
在决策树中查找到决策边界的距离

我想在scikit-learn中找到样本到经过训练的决策树分类器的决策边界的距离。特征都是数字的,特征空间可以是任何大小。
到目前为止,我已经基于此处的示例2D案例获得了这种可视化效果:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_moons
# Generate some example data
X, y = make_moons(noise=0.3, random_state=0)
# Train the classifier
clf = DecisionTreeClassifier(max_depth=2)
clf.fit(X, y)
# Plot
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.1), np.arange(y_min, y_max, 0.1))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.4)
plt.scatter(X[:, 0], X[:, 1], c=y, s=20, edgecolor='k')
plt.xlabel('a'); plt.ylabel('b');
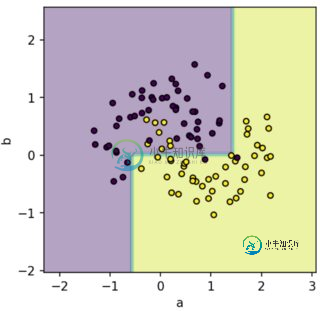
据我所知,对于某些其它分类像SVM,该距离可以在数学上计算[
1,2,3
]。训练决策树后学到的规则定义的界限,也可能是有用的算法计算出的距离[
4,5,6 ]:
# Plot the trained tree
from sklearn import tree
import graphviz
dot_data = tree.export_graphviz(clf, feature_names=['a', 'b'], class_names=['1', '2'], filled=True)
graph = graphviz.Source(dot_data)
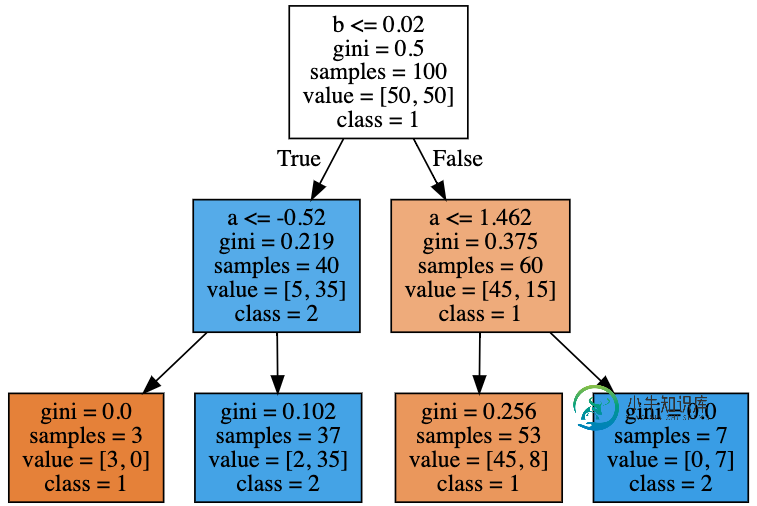
问题答案:
由于一个样本周围可能有多个决策边界,因此我将假设距离是指到最近决策边界的距离。
解决方案是递归树遍历算法。请注意,决策树不允许样本位于边界上,例如SVM,要素空间中的每个样本都必须属于其中一个类。因此,在这里,我们将继续一步一步地修改样本的特征,并且只要该区域导致一个带有不同标签的区域(而不是经过训练的分类器最初分配给该样本的区域),我们就认为我们已经达到了决策边界。
详细地说,像任何递归算法一样,我们要考虑两种主要情况:
- 基本情况,即我们在叶节点。我们只需检查当前样本是否具有不同的标签:如果是,则返回它,否则返回
None。 - 非叶节点。有两个分支,我们将样本发送到两个分支。我们不会修改示例以将其发送到自然需要的分支。但是在将其发送到另一个分支之前,我们先查看节点的(特征,阈值)对,并修改样本的给定特征,使其恰好将其推向阈值的另一侧。
完整的python代码:
def f(node,x,orig_label):
global dt,tree
if tree.children_left[node]==tree.children_right[node]: #Meaning node is a leaf
return [x] if dt.predict([x])[0]!=orig_label else [None]
if x[tree.feature[node]]<=tree.threshold[node]:
orig = f(tree.children_left[node],x,orig_label)
xc = x.copy()
xc[tree.feature[node]] = tree.threshold[node] + .01
modif = f(tree.children_right[node],xc,orig_label)
else:
orig = f(tree.children_right[node],x,orig_label)
xc = x.copy()
xc[tree.feature[node]] = tree.threshold[node]
modif = f(tree.children_left[node],xc,orig_label)
return [s for s in orig+modif if s is not None]
