
ActiveMQ基于zookeeper的主从(levelDB Master/Slave)搭建

ActiveMQ 5.9.0新推出的主从实现,基于zookeeper来选举出一个master,其他节点自动作为slave实时同步消息。因为有实时同步数据的slave的存在,master不用担心数据丢失,所以leveldb会优先采用内存存储消息,异步同步到磁盘,所以该方式的activeMQ读写性能最好因为选举机制要超过半数,所以最少需要3台节点,才能实现高可用。如果集群是两台则master失效后slave会不起作用,所以集群至少三台。此种方式仅实现主备功能,避免单点故障,没有负载均衡功能。
1、环境准备
IP
192.168.3.10 server1
192.168.3.11 server2
192.168.3.12 server3
安装软件信息:
apache-activemq-5.13.0-bin.tar.gz
zookeeper-3.5.2-alpha.tar.gz
ZooInspector.zip
2、搭建Zookeeper集群
(1)将zookeeper-3.5.2-alpha.tar.gz文件解压到/home/wzh/zk目录;
(2)将zoo_sample.cfg复制一份为 zoo.cfg,并修改其配置信息
wzh@hd-master:~/zk/zookeeper-3.5.2-alpha/conf$ cp zoo_sample.cfg zoo.cfg
wzh@hd-master:~/zk/zookeeper-3.5.2-alpha/conf$vim zoo.cfg
tickTime=2000 initLimit=10 syncLimit=5 dataDir=/tmp/zookeeper clientPort=2181 server.1=192.168.3.10:2888:3888 server.2=192.168.3.11:2888:3888 server.3=192.168.3.11:2888:3888
(3)创建/tmp/zookeeper目录
在该目录下创建名为myid的文件,内容为1(这个值随server而改变)
(4)将server1上的/home/wzh/zk/zookeeper-3.5.2-alpha文件夹复制到server2,server3,然后创建/tmp/zookeeper目录
在该目录下创建名为myid的文件,内容为2
(5)启动zookeeper
[192.168.3.10]
wzh@hd-master:~/zk/zookeeper-3.5.2-alpha/bin$ ./zkServer.sh start ZooKeeper JMX enabled by default Using config: /home/wzh/zk/zookeeper-3.5.2-alpha/bin/../conf/zoo.cfg Starting zookeeper ... STARTED
[192.168.3.11]
wzh@hd-slave1:~/zk/zookeeper-3.5.2-alpha/bin$ ./zkServer.sh start ZooKeeper JMX enabled by default Using config: /home/wzh/zk/zookeeper-3.5.2-alpha/bin/../conf/zoo.cfg Starting zookeeper ... STARTED
[192.168.3.12]
wzh@hd-slave2:~/zk/zookeeper-3.5.2-alpha/bin$ ./zkServer.sh start ZooKeeper JMX enabled by default Using config: /home/wzh/zk/zookeeper-3.5.2-alpha/bin/../conf/zoo.cfg Starting zookeeper ... STARTED
3、搭建ActiveMQ集群
(1)将apache-activemq-5.13.0-bin.tar.gz解压到/home/wzh/amq
(2)修改activemq.xml配置文件
【1】将broker节点的brokerName设置为wzhamq
<broker xmlns="http://activemq.apache.org/schema/core" brokerName="wzhamq" dataDirectory="${activemq.data}">
【2】将persistenceAdapter的持久化方式选用replicatedLevelDB,将kahaDB方式注释掉
<persistenceAdapter>
<!--
<kahaDB directory="${activemq.data}/kahadb"/>
-->
<replicatedLevelDB
directory="${activemq.data}/leveldb"
replicas="3"
bind="tcp://0.0.0.0:0"
zkAddress="192.168.3.10:2181,192.168.3.11:2181"
hostname="192.168.3.10"
sync="local_disk"
zkPath="/activemq/leveldb-stores"/>
</persistenceAdapter>
将apache-activemq-5.13.复制到11,12机器
wzh@hd-master:~/amq$ scp -r apache-activemq-5.13.0/ wzh@192.168.3.11:/tmp
修改配置文件中的hostname="192.168.3.11"
修改配置文件中的hostname="192.168.3.12"
(3)启动ActiveMQ
wzh@hd-master:~/amq$ ./apache-activemq-5.13.0/bin/activemq status INFO: Loading '/home/wzh/amq/apache-activemq-5.13.0//bin/env' INFO: Using java '/opt/java/jdk1.8.0_91/bin/java' ActiveMQ is running (pid '2031') wzh@hd-master:~/amq$
依次启动192.168.3.11,192.168.3.12机器
4:集群管理
(1)通过使用ZooInspector工具查看zookeeper集群情况

