
为什么LSTM中既存在tanh和sigmoid,而不同意采用一样的?

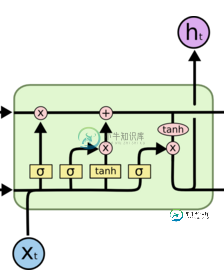
sigmoid 用在了各种gate上,产生0~1之间的值,这个一般只有sigmoid最直接了。 tanh 用在了状态和输出上,是对数据的处理,这个用其他激活函数或许也可以。
-
本文向大家介绍为什么在LSTM模型中既存在sigmoid函数又存在tanh两种激活函数,二不是选择区中单独的一组?这样做的目的是什么?相关面试题,主要包含被问及为什么在LSTM模型中既存在sigmoid函数又存在tanh两种激活函数,二不是选择区中单独的一组?这样做的目的是什么?时的应答技巧和注意事项,需要的朋友参考一下 答:sigmoid函数用在了各种gate上,产生0~1之间的值,这个一般
-
本文向大家介绍relu为何好过sigmoid和tanh?相关面试题,主要包含被问及relu为何好过sigmoid和tanh?时的应答技巧和注意事项,需要的朋友参考一下 先看sigmoid、tanh和RelU的函数图: 第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法和指数运算,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。 第
-
本文向大家介绍为什么用relu就不用sigmoid了相关面试题,主要包含被问及为什么用relu就不用sigmoid了时的应答技巧和注意事项,需要的朋友参考一下 参考回答: Sigmoid的导数只有在0的附近时有比较好的激活性,在正负饱和区域的梯度都接近0,会导致梯度弥散。而relu函数在大于0的部分梯度为常数,不会产生梯度弥散现象。Relu函数在负半区导数为0,也就是说这个神经元不会经历训练,就是
-
本文向大家介绍Sigmoid 与tanh的区别优劣?相关面试题,主要包含被问及Sigmoid 与tanh的区别优劣?时的应答技巧和注意事项,需要的朋友参考一下 sigmoid对于前向传播比较友好,将值映射到0,1之间,但是反向传播容易出现梯度消失的情况,并且进行幂计算比较耗时,产生的信号为非0均值信号,会对反向传播造成影响,而tanh将其映射到-1,1之间,数据分布均值为0
-
有个问题,我在本地虚拟机和云服务器 使用docker 启动同一个镜像,但本地和远程容器的内存占用差别很大 我确保使用的都是同一个镜像 这个是本地的linux中容器内存占用情况 1.4G 这是远程的服务器容器内存占用情况,远程的这个容器应用并没有其他操作,跟本地相比整整多出快1个G,表示有点不理解 这是为什么 有没有大佬解释下
-
对于我的具体情况,我想在约简中使用函数合成;例如: 这有一个编译错误: 相反,我需要做的是: 但是,这就失去了composition提供的无点样式。 为什么流API是这样设计的?是,所以用超类型声明方法的参数不是更有意义吗?