
LSTM和Naive RNN的区别

参考回答:
RNN和LSTM内部结构的不同:
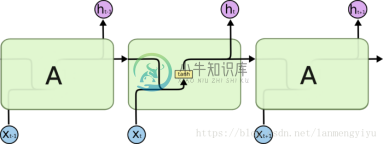
RNN
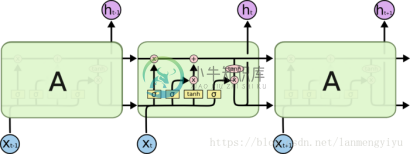
LSTM
由上面两幅图可以观察到,LSTM结构更为复杂,在RNN中,将过去的输出和当前的输入concatenate到一起,通过tanh来控制两者的输出,它只考虑最近时刻的状态。在RNN中有两个输入和一个输出。
而LSTM为了能记住长期的状态,在RNN的基础上增加了一路输入和一路输出,增加的这一路就是细胞状态,也就是途中最上面的一条通路。事实上整个LSTM分成了三个部分:
1)哪些细胞状态应该被遗忘
2)哪些新的状态应该被加入
3)根据当前的状态和现在的输入,输出应该是什么
下面来分别讨论:
1)哪些细胞状态应该被遗忘
这部分功能是通过sigmoid函数实现的,也就是最左边的通路。根据输入和上一时刻的输出来决定当前细胞状态是否有需要被遗忘的内容。举个例子,如果之前细胞状态中有主语,而输入中又有了主语,那么原来存在的主语就应该被遗忘。concatenate的输入和上一时刻的输出经过sigmoid函数后,越接近于0被遗忘的越多,越接近于1被遗忘的越少。
2)哪些新的状态应该被加入
继续上面的例子,新进来的主语自然就是应该被加入到细胞状态的内容,同理也是靠sigmoid函数来决定应该记住哪些内容。但是值得一提的是,需要被记住的内容并不是直接concatenate的输入和上一时刻的输出,还要经过tanh,这点应该也是和RNN保持一致。并且需要注意,此处的sigmoid和前一步的sigmoid层的w和b不同,是分别训练的层。细胞状态在忘记了该忘记的,记住了该记住的之后,就可以作为下一时刻的细胞状态输入了。
3)根据当前的状态和现在的输入,输出应该是什么
这是最右侧的通路,也是通过sigmoid函数做门,对第二步求得的状态做tanh后的结果过滤,从而得到最终的预测结果。事实上,LSTM就是在RNN的基础上,增加了对过去状态的过滤,从而可以选择哪些状态对当前更有影响,而不是简单的选择最近的状态。
-
本文向大家介绍LSTM和GRU?相关面试题,主要包含被问及LSTM和GRU?时的应答技巧和注意事项,需要的朋友参考一下 lstm如何来防止梯度爆炸和梯度消失的? 针对RNN, 要解决梯度爆炸可以使用梯度裁剪的方式来进行,而对于梯度消失,由于 传统的RNN是用覆盖的的方式计算状态: ,也就是说,这有点类似于复合函数,那么根据链式求导的法则,复合函数求导:设f和g为x的可导函数,则 ,他们是一种乘积的
-
本文向大家介绍LSTM跟RNN有啥区别相关面试题,主要包含被问及LSTM跟RNN有啥区别时的应答技巧和注意事项,需要的朋友参考一下 参考回答: LSTM与RNN的比较 RNN在处理long term memory的时候存在缺陷,因此LSTM应运而生。LSTM是一种变种的RNN,它的精髓在于引入了细胞状态这样一个概念,不同于RNN只考虑最近的状态,LSTM的细胞状态会决定哪些状态应该被留下来,哪些状
-
本文向大家介绍LSTM原理,与GRU区别相关面试题,主要包含被问及LSTM原理,与GRU区别时的应答技巧和注意事项,需要的朋友参考一下 参考回答: LSTM算法全称为Long short-term memory,是一种特定形式的RNN(Recurrent neural network,循环神经网络),而RNN是一系列能够处理序列数据的神经网络的总称。 RNN在处理长期依赖(时间序列上距离较远的节点
-
本文向大家介绍Lstm和Gru的原理相关面试题,主要包含被问及Lstm和Gru的原理时的应答技巧和注意事项,需要的朋友参考一下 参考回答: Lstm由输入门,遗忘门,输出门和一个cell组成。第一步是决定从cell状态中丢弃什么信息,然后在决定有多少新的信息进入到cell状态中,最终基于目前的cell状态决定输出什么样的信息。 Gru由重置门和跟新门组成,其输入为前一时刻隐藏层的输出和当前的输入,
-
假设我们有一个用于时间序列预测的LSTM模型。此外,这是一个多变量的情况,因此我们使用多个特性来训练模型。 我们可以在LSTM之前(如上面的代码)或LSTM之后添加层。 > 如果我们在LSTM之前添加它,它是在时间步长(时间序列的不同延迟)上应用退出,还是在不同的输入特性上应用退出,或者两者都应用? 如果我们将它添加到LSTM之后,并且因为是,那么辍学者在这里做什么? 中的选项与层之前的dropo
-
有关 Keras LSTM 模型的更多文档 在输入/输出对上训练模型,其中输入是生成的长度为 input_len 的均匀分布随机序列, 输出是窗口长度为 tsteps 的输入的移动平均值。input_len 和 tsteps 都在 "可编辑参数" 部分中定义。 较大的 tsteps 值意味着 LSTM 需要更多的内存来确定输入输出关系。 该内存长度由 lahead 变量控制(下面有更多详细信息)。