
redis 分布式锁实现
背景
在很多互联网产品应用中,有些场景需要加锁处理,比如:秒杀,全局递增ID,楼层生成等等。大部分的解决方案是基于DB实现的,Redis为单进程单线程模式,采用队列模式将并发访问变成串行访问,且多客户端对redis的连接并不存在竞争关系。其次Redis提供一些命令SETNX,GETSET,可以方便实现分布式锁机制。
一、使用分布式锁要满足的几个条件:
- 系统是一个分布式系统(关键是分布式,单机的可以使用ReentrantLock或者synchronized代码块来实现)
- 共享资源(各个系统访问同一个资源,资源的载体可能是传统关系型数据库或者NoSQL)
- 同步访问(即有很多个进程同事访问同一个共享资源。没有同步访问,谁管你资源竞争不竞争)
二、应用的场景例子
管理后台的部署架构(多台tomcat服务器+redis【多台tomcat服务器访问一台redis】+mysql【多台tomcat服务器访问一台服务器上的mysql】)就满足使用分布式锁的条件。多台服务器要访问redis全局缓存的资源,如果不使用分布式锁就会出现问题。 看如下伪代码:
long N=0L; //N从redis获取值 if(N<5){ N++; //N写回redis }
上面的代码主要实现的功能:
从redis获取值N,对数值N进行边界检查,自加1,然后N写回redis中。 这种应用场景很常见,像秒杀,全局递增ID、IP访问限制等。以IP访问限制来说,恶意攻击者可能发起无限次访问,并发量比较大,分布式环境下对N的边界检查就不可靠,因为从redis读的N可能已经是脏数据。传统的加锁的做法(如java的synchronized和Lock)也没用,因为这是分布式环境,这个同步问题的救火队员也束手无策。在这危急存亡之秋,分布式锁终于有用武之地了。
分布式锁可以基于很多种方式实现,比如zookeeper、redis...。不管哪种方式,他的基本原理是不变的:用一个状态值表示锁,对锁的占用和释放通过状态值来标识。
这里主要讲如何用redis实现分布式锁。
三、使用redis的setNX命令实现分布式锁
- 、实现的原理
Redis为单进程单线程模式,采用队列模式将并发访问变成串行访问,且多客户端对Redis的连接并不存在竞争关系。redis的SETNX命令可以方便的实现分布式锁。
2、基本命令解析
1)setNX(SET if Not eXists)
语法:
SETNX key value
将 key 的值设为 value ,当且仅当 key 不存在。
若给定的 key 已经存在,则 SETNX 不做任何动作。
SETNX 是『SET if Not eXists』(如果不存在,则 SET)的简写
返回值:
设置成功,返回 1 。
设置失败,返回 0 。
例子:
redis> EXISTS job # job 不存在 (integer) 0 redis> SETNX job "programmer" # job 设置成功 (integer) 1 redis> SETNX job "code-farmer" # 尝试覆盖 job ,失败 (integer) 0 redis> GET job # 没有被覆盖 "programmer"
所以我们使用执行下面的命令
SETNX lock.foo <current Unix time + lock timeout + 1>
如返回1,则该客户端获得锁,把lock.foo的键值设置为时间值表示该键已被锁定,该客户端最后可以通过DEL lock.foo来释放该锁。
如返回0,表明该锁已被其他客户端取得,这时我们可以先返回或进行重试等对方完成或等待锁超时。
2)getSET
语法:
GETSET key value
将给定 key 的值设为 value,并返回 key 的旧值(old value)。
当 key 存在但不是字符串类型时,返回一个错误。
返回值:
返回给定 key 的旧值。
当 key 没有旧值时,也即是, key 不存在时,返回 nil 。
3)get
语法:
GET key
返回值:
当 key 不存在时,返回 nil ,否则,返回 key 的值。
如果 key 不是字符串类型,那么返回一个错误
四、解决死锁
上面的锁定逻辑有一个问题:如果一个持有锁的客户端失败或崩溃了不能释放锁,该怎么解决?
我们可以通过锁的键对应的时间戳来判断这种情况是否发生了,如果当前的时间已经大于lock.foo的值,说明该锁已失效,可以被重新使用。
发生这种情况时,可不能简单的通过DEL来删除锁,然后再SETNX一次(讲道理,删除锁的操作应该是锁拥有这执行的,这里只需要等它超时即可),当多个客户端检测到锁超时后都会尝试去释放它,这里就可能出现一个竞态条件,让我们模拟一下这个场景:
C0操作超时了,但它还持有着锁,C1和C2读取lock.foo检查时间戳,先后发现超时了。 C1 发送DEL lock.foo C1 发送SETNX lock.foo 并且成功了。 C2 发送DEL lock.foo C2 发送SETNX lock.foo 并且成功了。 这样一来,C1,C2都拿到了锁!问题大了!
