
理解zookeeper选举机制

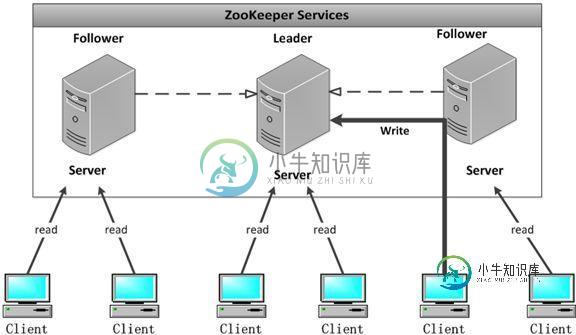
zookeeper集群
配置多个实例共同构成一个集群对外提供服务以达到水平扩展的目的,每个服务器上的数据是相同的,每一个服务器均可以对外提供读和写的服务,这点和redis是相同的,即对客户端来讲每个服务器都是平等的。
这篇主要分析leader的选择机制,zookeeper提供了三种方式:
- LeaderElection
- AuthFastLeaderElection
- FastLeaderElection
默认的算法是FastLeaderElection,所以这篇主要分析它的选举机制。
选择机制中的概念
服务器ID
比如有三台服务器,编号分别是1,2,3。
编号越大在选择算法中的权重越大。
数据ID
服务器中存放的最大数据ID.
值越大说明数据越新,在选举算法中数据越新权重越大。
逻辑时钟
或者叫投票的次数,同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加,然后与接收到的其它服务器返回的投票信息中的数值相比,根据不同的值做出不同的判断。
选举状态
- LOOKING,竞选状态。
- FOLLOWING,随从状态,同步leader状态,参与投票。
