
ConcurrentHashMap 导致的 Seata 死锁问题
- seata版本:1.4.0,但1.4以下的所有版本也都有这个问题
- 问题描述:在一个全局事务中,一个分支事务上的纯查询操作突然卡住了,没有任何反馈(日志/异常),直到消费端RPC超时

问题排查
- 整个流程在一个全局事务中,消费者和提供者可以看成是全局事务中的两个分支事务,消费者 --> 提供者
- 消费者先执行本地的一些逻辑,然后向提供者发送RPC请求,确定消费者发出了请求已经并且提供者接到了请求
- 提供者先打印一条日志,然后执行一条纯查询SQL,如果SQL正常执行会打印日志,但目前的现象是只打印了执行SQL前的那条日志,而没有打印任何SQL相关的日志。找DBA查SQL日志,发现该SQL没有执行
- 确定了该操作只是全局事务下的一个纯查询操作,在该操作之前,全局事务中的整体流程完全正常
- 其实到这里现象已经很明显了,不过当时想法没转变过来,一直关注那条查询SQL,总在想就算查询超时等原因也应该抛出异常啊,不应该什么都没有。DBA都找不到查询记录,那是不是说明SQL可能根本就没执行啊,而是在执行SQL前就出问题了,比如代理?
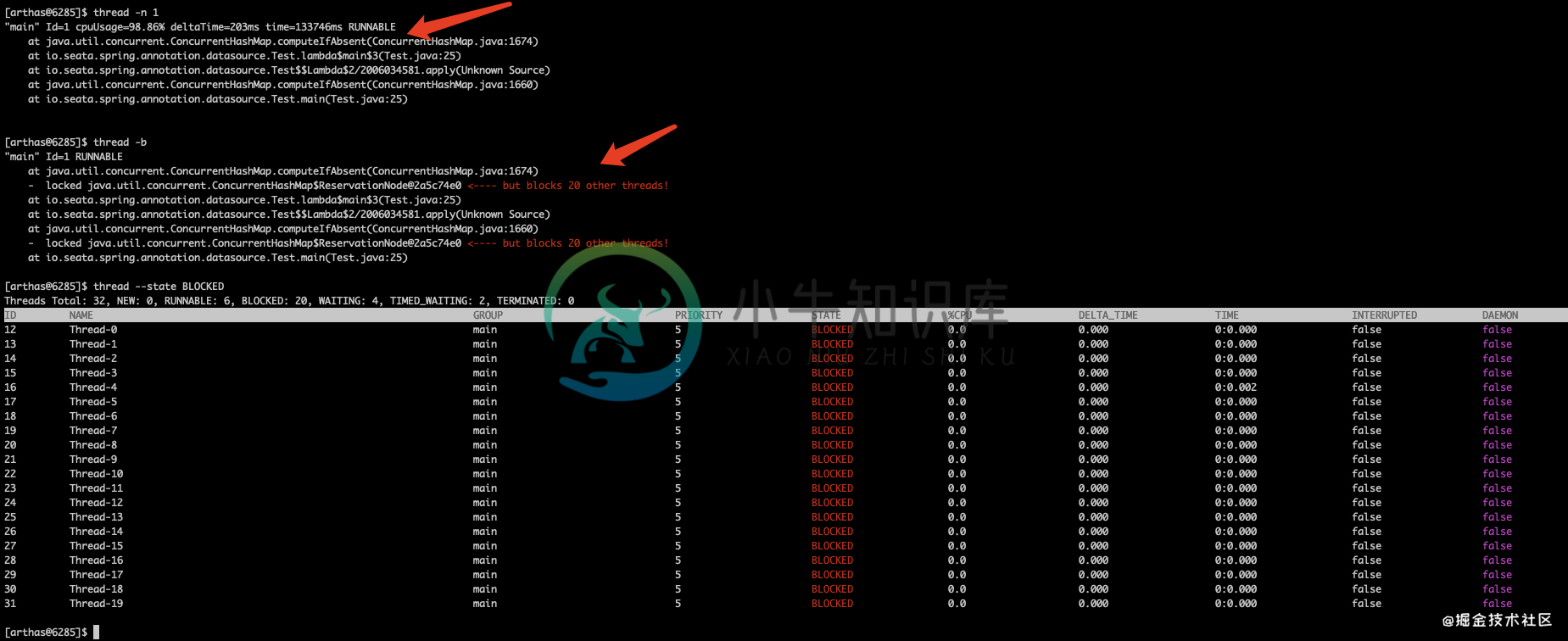
- 借助arthas的watch命令,一直没有东西输出。第一条日志的输出代表这个方法一定执行了,迟迟没有结果输出说明当前请求卡住了,为什么卡住了呢?