(2)http://192.168.3.10:8161/admin/ 默认用户名与口令为admin登录ActiveMQ管理端
5、通过Spring-boot操作ActiveMQ JMS
(1)通过gradle构建Spring-boot应用,在 gradle文件中增加
dependencies {
compile('org.springframework.boot:spring-boot-starter-activemq')
compile('org.springframework.boot:spring-boot-starter-web')
testCompile('org.springframework.boot:spring-boot-starter-test')
}
(2)application中增加以下配置
spring.activemq.broker-url=failover:(tcp://192.168.3.10:61616,tcp://192.168.3.11:61616,tcp://192.168.3.12:61616) spring.activemq.in-memory=true spring.activemq.pool.enabled=false spring.activemq.user=admin spring.activemq.password=admin
(3)JMS消息发送
@Service
public class Producer {
@Autowired
private JmsMessagingTemplate jmsTemplate;
public void sendMessage(Destination destination, final String message){
jmsTemplate.convertAndSend(destination, message);
}
}
(4)JMS消息接收
@Component
public class Consumer {
@JmsListener(destination = "test.queue")
public void receiveQueue(String text){
System.out.println("Consumer收到的报文为:"+text);
}
}
(5)测试
@RestController
@RequestMapping(
value = "/test",
headers = "Accept=application/json",
produces = "application/json;charset=utf-8"
)
public class TestCtrl {
@Autowired
Producer producer;
Destination destination = new ActiveMQQueue("test.queue");
@RequestMapping(
value = "/say/{msg}/to/{name}",
method = RequestMethod.GET
)
public Map<String, Object> say(@PathVariable String msg, @PathVariable String name){
Map<String, Object> map = new HashMap<>();
map.put("msg", msg);
map.put("name", name);
producer.sendMessage(destination, msg);
return map;
}
}
(6)进入ActiveMQ管理控制台创建一个消息队列
test.queue

(7)通过POSTMAN进行测试
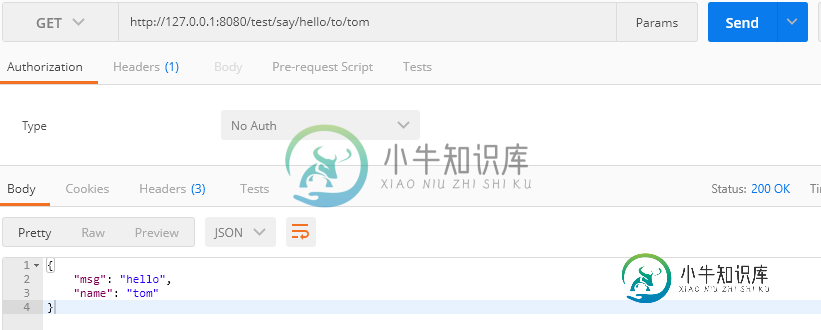
2017-08-03 08:10:44.928 INFO 12820 --- [ActiveMQ Task-3] o.a.a.t.failover.FailoverTransport : Successfully reconnected to tcp://192.168.3.10:61616
2017-08-03 08:11:08.854 INFO 12820 --- [ActiveMQ Task-1] o.a.a.t.failover.FailoverTransport : Successfully connected to tcp://192.168.3.10:61616
Consumer收到的报文为:hello
2017-08-03 08:43:39.464 INFO 12820 --- [ActiveMQ Task-1] o.a.a.t.failover.FailoverTransport : Successfully connected to tcp://192.168.3.10:61616
Consumer收到的报文为:hello
(8)目前系统连接的是10,如果此时将10集群Down掉,系统会理解选择一台slave作为master提供服务,从而启动案例主备的效果。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
本文演示环境是在同一台服务器上部署。因为docker创建容器时默认采用bridge网络,会自行分配ip,不允许指定,重启容器会导致ip变更。所以我们需要创建自定义的bridge网络,这样创建容器的时候才能指定ip。 创建自定义网络 #创建一个新的bridge网络adnc_net docker network create --driver bridge --subnet=172.20.0.0/16
-
一、Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群。 1.1 下载 & 解压 下载对应版本 Zookeeper,这里我下载的版本 3.4.14。官方下载地址:https://archive.apache.org/dist/zookeeper/ # 下载 wget https://archive.apache.
-
一、集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务。同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop002 和 hadoop003 上分别部署备用的 Master 服务,Master 服务由 Zookeeper 集群进行协调管理,如果主 Master 不可用,则备用 Master 会成为新的主 Mas
-
一、高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求比 YARN ResourceManger 高得多,所以它的实现也更加复杂,故下面先进行讲解: 1.1 高可用整体架构 HDFS 高可用架构如下: 图片引用自:https://www.edureka.
-
本文向大家介绍基于Docker的MySQL主从复制环境搭建的实现步骤,包括了基于Docker的MySQL主从复制环境搭建的实现步骤的使用技巧和注意事项,需要的朋友参考一下 1. 前言 之前的程序架构可能是这样的一种形式: 当程序体量扩大后,我们进行扩展,可能会扩展多个后台服务实例,但数据库还是只有一个,所以系统的瓶颈还是在数据库上面,所以这次的主要任务就是对数据库进行扩展,主要形式为:扩展多台数据
-
本文向大家介绍MySQL5.6基于GTID的主从复制,包括了MySQL5.6基于GTID的主从复制的使用技巧和注意事项,需要的朋友参考一下 MySQL 5.6 的新特性之一,是加入了全局事务 ID (GTID) 来强化数据库的主备一致性,故障恢复,以及容错能力。 什么是GTID? 官方文档:http://dev.mysql.com/doc/refman/5.6/en/replication-gti