这将返回给我们一系列导致标签不同的叶子的样品列表。我们现在要做的就是取最近的一个:
dt = DecisionTreeClassifier(max_depth=2).fit(X,y)
tree = dt.tree_
res = f(0,x,dt.predict([x])[0]) # 0 is index of root node
ans = np.min([np.linalg.norm(x-n) for n in res])
例如:
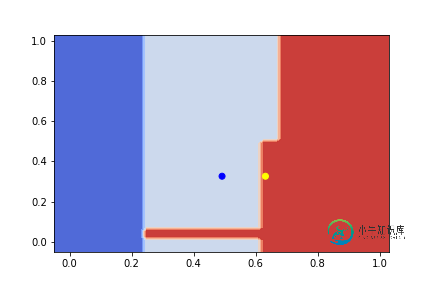
蓝色是原始样本,黄色是“在”决策边界上最近的样本。
-
问题内容: 我对matplotlib非常陌生,并且正在从事一些简单的项目以熟悉它。我想知道如何绘制决策边界,决策边界是[w1,w2]形式的权重向量,它使用matplotlib将两个类(例如C1和C2)基本分开。 如果是这样,是否像从(0,0)到点(w1,w2)画一条线一样简单(因为W是权重“向量”),如果需要,如何像在两个方向上一样进行扩展? 现在我要做的是: 提前致谢。 问题答案: 决策边界通常
-
决策树 概述 决策树(Decision Tree)算法是一种基本的分类与回归方法,是最经常使用的数据挖掘算法之一。我们这章节只讨论用于分类的决策树。 决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是 if-then 规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。 决策树学习通常包括 3 个步骤:特征选择、决策树的生成和决策树的修剪。 决策树 场景
-
决策树是一种常见的机器学习方法,它基于二元划分策略(类似于二叉树),如下图所示 一棵决策树包括一个根节点、若干个内部节点和若干个叶节点。叶节点对应决策的结果,而其他节点对应一个属性测试。决策树学习的目的就是构建一棵泛化能力强的决策树。决策树算法的优点包括 算法比较简单; 理论易于理解; 对噪声数据有很好的健壮性。 使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选
-
接下来就要讲决策树了,这是一类很简单但很灵活的算法。首先要考虑决策树所具有的非线性/基于区域(region-based)的本质,然后要定义和对比基于区域算则的损失函数,最后总结一下这类方法的具体优势和不足。讲完了这些基本内容之后,接下来再讲解通过决策树而实现的各种集成学习方法,这些技术很适合这些场景。 1 非线性(Non-linearity) 决策树是我们要讲到的第一种内在非线性的机器学习技术(i
-
和支持向量机一样, 决策树是一种多功能机器学习算法, 即可以执行分类任务也可以执行回归任务, 甚至包括多输出(multioutput)任务. 它是一种功能很强大的算法,可以对很复杂的数据集进行拟合。例如,在第二章中我们对加利福尼亚住房数据集使用决策树回归模型进行训练,就很好的拟合了数据集(实际上是过拟合)。 决策树也是随机森林的基本组成部分(见第 7 章),而随机森林是当今最强大的机器学习算法之一
-
{% raw %} 六、决策树 和支持向量机一样, 决策树是一种多功能机器学习算法, 即可以执行分类任务也可以执行回归任务, 甚至包括多输出(multioutput)任务. 它是一种功能很强大的算法,可以对很复杂的数据集进行拟合。例如,在第二章中我们对加利福尼亚住房数据集使用决策树回归模型进行训练,就很好的拟合了数据集(实际上是过拟合)。 决策树也是随机森林的基本组成部分(见第 7 章),而随机森
-
校验者: @文谊 @皮卡乒的皮卡乓 翻译者: @I Remember Decision Trees (DTs) 是一种用来 classification 和 regression 的无参监督学习方法。其目的是创建一种模型从数据特征中学习简单的决策规则来预测一个目标变量的值。 例如,在下面的图片中,决策树通过if-then-else的决策规则来学习数据从而估测数一个正弦图像。决策树越深入,决策规则就
-
我需要做一个决策树,并通过图形上的标签来表示数据(如两个插图所示)。我对决策树没有问题,不幸的是,点没有输入图形中。我尝试了代码中的几个变化。代码来自Scikit Learning网站在iris数据集上绘制决策树的决策面 下面有一个使用的数据示例(X、Y、C5)(来自Excel文件): 输出[]:[8.0、9.0、9.0、9.0、9.0、10.0、10.0、11.0、11.0、11.0、11.0、