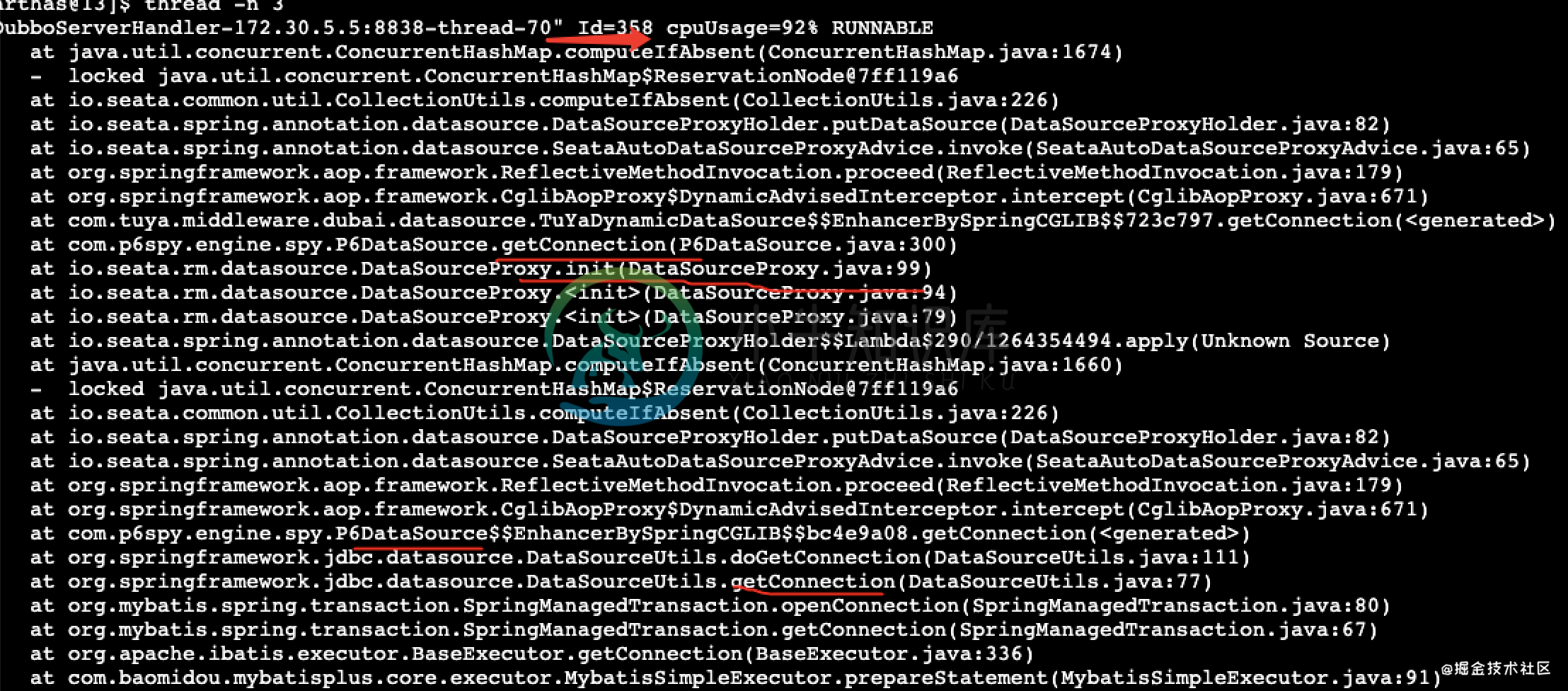
- 借助arthas的thread命令
thread -b、thread -n,就是要找出当前最忙的线程。这个效果很好,有一个线程CPU使用率92%,并且因为该线程导致其它20多个Dubbo线程BLOCKED了。堆栈信息如下 - 分析堆栈信息,已经可以很明显的发现和seata相关的接口了,估计和seata的数据源代理有关;同时发现CPU占用最高的那个线程卡在了
ConcurrentHashMap#computeIfAbsent方法中。难道ConcurrentHashMap#computeIfAbsent方法有bug? - 到这里,问题的具体原因我们还不知道,但应该和seata的数据源代理有点关系,具体原因我们需要分析业务代码和seata代码
问题分析
ConcurrentHashMap#computeIfAbsent
这个方法确实有可能出问题:如果两个key的hascode相同,并且在对应的mappingFunction中又进行了computeIfAbsent操作,则会导致死循环,具体分析参考这篇文章:https://juejin.cn/post/6844904191077384200
Seata数据源自动代理
相关内容之前有分析过,我们重点来看看以下几个核心的类:
- SeataDataSourceBeanPostProcessor
- SeataAutoDataSourceProxyAdvice
- DataSourceProxyHolder
SeataDataSourceBeanPostProcessor
SeataDataSourceBeanPostProcessor是BeanPostProcessor实现类,在postProcessAfterInitialization方法(即Bean初始化之后)中,会为业务方配置的数据源创建对应的seata代理数据源
public class SeataDataSourceBeanPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
if (bean instanceof DataSource) {
//When not in the excludes, put and init proxy.
if (!excludes.contains(bean.getClass().getName())) {
//Only put and init proxy, not return proxy.
DataSourceProxyHolder.get().putDataSource((DataSource) bean, dataSourceProxyMode);
}
//If is SeataDataSourceProxy, return the original data source.
if (bean instanceof SeataDataSourceProxy) {
LOGGER.info("Unwrap the bean of the data source," +
" and return the original data source to replace the data source proxy.");
