
relu为何好过sigmoid和tanh?

先看sigmoid、tanh和RelU的函数图:
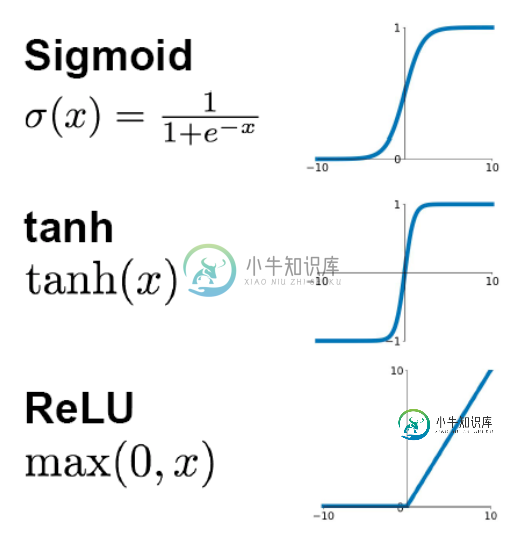
第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法和指数运算,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),这种现象称为饱和,从而无法完成深层网络的训练。而ReLU就不会有饱和倾向,不会有特别小的梯度出现。
第三,Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生(以及一些人的生物解释balabala)。当然现在也有一些对relu的改进,比如prelu,random relu等,在不同的数据集上会有一些训练速度上或者准确率上的改进。
-
本文向大家介绍Relu比Sigmoid的效果好在哪里?相关面试题,主要包含被问及Relu比Sigmoid的效果好在哪里?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: Sigmoid的导数只有在0的附近时有较好的激活性,而在正负饱和区域的梯度趋向于0,从而产生梯度弥散的现象,而relu在大于0的部分梯度为常数,所以不会有梯度弥散现象。Relu的导数计算的更快。Relu在负半区的导数为0,所
-
本文向大家介绍神经网路中使用relu函数要好过tanh和sigmoid函数?相关面试题,主要包含被问及神经网路中使用relu函数要好过tanh和sigmoid函数?时的应答技巧和注意事项,需要的朋友参考一下 1.使用sigmoid函数,算激活函数时(指数运算),计算量大,反向传播误差梯度时,求导涉及除法和指数运算,计算量相对较大,而采用relu激活函数,整个过程的计算量节省很多 2.对于深层网络,
-
本文向大家介绍为什么用relu就不用sigmoid了相关面试题,主要包含被问及为什么用relu就不用sigmoid了时的应答技巧和注意事项,需要的朋友参考一下 参考回答: Sigmoid的导数只有在0的附近时有比较好的激活性,在正负饱和区域的梯度都接近0,会导致梯度弥散。而relu函数在大于0的部分梯度为常数,不会产生梯度弥散现象。Relu函数在负半区导数为0,也就是说这个神经元不会经历训练,就是
-
本文向大家介绍relu相关面试题,主要包含被问及relu时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 在深度神经网络中,通常使用一种叫修正线性单元(Rectified linear unit,ReLU)作为神经元的激活函数。ReLU起源于神经科学的研究:2001年,Dayan、Abott从生物学角度模拟出了脑神经元接受信号更精确的激活模型,如下图: 其中横轴是时间(ms),纵轴是神经元的
-
本文向大家介绍sigmoid函数特性相关面试题,主要包含被问及sigmoid函数特性时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 定义域为 值域为(0,1) 函数在定义域内为连续和光滑的函数 处处可导,导数为
-
在使用relu激活功能时,我在实现backprop时遇到问题。我的模型有两个隐藏层,两个隐藏层中都有10个节点,输出层中有一个节点(因此有3个权重,3个偏差)。我的模型不适用于这个断开的backward\u prop函数。但是,该函数使用sigmoid激活函数(作为注释包含在函数中)与backprop一起工作。因此,我认为我把relu推导搞砸了。 谁能把我推向正确的方向?