
KMeans讲讲,KMeans有什么缺点,K怎么确定

参考回答:
在k-means算法中,用质心来表示cluster;且容易证明k-means算法收敛等同于所有质心不再发生变化。基本的k-means算法流程如下:
选取k个初始质心(作为初始cluster);
repeat: 对每个样本点,计算得到距其最近的质心,将其类别标为该质心所对应的cluster; 重新计算k个cluser对应的质心;
until 质心不再发生变化
k-means存在缺点:
1)k-means是局部最优的,容易受到初始质心的影响;比如在下图中,因选择初始质心不恰当而造成次优的聚类结果。
2)同时,k值的选取也会直接影响聚类结果,最优聚类的k值应与样本数据本身的结构信息相吻合,而这种结构信息是很难去掌握,因此选取最优k值是非常困难的。
K值得确定:
法1:(轮廓系数)在实际应用中,由于Kmean一般作为数据预处理,或者用于辅助分聚类贴标签。所以k一般不会设置很大。可以通过枚举,令k从2到一个固定值如10,在每个k值上重复运行数次kmeans(避免局部最优解),并计算当前k的平均轮廓系数,最后选取轮廓系数最大的值对应的k作为最终的html" target="_blank">集群数目。
法2:(Calinski-Harabasz准则)

其中SSB是类间方差, ,m为所有点的中心点,mi为某类的中心点;
,m为所有点的中心点,mi为某类的中心点;
SSW是类内方差,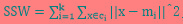 ;
;
(N-k)/(k-1)是复杂度;
 比率越大,数据分离度越大。
比率越大,数据分离度越大。
-
本文向大家介绍Kmeans相关面试题,主要包含被问及Kmeans时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 基本K-Means算法的思想很简单,事先确定常数K,常数K意味着最终的聚类类别数,首先随机选定初始点为质心,并通过计算每一个样本与质心之间的相似度(这里为欧式距离),将样本点归到最相似的类中,接着,重新计算每个类的质心(即为类中心),重复这样的过程,知道质心不再改变,最终就确定了
-
KMeans KMeans是一种简单的聚类算法,将数据集划分为多个簇,K为簇的个数。传统的KMeans算法,有一定的性能瓶颈,通过PS实现的KMeans,在准确率一致的情况下,性能更佳。 1. 算法介绍 每个样本被划分到距离最近的簇。每个簇所有样本的几何中心为这个簇的簇心,样本到簇心的距离为样本到簇的距离。Kmeans算法一般以迭代的方式训练,如下所示: 其中:代表第i个样本,代表与第i个样本距离
-
kmeans 算法,即k 均值聚类算法(k-means clustering algorithm),是一种迭代求解的聚类分析算法。其步骤是,预将数据分为 K 组,则随机选取 K 个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个
-
本文向大家介绍请你讲讲什么是泛型?相关面试题,主要包含被问及请你讲讲什么是泛型?时的应答技巧和注意事项,需要的朋友参考一下 考察点:JAVA泛型 泛型,即“参数化类型”。一提到参数,最熟悉的就是定义方法时有形参,然后调用此方法时传递实参。那么参数化类型怎么理解呢?顾名思义,就是将类型由原来的具体的类型参数化,类似于方法中的变量参数,此时类型也定义成参数形式(可以称之为类型形参),然后在使用/调用时
-
本文向大家介绍iframe是什么?有什么缺点?相关面试题,主要包含被问及iframe是什么?有什么缺点?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 定义:iframe元素会创建包含另一个文档的内联框架 提示:可以将提示文字放在之间,来提示某些不支持iframe的浏览器 缺点: 会阻塞主页面的onload事件 搜索引擎无法解读这种页面,不利于SEO iframe和主页面共享连接池,而浏览
-
算法介绍 K-Means又名为K均值算法,他是一个聚类算法,这里的K就是聚簇中心的个数,代表数据中存在多少数据簇。K-Means在聚类算法中算是非常简单的一个算法了。有点类似于KNN算法,都用到了距离矢量度量,用欧式距离作为小分类的标准。 算法步骤 (1)、设定数字k,从n个初始数据中随机的设置k个点为聚类中心点。 (2)、针对n个点的每个数据点,遍历计算到k个聚类中心点的距离,最后按照离哪个中心