
为什么引入非线性激活函数?

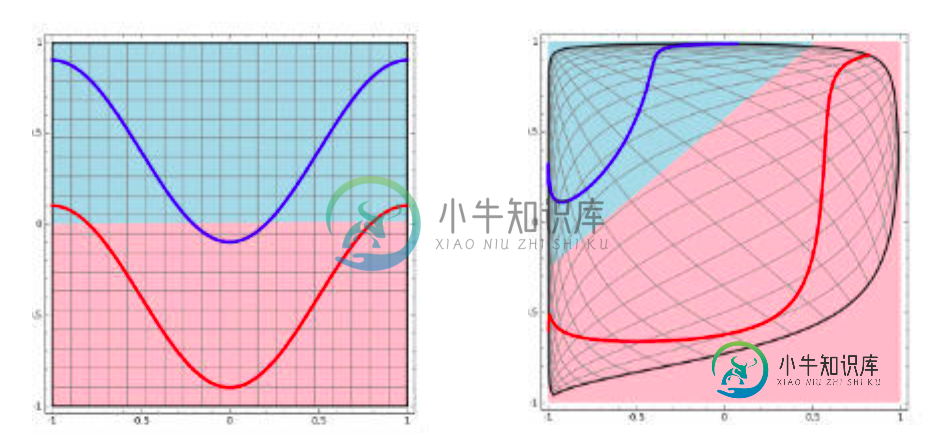
第一,对于神经网络来说,网络的每一层相当于f(wx+b)=f(w'x),对于线性函数,其实相当于f(x)=x,那么在线性激活函数下,每一层相当于用一个矩阵去乘以x,那么多层就是反复的用矩阵去乘以输入。根据矩阵的乘法法则,多个矩阵相乘得到一个大矩阵。所以线性激励函数下,多层网络与一层网络相当。比如,两层的网络f(W1*f(W2x))=W1W2x=Wx。 第二,非线性变换是深度学习有效的原因之一。原因在于非线性相当于对空间进行变换,变换完成后相当于对问题空间进行简化,原来线性不可解的问题现在变得可以解了。 下图可以很形象的解释这个问题,左图用一根线是无法划分的。经过一系列变换后,就变成线性可解的问题了。
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。 正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入(以及一些人的生物解释)。
-
本文向大家介绍为什么要引入非线性激励函数?相关面试题,主要包含被问及为什么要引入非线性激励函数?时的应答技巧和注意事项,需要的朋友参考一下 答: 1.对于神经网络来说,网络的每一层相当于f(wx+b)=f(w'x),对于线性函数,其实相当于f(x)=x,那么在线性激活函数下,每一层相当于用一个矩阵 去乘以x,那么多层就是反复的用矩阵去乘以输入。根据举证的乘法法则,多个矩阵相乘得到一个大的矩阵。所以
-
我在玩Keras,我在想线性激活层和无激活层之间的区别是什么?它不是有同样的行为吗?如果是这样,那么线性激活的意义是什么呢? 我指的是这两段代码之间的区别: 和
-
它应该取消比赛,这样同一队的球员就不能互相攻击,但事实并非如此。为什么?您还可以建议创建FriendlyFire函数的其他方法。
-
激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。 Sigmoid 也成为 S 形函数,取值范围为 (0,1)。Sigmoid 将一个实数映射到 (0,1) 的区间,可以用来做二分类。Sigmoid 在特征相差比较复杂或是相差不是特别大时效果比较好。 sigmoid 缺点: 激活函数计算量大(指数运算),反向传播求误差梯度时,求导
-
我试着运行一个没有任何激活函数的简单神经网络,并且网络不会收敛。我正在使用MSE成本函数进行MNIST分类。 然而,如果我将校正线性激活函数应用于隐藏层(输出=max(0,x),其中x是加权和),那么它会很好地收敛。 为什么消除前一层的负面输出有助于学习?
-
我刚开始学习Dagger2,以解决一个特定的问题:我试图遵循MVVM架构,我的应用程序有一个存储库类,它将设置提取并保存在一个基本上包装SharedPreferences的CacheData类中。但是,SharedPreferences具有上下文相关性。由于我已经完成了将存储库和数据层与视图和应用程序类解耦的所有工作,传递上下文似乎是一种倒退。 下面是存储库类 应用程序类: 是否可以使用Dagge