return ((SeataDataSourceProxy) bean).getTargetDataSource();
}
}
return bean;
}
}
SeataAutoDataSourceProxyAdvice
SeataAutoDataSourceProxyAdvice是一个MethodInterceptor,seata中的SeataAutoDataSourceProxyCreator会针对DataSource类型的Bean创建动态代理对象,代理逻辑就是SeataAutoDataSourceProxyAdvice#invoke逻辑。即:执行数据源AOP代理对象的相关方法时候,会经过其invoke方法,在invoke方法中再根据当原生数据源,找到对应的seata代理数据源,最终达到执行seata代理数据源逻辑的目的
public class SeataAutoDataSourceProxyAdvice implements MethodInterceptor, IntroductionInfo {
......
@Override
public Object invoke(MethodInvocation invocation) throws Throwable {
if (!RootContext.requireGlobalLock() && dataSourceProxyMode != RootContext.getBranchType()) {
return invocation.proceed();
}
Method method = invocation.getMethod();
Object[] args = invocation.getArguments();
Method m = BeanUtils.findDeclaredMethod(dataSourceProxyClazz, method.getName(), method.getParameterTypes());
if (m != null) {
SeataDataSourceProxy dataSourceProxy = DataSourceProxyHolder.get().putDataSource((DataSource) invocation.getThis(), dataSourceProxyMode);
return m.invoke(dataSourceProxy, args);
} else {
return invocation.proceed();
}
}
}
DataSourceProxyHolder
流程上我们已经清楚了,现在还有一个问题,如何维护原生数据源和seata代理数据源之间的关系?通过DataSourceProxyHolder维护,这是一个单例对象,该对象中通过一个ConcurrentHashMap维护两者的关系:原生数据源为key --> seata代理数据源 为value
public class DataSourceProxyHolder {
public SeataDataSourceProxy putDataSource(DataSource dataSource, BranchType dataSourceProxyMode) {
DataSource originalDataSource = dataSource;
......
