_function import numpy as np from k
-
该网络用于预测包含移动方块的人工生成的电影的下一帧。 from keras.models import Sequential from keras.layers.convolutional import Conv3D from keras.layers.convolutional_recurrent import ConvLSTM2D from keras.layers.normalization
-
问题内容: 我试图调和我对LSTM的理解,并在克里斯托弗·奥拉(Christopher Olah)在Keras中实现的这篇文章中指出了这一点。我正在关注Jason Brownlee为Keras教程撰写的博客。我最困惑的是 将数据系列重塑为和 有状态的LSTM 让我们参考下面粘贴的代码专注于以上两个问题: 注意:create_dataset接受一个长度为N的序列,并返回一个N-look_back数组