
如何使用java从HTML文档中提取内容。(How to extract content from an HTML document using java.)
问题描述 (Problem Description)
如何使用java从HTML文档中提取内容。
解决方案 (Solution)
以下是使用java从HTML文档中提取内容的程序。
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.html.HtmlParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class ExtractContentFromHTMLDoc {
public static void main(String[] args) throws IOException,SAXException, TikaException {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File(
"C:/tika/htmlExample.html"));
ParseContext pcontext = new ParseContext();
//Html parser
HtmlParser htmlparser = new HtmlParser();
htmlparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + ": " + metadata.get(name));
}
}
}
输入 (Input)
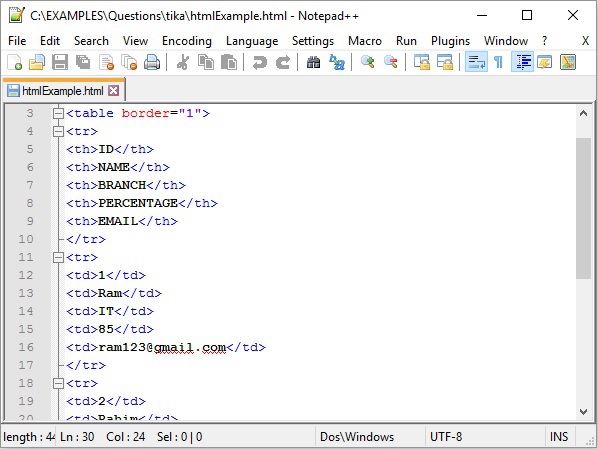
输出 (Output)
Contents of the document:Sheet1
ID NAME BRANCH PERCENTAGE EMAIL
1 Ram IT 85 ram123@gmail.com
2 Rahim EEE 95 rahim123@gmail.com
3 Robert ECE 90 robert123@gmail.com
Metadata of the document:
Content-Encoding: windows-1252 Content-Type: text/html; charset=windows-1252