
Zookeeper 如何选举master 主节点?

还记得上面我们的所说的临时节点吗?因为 Zookeeper 的强一致性,能够很好地在保证 在高并发的情况下保证节点创建的全局唯一性 (即无法重复创建同样的节点)。
利用这个特性,我们可以 让多个客户端创建一个指定的节点 ,创建成功的就是 master。
但是,如果这个 master 挂了怎么办???
你想想为什么我们要创建临时节点?还记得临时节点的生命周期吗?master 挂了是不是代表会话断了?会话断了是不是意味着这个节点没了?还记得 watcher 吗?我们是不是可以 让其他不是 master 的节点监听节点的状态 ,比如说我们监听这个临时节点的父节点,如果子节点个数变了就代表 master 挂了,这个时候我们 触发回调函数进行重新选举 ,或者我们直接监听节点的状态,我们可以通过节点是否已经失去连接来判断 master 是否挂了等等。
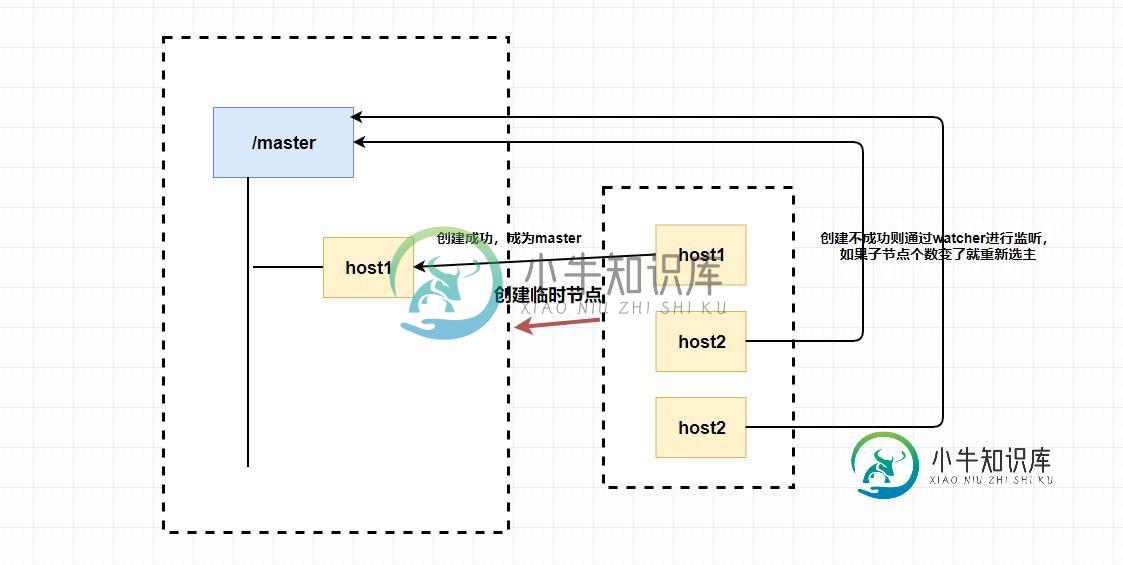
总的来说,我们可以完全 利用 临时节点、节点状态 和 watcher 来实现选主的功能,临时节点主要用来选举,节点状态和watcher 可以用来判断 master 的活性和进行重新选举。
-
本文向大家介绍Elasticsearch是如何实现master选举的?相关面试题,主要包含被问及Elasticsearch是如何实现master选举的?时的应答技巧和注意事项,需要的朋友参考一下 面试官:想了解ES集群的底层原理,不再只关注业务层面了。 解答: 前置前提: 1)只有候选主节点(master:true)的节点才能成为主节点。 2)最小主节点数(min_master_nodes)的目的
-
主要内容:1.Leader 的选举机制,2.投票 vote 的数据结构ZooKeeper 集群中的三个服务器角色:、 和 。其中,Leader 选举是 ZooKeeper 中最重要的技术之一,也是保证分布式数据一致性的关键所在。 而paxos算法中的角色为, , raft算法中的角色为, , 1.Leader 的选举机制 Zookeeper 在配置文件中并没有指定 和 。但是,Zookeeper 工作时, 是有一个节点为 ,其他则为 ,而这个 Leader 是通过内
-
我很难理解领导者、追随者机制是如何工作的,比如说,我正在构建一个分布式应用程序,其中有2个主节点、6个从节点和3个zookeeper节点,其中一个zookeeper节点是领导者,两个主节点中的1个是活动的,并连接到zookeeper领导者。 我的问题是 > 当管理员节点死亡时,是否会发生领导者选举机制?以及它将如何影响我们的主人,我们的主人是否会与新当选的领导人连接? 如果我们的应用程序的主节点死
-
zookeeper 的 leader 选举存在两个阶段,一个是服务器启动时 leader 选举,另一个是运行过程中 leader 服务器宕机。在分析选举原理前,先介绍几个重要的参数。 服务器 ID(myid):编号越大在选举算法中权重越大 事务 ID(zxid):值越大说明数据越新,权重越大 逻辑时钟(epoch-logicalclock):同一轮投票过程中的逻辑时钟值是相同的,每投完一次值会增加
-
本文向大家介绍理解zookeeper选举机制,包括了理解zookeeper选举机制的使用技巧和注意事项,需要的朋友参考一下 zookeeper集群 配置多个实例共同构成一个集群对外提供服务以达到水平扩展的目的,每个服务器上的数据是相同的,每一个服务器均可以对外提供读和写的服务,这点和redis是相同的,即对客户端来讲每个服务器都是平等的。 这篇主要分析leader的选择机制,zookeeper提供
-
本文向大家介绍ActiveMQ基于zookeeper的主从(levelDB Master/Slave)搭建,包括了ActiveMQ基于zookeeper的主从(levelDB Master/Slave)搭建的使用技巧和注意事项,需要的朋友参考一下 ActiveMQ 5.9.0新推出的主从实现,基于zookeeper来选举出一个master,其他节点自动作为slave实时同步消息。因为有实时同步数据