- OBSERVING,观察状态,同步leader状态,不参与投票。
- LEADING,领导者状态。
选举消息内容
在投票完成后,需要将投票信息发送给集群中的所有服务器,它包含如下内容。
- 服务器ID
- 数据ID
- 逻辑时钟
- 选举状态
选举流程图
因为每个服务器都是独立的,在启动时均从初始状态开始参与选举,下面是简易流程图。
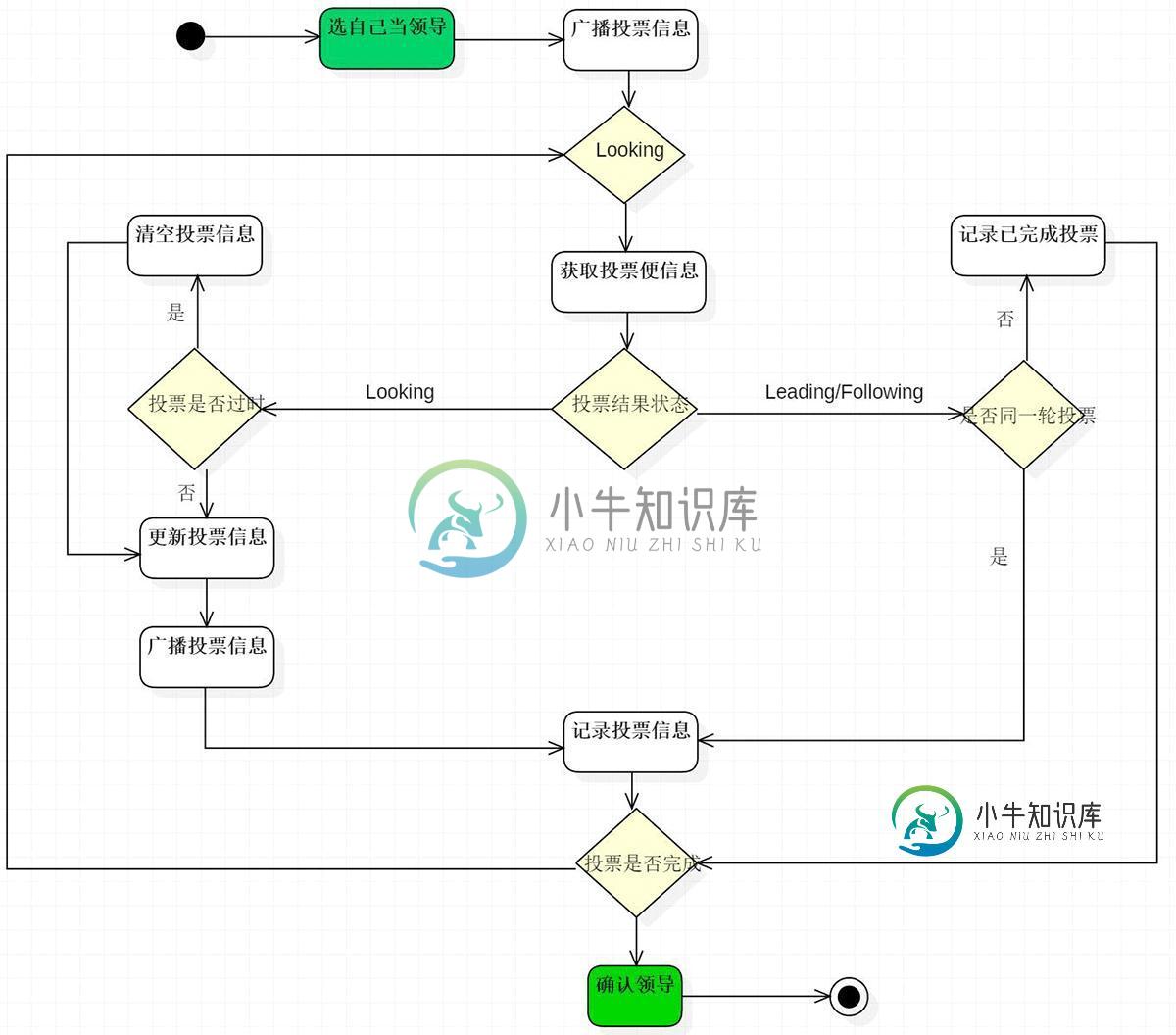
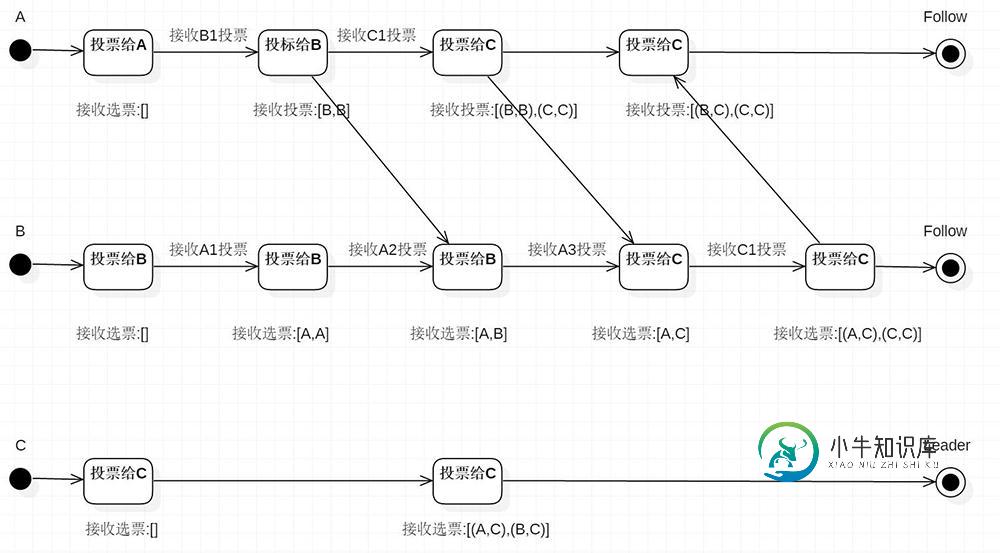
选举状态图
描述Leader选择过程中的状态变化,这是假设全部实例中均没有数据,假设服务器启动顺序分别为:A,B,C。
源码分析
QuorumPeer
主要看这个类,只有LOOKING状态才会去执行选举算法。每个服务器在启动时都会选择自己做为领导,然后将投票信息发送出去,循环一直到选举出领导为止。
public void run() {
//.......
try {
while (running) {
switch (getPeerState()) {
case LOOKING:
if (Boolean.getBoolean("readonlymode.enabled")) {
//...
try {
//投票给自己...