return CollectionUtils.computeIfAbsent(this.dataSourceProxyMap, originalDataSource,
BranchType.XA == dataSourceProxyMode ? DataSourceProxyXA::new : DataSourceProxy::new);
}
}
// CollectionUtils.java
public static <K, V> V computeIfAbsent(Map<K, V> map, K key, Function<? super K, ? extends V> mappingFunction) {
V value = map.get(key);
if (value != null) {
return value;
}
return map.computeIfAbsent(key, mappingFunction);
}
客户端数据源配置
- 配置了两个数据源:
DynamicDataSource、P6DataSource P6DataSource可以看成是对DynamicDataSource的一层包装- 我们暂时不去管这个配置合不合理,现在只是单纯的基于这个数据源配置分析问题
@Qualifier("dsMaster")
@Bean("dsMaster")
DynamicDataSource dsMaster() {
return new DynamicDataSource(masterDsRoute);
}
@Primary
@Qualifier("p6DataSource")
@Bean("p6DataSource")
P6DataSource p6DataSource(@Qualifier("dsMaster") DataSource dataSource) {
P6DataSource p6DataSource = new P6DataSource(dsMaster());
return p6DataSource;
}
分析过程
假设现在大家都已经知道了 ConcurrentHashMap#computeIfAbsent 可能会产生的问题,已知现在产生了这个问题,结合堆栈信息,我们可以知道大概哪里产生了这个问题。
1、ConcurrentHashMap#computeIfAbsent会产生这个问题的前提条件是:两个key的hashcode相同;mappingFunction中对应了一个put操作。结合我们seata的使用场景,mappingFunction对应的是DataSourceProxy::new,说明在DataSourceProxy的构造方法中可能会触发put操作
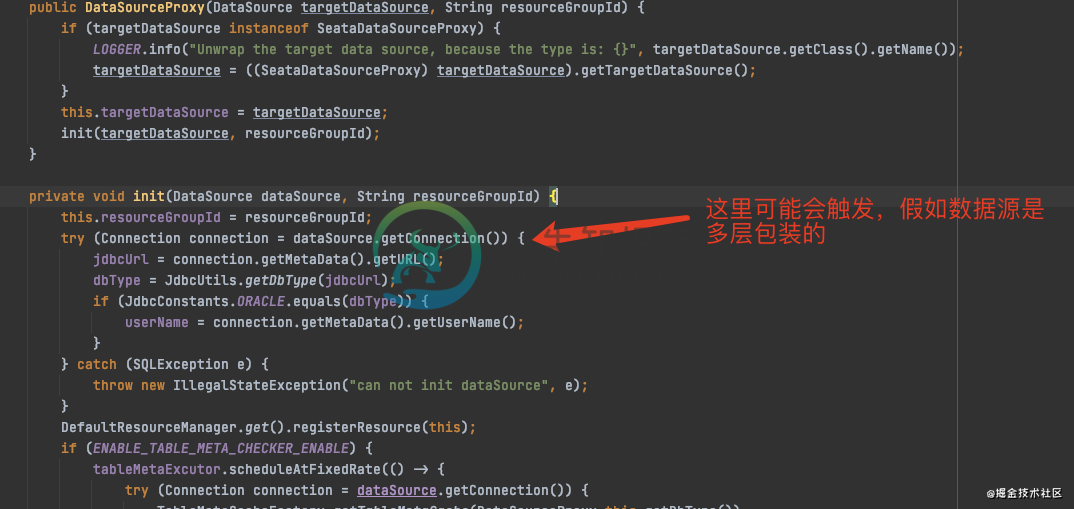
执行AOP代理数据源相关方法 =>
进入SeataAutoDataSourceProxyAdvice切面逻辑 =>
执行DataSourceProxyHolder#putDataSource方法 =>