幸好这种问题是可以避免的,让我们来看看C3这个客户端是怎样做的:
C3发送SETNX lock.foo 想要获得锁,由于C0还持有锁,所以Redis返回给C3一个0 C3发送GET lock.foo 以检查锁是否超时了,如果没超时,则等待或重试。 反之,如果已超时,C3通过下面的操作来尝试获得锁: GETSET lock.foo <current Unix time + lock timeout + 1> 通过GETSET,C3拿到的时间戳如果仍然是超时的,那就说明,C3如愿以偿拿到锁了。
如果在C3之前,有个叫C4的客户端比C3快一步执行了上面的操作,那么C3拿到的时间戳是个未超时的值,这时,C3没有如期获得锁,需要再次等待或重试。留意一下,尽管C3没拿到锁,但它改写了C4设置的锁的超时值,不过这一点非常微小的误差带来的影响可以忽略不计。
注意:为了让分布式锁的算法更稳键些,持有锁的客户端在解锁之前应该再检查一次自己的锁是否已经超时,再去做DEL操作,因为可能客户端因为某个耗时的操作而挂起,操作完的时候锁因为超时已经被别人获得,这时就不必解锁了
六、一些问题
1、为什么不直接使用expire设置超时时间,而将时间的毫秒数其作为value放在redis中?
如下面的方式,把超时的交给redis处理:
lock(key, expireSec){
isSuccess =
setnx key
if
(isSuccess)
expire key expireSec
}
这种方式貌似没什么问题,但是假如在setnx后,redis崩溃了,expire就没有执行,结果就是死锁了。锁永远不会超时。
2、为什么前面的锁已经超时了,还要用getSet去设置新的时间戳的时间获取旧的值,然后和外面的判断超时时间的时间戳比较呢?
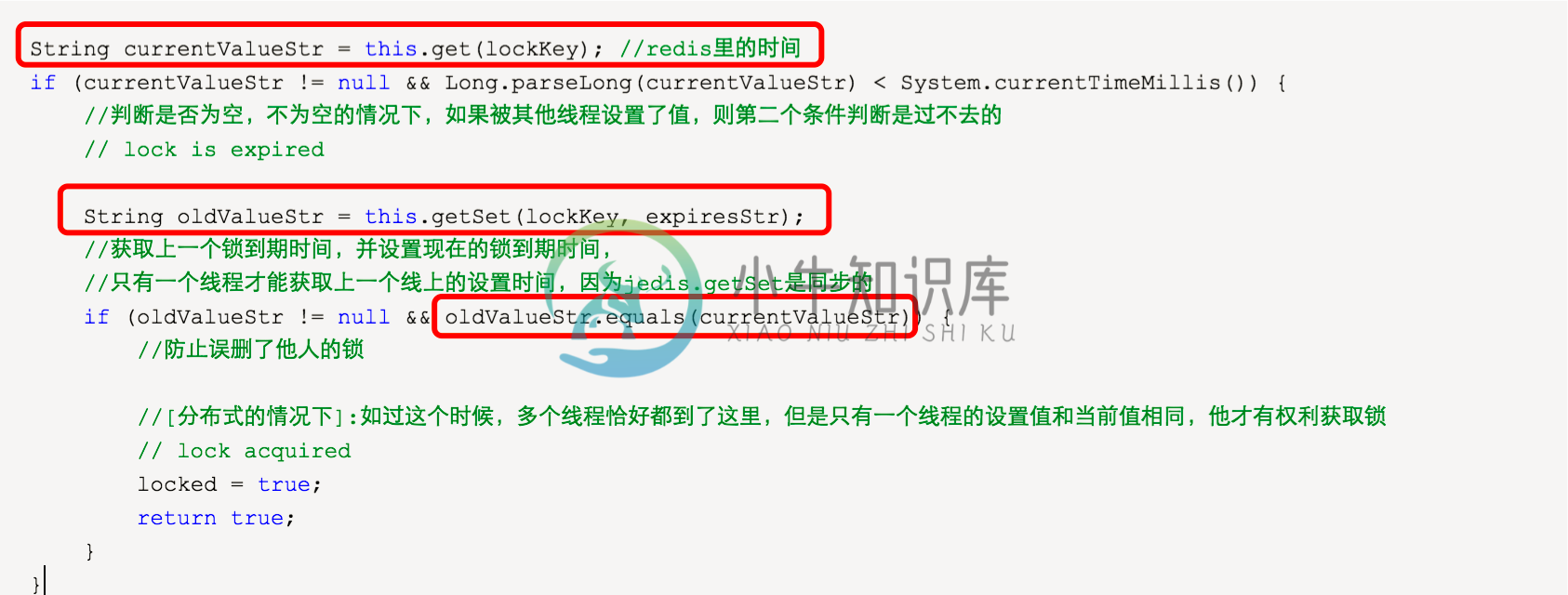 因为是分布式的环境下,可以在前一个锁失效的时候,有两个进程进入到锁超时的判断。如:
因为是分布式的环境下,可以在前一个锁失效的时候,有两个进程进入到锁超时的判断。如:
C0超时了,还持有锁,C1/C2同时请求进入了方法里面
C1/C2获取到了C0的超时时间
C1使用getSet方法
C2也执行了getSet方法
假如我们不加 oldValueStr.equals(currentValueStr) 的判断,将会C1/C2都将获得锁,加了之后,能保证C1和C2只能一个能获得锁,一个只能继续等待。
注意:这里可能导致超时时间不是其原本的超时时间,C1的超时时间可能被C2覆盖了,但是他们相差的毫秒及其小,这里忽略了。