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
//...
} finally {
//...
}
} else {
try {
//...
setCurrentVote(makeLEStrategy().lookForLeader());
} catch (Exception e) {
//...
}
}
break;
case OBSERVING:
//...
break;
case FOLLOWING:
//...
break;
case LEADING:
//...
break;
}
}
} finally {
//...
}
}
FastLeaderElection
它是zookeeper默认提供的选举算法,核心方法如下:具体的可以与本文上面的流程图对照。
public Vote lookForLeader() throws InterruptedException { //... try { HashMap<Long, Vote> recvset = new HashMap<Long, Vote>(); HashMap<Long, Vote> outofelection = new HashMap<Long, Vote>(); int notTimeout = finalizeWait; synchronized(this){ //给自己投票 logicalclock.incrementAndGet(); updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch()); } //将投票信息发送给集群中的每个服务器 sendNotifications(); //循环,如果是竞选状态一直到选举出结果 while ((self.getPeerState() == ServerState.LOOKING) && (!stop)){ Notification n = recvqueue.poll(notTimeout, TimeUnit.MILLISECONDS); //没有收到投票信息 if(n == null){ if(manager.haveDelivered()){ sendNotifications(); } else { manager.connectAll(); } //... } //收到投票信息 else if (self.getCurrentAndNextConfigVoters().contains(n.sid)) { switch (n.state) { case LOOKING: // 判断投票是否过时,如果过时就清除之前已经接收到的信息 if (n.electionEpoch > logicalclock.get()) { logicalclock.set(n.electionEpoch); recvset.clear(); //更新投票信息 if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, getInitId(), getInitLastLoggedZxid(), getPeerEpoch())) { updateProposal(n.leader, n.zxid, n.peerEpoch); } else { updateProposal(getInitId(), getInitLastLoggedZxid(), getPeerEpoch()); } //发送投票信息 sendNotifications(); } else if (n.electionEpoch < logicalclock.get()) { //忽略 break; } else if (totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)) { //更新投票信息 updateProposal(n.leader, n.zxid, n.peerEpoch); sendNotifications(); } recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch)); //判断是否投票结束 if (termPredicate(recvset, new Vote(proposedLeader, proposedZxid, logicalclock.get(), proposedEpoch))) { // Verify if there is any change in the proposed leader while((n = recvqueue.poll(finalizeWait, TimeUnit.MILLISECONDS)) != null){ if(totalOrderPredicate(n.leader, n.zxid, n.peerEpoch, proposedLeader, proposedZxid, proposedEpoch)){ recvqueue.put(n); break; } } if (n == null) { self.setPeerState((proposedLeader == self.getId()) ? ServerState.LEADING: learningState()); Vote endVote = new Vote(proposedLeader, proposedZxid, proposedEpoch); leaveInstance(endVote); return endVote; } } break; case OBSERVING: //忽略 break; case FOLLOWING: case LEADING: //如果是同一轮投票 if(n.electionEpoch == logicalclock.get()){ recvset.put(n.sid, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch)); //判断是否投票结束 if(termPredicate(recvset, new