执行DataSourceProxy::new =>
AOP代理数据源的getConnection方法 =>
原生数据源的getConnection方法 =>
进入SeataAutoDataSourceProxyAdvice切面逻辑 =>
执行DataSourceProxyHolder#putDataSource方法 =>
执行DataSourceProxy::new =>
DuridDataSource的getConnection方法
2、步骤1中说的AOP代理数据源和原生数据源分别是什么?看下面这张图 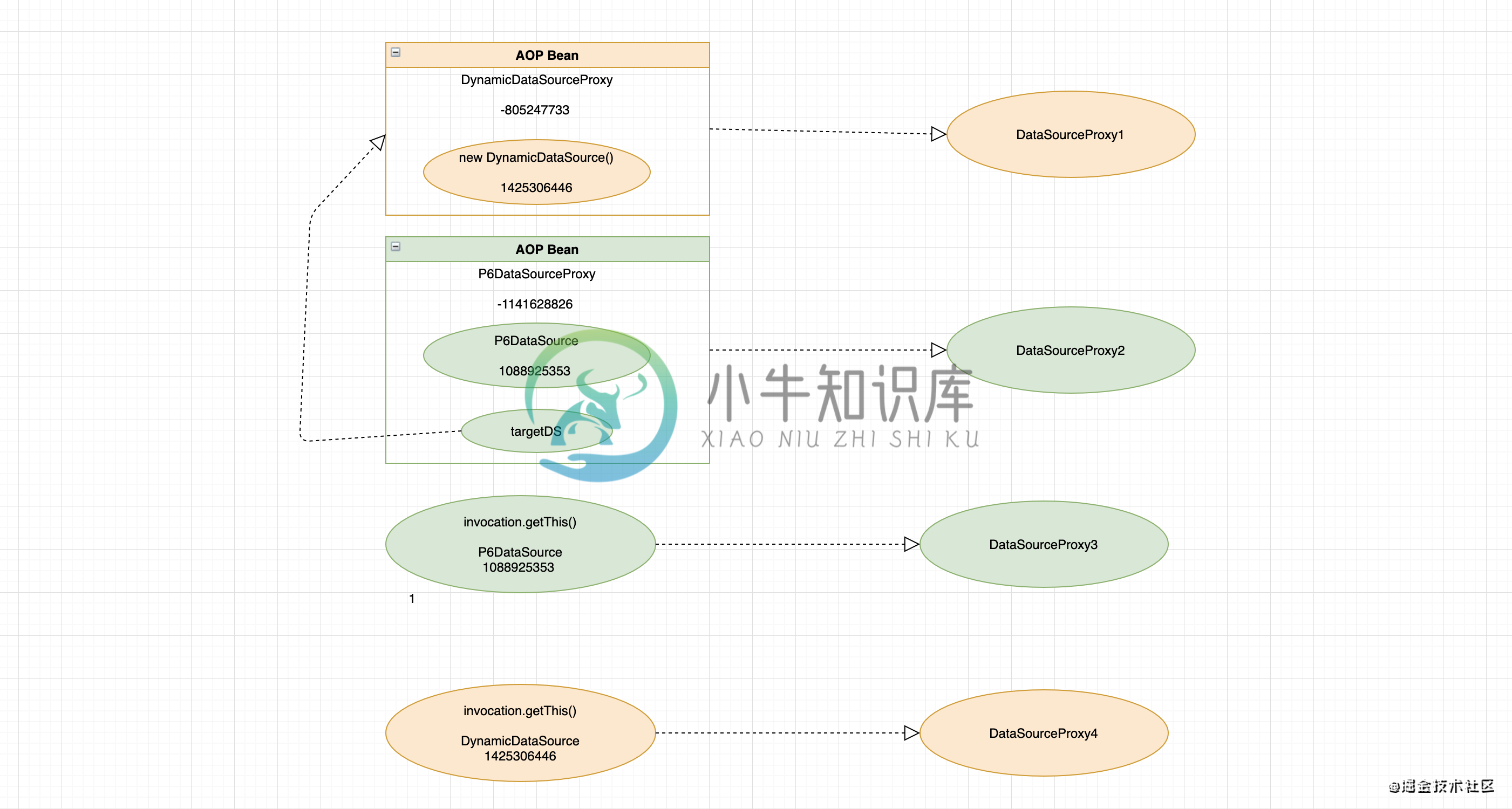
3、上面还说到了产生这个问题还有一个条件两个key的hashcode相同,但我看这两个数据源对象都没有重写hashcode方法,所以按理来说,这两个对象的hashcode一定是不同的。后面又再看了一遍ConcurrentHashMap这个问题,感觉两个key的hashcode相同这个说法是不对的,两个key会产生hash冲突更合理一些,这样就能解释两个hashcode不同的对象为啥会遇上这个问题了。为了证明这个,下面我给了一个例子
public class Test {
public static void main(String[] args) {
ConcurrentHashMap map = new ConcurrentHashMap(8);
Num n1 = new Num(3);
Num n2 = new Num(19);
Num n3 = new Num(20);
// map.computeIfAbsent(n1, k1 -> map.computeIfAbsent(n3, k2 -> 200)); // 这行代码不会导致程序死循环
map.computeIfAbsent(n1, k1 -> map.computeIfAbsent(n2, k2 -> 200)); // 这行代码会导致程序死循环
}
static class Num{
private int i;
public Num(int i){
this.i = i;
}
@Override
public int hashCode() {
return i;
}
}
}
- 为了方便重现问题,我们重写了
Num#hashCode方法,保证构造函数入参就是hashcode的值 - 创建一个ConcurrentHashMap对象,initialCapacity为8,sizeCtl计算出来的值为16,即该mao中数组长度默认为16
- 创建对象
n1,入参为3,即hashcode为3,计算得出其对应的数组下标为3 - 创建对象
n2,入参为19,即hashcode为19,计算得出其对应的数组下标为3,此时我们可以认为n1和n2产生了hash冲突 - 创建对象
n3,入参为20,即hashcode为20,计算得出其对应的数组下标为4 - 执行
