
MNIST
LeNet 是一个用来识别手写数字的最经典的卷积神经网络,是Yann LeCun在1998年设计并提出的,是早期卷积神经网络中最有代表性的试验系统之一,其论文是CNN领域的第一篇经典之作。
LeNet 网络模型框架
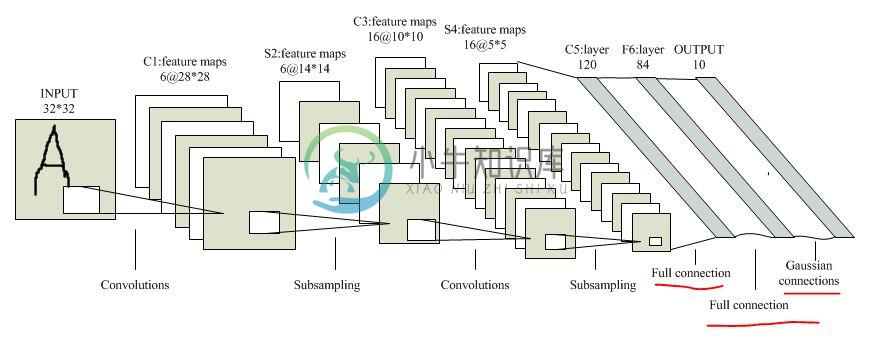
分层介绍
LeNet-5 包含输入层在内公有8层,每一层都包含多个参数(权重)。
- C 层代表卷积层,通过卷积操作,可以使原信号特征增强,并降低噪音。
- S 层是一个下采样层,利用图像局部相关性的原理,对图像进行子抽样,可以减少数据处理量,同时也可保留一定有用信息。
第1层
输入层是32x32大小的图像(Caffe中Mnist数据库为28x28),这样做的原因是希望潜在的明显特征,如笔画断续、角点能够出现在最高层特征监测子感受野的中心。
第2层
C1层是卷积层,6个feature map,5x5大小的卷积核,每个feature map大小为(32-5+1)x(32-5+1) = 28x28个神经元,每个神经元都与输入层的5x5大小的区域相连,故C1层共有(5x5+1)x6=156个训练参数,两层之间的连接数(5x5+1)x(28x28)x6=122304个。通过卷积运算,使原信号特征增强,并且降低噪音,不同的卷积核能够提取到图像中的不同特征。
第3层
S2层是一个下采样层,有6个14x14的feature map,每个feature map中的每个神经元都与都与C1层对应的feature map中的2x2区域相连。S2层中的每个神经元是由这4个输入相加,乘以一个训练参数,再加上feature map的偏置参数,结果通过sigmoid函数计算而得。S2的每一个feature map有14x14个神经元,参数个数为2x6=12个,连接数为(2x2+1)x(14x14)x6=5880个连接。下采样层的目的是为了降低网络训练参数及模型的过拟合度。下采样层的池化方式通常有两种:
- max pooling
- average pooling
第4层
C3层是卷积层,卷积核为5x5,神经元个数为(14-5+1)x(14-5+1)=10x10=100,有6个feature map,每个feature map由上一层S2的各feature map互相组合而成。
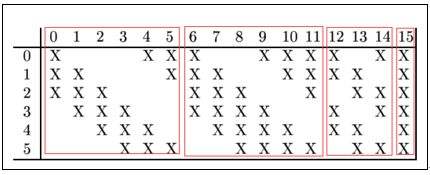
可以计算出:
- 训练参数个数:(5x5x3+1)x6+(5x5x4+1)x9+(5x5x6+1)x1=1516
- 连接数:训练参数个数x(10x10)=151600
第5层
S4 层是下采样层,由16个5x5大小的feature map构成,每个神经元与C3中对应的feature map的2x2大小的区域相连。
- 参数个数:2x16=32
- 连接数:(2x2+1)x(5x5)x16=2000
第6层
C5层是卷积层,使用5x5的卷积核,每个feature map有(5-5+1)x(5-5+1)=1x1=1个神经元,每个单元都与S4层的全部16个feature map的5x5区域全相连。
- 参数个数:(5x5x16+1)x120=48120
- 连接数:(5x5x16+1)x120=48120
第7层
F6层是全连接层,有84个feature map,每个feature map只有一个神经元与C5层全连接
- 参数个数:(1x1x120+1)x84=10164
- 连接数:(1x1x120+1)x84=10164.
第8层
这层是输出层,也是全连接层,共有10个节点,分别代表数字0到9,如果节点i的值是0,则网络识别的结果是数字i。
- 参数个数:(1x1x84)x10=840
- 连接数:(1x1x84)x10=840
采用的是径向基函数(RBF)的网络连接方式,RBF 的值由i的比特图编码确定,越接近 0,则越接近i的比特图编码,表示当前网络输入的识别结果是字符i。
下载MNIST数据集
- cd data/mnist
- ./get_mnist.sh
转换格式
下载到的原始数据集为二进制文件,需要转换为LEVELDB或者LMDB才能被caffe识别。
./examples/mnist/create_mnist.sh
训练超参数
使用caffe工具,指定-solver参数(指定求解器文本文件名):
./build/tools/caffe train --solver=examples/mnist/lenet_solver.prototxt
最终训练的模型权值保存在 examples/mnist/lenet_iter_10000 caffemodel 文件中,训练状态保存在examples/mnist/lenet_iter_10000.solverstate文件中,它们都是ProtoBuffer二进制格式文件。
使用训练好的模型进行预测
./build/tools/caffe test -model examples/mnist/lenet_train_test.prototxt -weights examples/mnist/lenet_iter_10000.caffemodel -iterations 100