Vote(n.leader, n.zxid, n.electionEpoch, n.peerEpoch, n.state)) && checkLeader(outofelection, n.leader, n.electionEpoch)) { self.setPeerState((n.leader == self.getId()) ? ServerState.LEADING: learningState()); Vote endVote = new Vote(n.leader, n.zxid, n.peerEpoch); leaveInstance(endVote); return endVote; } } //记录投票已经完成 outofelection.put(n.sid, new Vote(n.leader, IGNOREVALUE, IGNOREVALUE, n.peerEpoch, n.state)); if (termPredicate(outofelection, new Vote(n.leader, IGNOREVALUE, IGNOREVALUE, n.peerEpoch, n.state)) && checkLeader(outofelection, n.leader, IGNOREVALUE)) { synchronized(this){ logicalclock.set(n.electionEpoch); self.setPeerState((n.leader == self.getId()) ? ServerState.LEADING: learningState()); } Vote endVote = new Vote(n.leader, n.zxid, n.peerEpoch); leaveInstance(endVote); return endVote; } break; default: //忽略 break; } } else { LOG.warn("Ignoring notification from non-cluster member " + n.sid); } } return null; } finally { //... } }
判断是否已经胜出
默认是采用投票数大于半数则胜出的逻辑。
选举流程简述
目前有5台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5,按编号依次启动,它们的选择举过程如下:
- 服务器1启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器1的状态一直属于Looking。
- 服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,由于服务器2的编号大所以服务器2胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是LOOKING。
- 服务器3启动,给自己投票,同时与之前启动的服务器1,2交换信息,由于服务器3的编号最大所以服务器3胜出,此时投票数正好大于半数,所以服务器3成为领导者,服务器1,2成为小弟。
- 服务器4启动,给自己投票,同时与之前启动的服务器1,2,3交换信息,尽管服务器4的编号大,但之前服务器3已经胜出,所以服务器4只能成为小弟。
- 服务器5启动,后面的逻辑同服务器4成为小弟。
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持小牛知识库!
-
主要内容:1.Leader 的选举机制,2.投票 vote 的数据结构ZooKeeper 集群中的三个服务器角色:、 和 。其中,Leader 选举是 ZooKeeper 中最重要的技术之一,也是保证分布式数据一致性的关键所在。 而paxos算法中的角色为, , raft算法中的角色为, , 1.Leader 的选举机制 Zookeeper 在配置文件中并没有指定 和 。但是,Zookeeper 工作时, 是有一个节点为 ,其他则为 ,而这个 Leader 是通过内
-
zookeeper 的 leader 选举存在两个阶段,一个是服务器启动时 leader 选举,另一个是运行过程中 leader 服务器宕机。在分析选举原理前,先介绍几个重要的参数。 服务器 ID(myid):编号越大在选举算法中权重越大 事务 ID(zxid):值越大说明数据越新,权重越大 逻辑时钟(epoch-logicalclock):同一轮投票过程中的逻辑时钟值是相同的,每投完一次值会增加
-
本文向大家介绍Zookeeper 如何选举master 主节点?相关面试题,主要包含被问及Zookeeper 如何选举master 主节点?时的应答技巧和注意事项,需要的朋友参考一下 还记得上面我们的所说的临时节点吗?因为 的强一致性,能够很好地在保证 在高并发的情况下保证节点创建的全局唯一性 (即无法重复创建同样的节点)。 利用这个特性,我们可以 让多个客户端创建一个指定的节点 ,创建成功的就是
-
我很难理解领导者、追随者机制是如何工作的,比如说,我正在构建一个分布式应用程序,其中有2个主节点、6个从节点和3个zookeeper节点,其中一个zookeeper节点是领导者,两个主节点中的1个是活动的,并连接到zookeeper领导者。 我的问题是 > 当管理员节点死亡时,是否会发生领导者选举机制?以及它将如何影响我们的主人,我们的主人是否会与新当选的领导人连接? 如果我们的应用程序的主节点死
-
出于特殊原因,我需要同时使用 (又名高级消费者)和 (又名低级消费者)来读取 Kafka。对于 ,我使用基于 ZooKeeper 的配置,并且对此完全满意,但 需要实例化种子代理。 我不想同时保留动物园管理员和经纪人主机的列表。因此,我正在寻找一种方法,从ZooKeeper中自动发现特定主题的经纪人。 由于一些间接的信息,我相信这些数据存储在ZooKeeper中的以下路径之一: < li > <代
-
主要内容:实例zookeeper 的 watcher 机制,可以分为四个过程: 客户端注册 watcher。 服务端处理 watcher。 服务端触发 watcher 事件。 客户端回调 watcher。 其中客户端注册 watcher 有三种方式,调用客户端 API 可以分别通过 getData、exists、getChildren 实现,利用前面章节创建的 maven 工程,新建 WatcherDemo 类