map.computeIfAbsent(n1, k1 -> map.computeIfAbsent(n3, k2 -> 200)),程序正常退出:因为n1和n3没有hash冲突,所以正常结束 - 执行
map.computeIfAbsent(n1, k1 -> map.computeIfAbsent(n2, k2 -> 200)),程序正常退出:因为n1和n2产生了hash冲突,所以陷入死循环
4、在对象初始化的时候,SeataDataSourceBeanPostProcessor不是已经将对象对应的数据源代理初始化好了吗?为什么在SeataAutoDataSourceProxyAdvice中还是会创建对应的数据源代理呢?
- 首先,
SeataDataSourceBeanPostProcessor执行时期是晚于AOP代理对象创建的,所以在执行SeataDataSourceBeanPostProcessor相关方法的时候,SeataAutoDataSourceProxyAdvice其实应生效了 SeataDataSourceBeanPostProcessor中向map中添加元素时,key为AOP代理数据源;SeataAutoDataSourceProxyAdvice中的invocation.getThis()中拿到的是原生数据源,所以key不相同
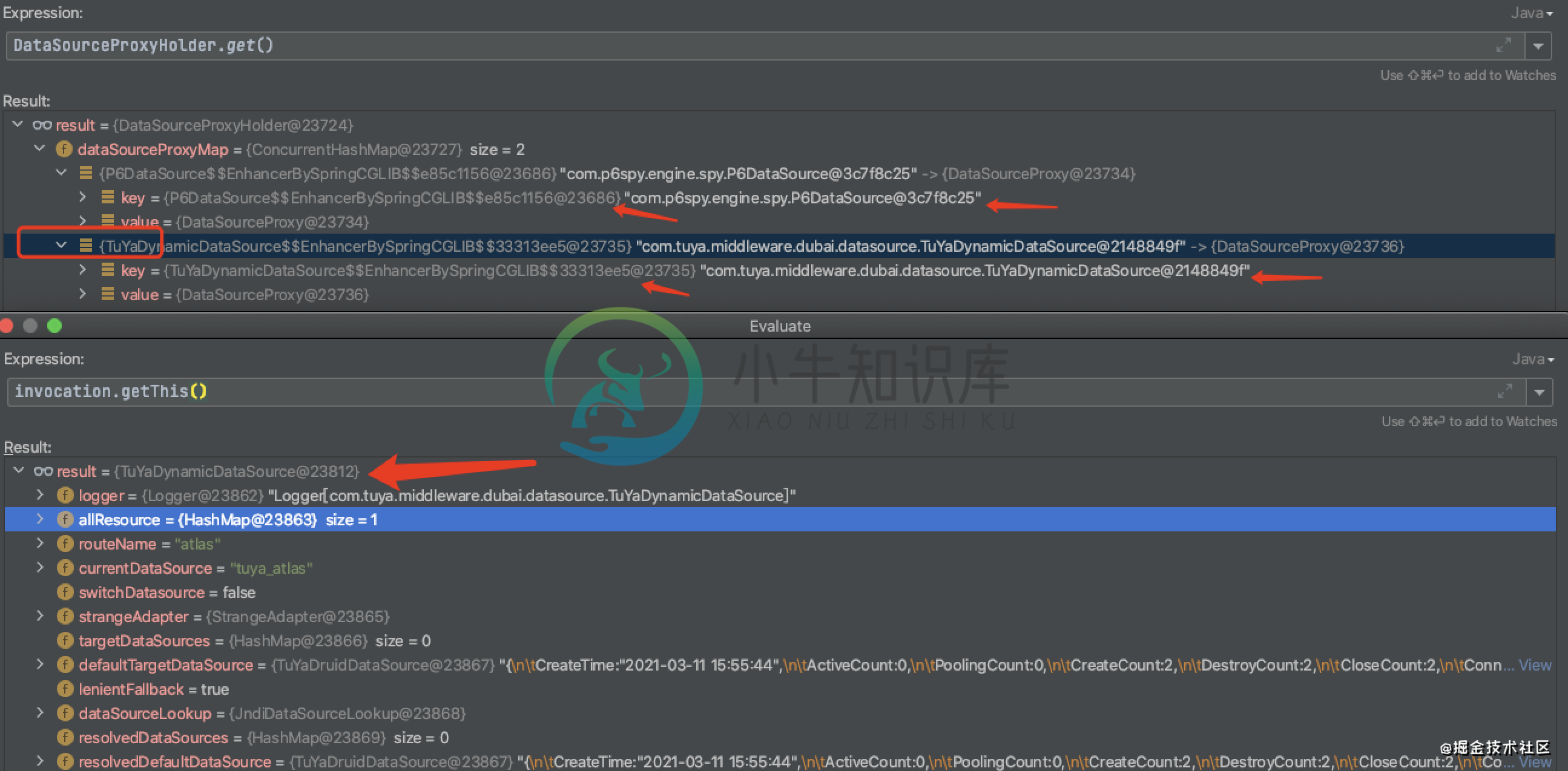
5、还有一个问题,SeataAutoDataSourceProxyAdvic#invoke方法中并没有过滤toString、hashCode等方法,cglib创建的代理对象默认会重写这几个方法,如果在向map中put元素的时候触发了代理对象的这些方法,此时又会重新进入SeataAutoDataSourceProxyAdvic#invoke切面,直到线程堆栈益处
问题总结
- 在两个key会产生hash冲突的时候,会触发
ConcurrentHashMap#computeIfAbsentBUG,该BUG的表现就是让当前线程陷入死循环 - 业务反馈,该问题是偶现的,偶现的原因有两种:首先,该应用是多节点部署,但线上只有一个节点触发了该BUG(hashcode冲突),所以只有当请求打到这个节点的时候才有可能会触发该BUG;其次,因为每次重启对象地址(hashcode)都是不确定的,所以并不是每次应用重启之后都会触发,但如果一旦触发,该节点就会一直存在这个问题。有一个线程一直在死循环,并将其它尝试从map中获取代理数据源的线程阻塞了,这种现象在业务上的反馈就是请求卡住了。如果连续请求都是这样,此时业务方可能会重启服务,然后
因为重启后hash冲突不一定存在,可能重启后业务表现就正常了,但也有可能在下次重启的时候又会触发了这个BUG - 当遇到这个问题时,从整个问题上来看,确实就是死锁了,因为那个死循环的线程占者锁一直不释放,导致其它操作该map的线程被BLOCK了
- 本质上还是因为
ConcurrentHashMap#computeIfAbsent方法可能会触发BUG,而seata的使用场景刚好就触发了该BUG - 下面这个demo其实就完整的模拟了线上出问题时的场景,如下:
public class Test {
public static void main(String[] args) {
ConcurrentHashMap map = new ConcurrentHashMap(8);
Num n1 = new Num(3);
Num n2 = new Num(19);
for(int i = 0; i< 20; i++){
new Thread(()-> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
map.computeIfAbsent(n1, k-> 200);
}).start();
}
map.computeIfAbsent(n1, k1 -> map.computeIfAbsent(n2, k2 -> 200));
}
static class Num{
private int i;
public Num(int i){
this.i = i;
}
@Override
public int hashCode() {
return i;
}
}
}
解决问题
可以从两方面解决这个问题:
- 业务方改动:P6DataSource 和 DynamicDataSource 没必要都被代理,直接代理P6DataSource就可以了,DynamicDataSource没有必要声明成一个Bean;或者通过excluds属性排除P6DataSource,这样就不会存在重复代理问题
- Seata完善:完善数据源代理相关逻辑
业务方改动
1、数据源相关的配置改成如下即可:
@Primary
@Qualifier("p6DataSource")
@Bean("p6DataSource")
P6DataSource p6DataSource(@Qualifier("dsMaster") DataSource dataSource) {
P6DataSource p6DataSource = new P6DataSource(new TuYaDynamicDataSource(masterDsRoute));
logger.warn("dsMaster={}, hashcode={}",p6DataSource, p6DataSource.hashCode());
return p6DataSource;
}
2、或者不改变目前的数据源配置,添加excluds属性
@EnableAutoDataSourceProxy(excludes={"P6DataSource"})
Seata完善
1、ConcurrentHashMap#computeIfAbsent方法改成双重检查,如下:
SeataDataSourceProxy dsProxy = dataSourceProxyMap.get(originalDataSource);
if (dsProxy == null) {
synchronized (dataSourceProxyMap) {
dsProxy = dataSourceProxyMap.get(originalDataSource);
if (dsProxy == null) {
dsProxy = createDsProxyByMode(dataSourceProxyMode, originalDataSource);
dataSourceProxyMap.put(originalDataSource, dsProxy);
}
}
}
return dsProxy;
之前我想直接改CollectionUtils#computeIfAbsent方法,群里大佬反馈这样可能会导致数据源多次创建,确实有这个问题:如下
public static <K, V> V computeIfAbsent(Map<K, V> map, K key, Function<? super K, ? extends V> mappingFunction) {
V value = map.get(key);
if (value != null) {
return value;
}
value = mappingFunction.apply(key);
return map.computeIfAbsent(key, value);
}
2、SeataAutoDataSourceProxyAdvice切面逻辑中添加一些过滤
Method m = BeanUtils.findDeclaredMethod(dataSourceProxyClazz, method.getName(), method.getParameterTypes());
if (m != null && DataSource.class.isAssignableFrom(method.getDeclaringClass())) {
SeataDataSourceProxy dataSourceProxy = DataSourceProxyHolder.get().putDataSource((DataSource) invocation.getThis(), dataSourceProxyMode);
return m.invoke(dataSourceProxy, args);
} else {
return invocation.proceed();
}
遗留问题
在SeataDataSourceBeanPostProcessor和SeataAutoDataSourceProxyAdvice对应方法中,向map中初始化seata数据源代理时对应的key根本就不同,SeataDataSourceBeanPostProcessor中对应的key是AOP代理数据源;SeataAutoDataSourceProxyAdvice中对应的key是原生对象,此时就造成了不必要的seata数据源代理对象的创建。
针对这个问题,大家有什么好的建议?能不能为SeataDataSourceBeanPostProcessor指定一个order,让其在创建AOP代理对象之前生效