
架构篇: CMS的重构与演进
重构系统是一项非常具有挑战性的事情。通常来说,在我们的系统是第二个系统的时候才需要重构,即这个系统本身已经很臃肿。我们花费了太量的时间在代 码间的逻辑,开发新的功能变得越来越慢。这不仅仅可能只是因为我们之前的架构没有设计好,而且在我们开发的过程中没有保持着原先设计时的一些原则。如果是 这样的情况,那么这就是一个复杂的过程。
还有一种情况是我们发现了一种更符合我们当前业务的框架。
动态CMS
CMS简介
CMS是Content Management System的缩写,意为“内容管理系统”.它可以做很多的事情,但是总的来说就是Page和Blog——即我们要创建一些页面可以用于写一些About US、Contact Me,以及持续更新的博客或者新闻,以及其他子系统——通常更新不活跃。通过对这些博客或者新闻进行分类,我们就可以有不同的信息内容,如下图:

CMS是政府和企业都需要的系统,他们有很多的信息需要公开,并且需要对其组织进行宣传。在我有限的CMS交付经验里(大学时期),一般第一次交付 CMS的时候,已经创建了大部分页面。有时候这些页面可能直接存储在数据库中,后来发现这不是一个好的方案,于是很多页面变成了静态页面。随后,在CMS 的生命周期里就是更新内容。
因而,CMS中起其主导的东西还是Content,即内容。而内容是一些持续可变的东西。这也就是为什么WordPress这么流行于CMS界,它 是一个博客系统,但是多数时候我们只需要更新内容。除此不得不提及的一个CMS框架是Drupal,两者一对比会发现Drupal比较强大。通常来说,强 大的一个负作用就是——复杂。
WordPress和Drupal这一类的系统都属于发布系统,而其后台可以称为编辑系统。
一般来说CMS有下面的特点:
- 支持多用户。
- 角色控制-内容管理。如InfoQ的编辑后台就会有这样的机制,社区编辑负责创建内容,而审核发布则是另外的人做的。
- 插件管理。如WordPress和Drupal在这一方面就很强大,基本可以满足日常的需要。
- 快捷简便地存储内容。简单地来说就是所见即所得编辑器,但是对于开发者来说,Markdown似乎是好的选择。
- 预发布。这是一个很重要的特性,特别是如果你的系统后台没有相对应的预览机制。
- 子系统。由于这属于定制化的系统,并不方便进行总结。
- …
CMS一直就是这样一个紧耦合的系统。
CMS架构与Django
说起来,我一直是一个CMS党。主要原因还在于我可以随心所欲地去修改网站的内容,修改网站的架构。好的CMS总的来说都有其架构图,下图似乎是Drupal的模块图
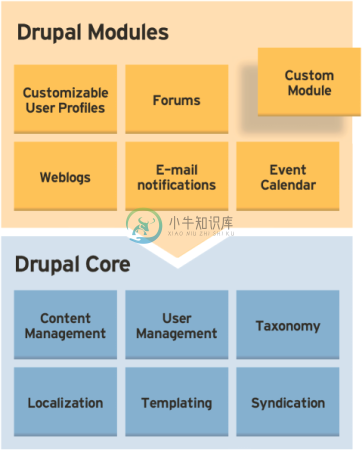
一般来说,其底层都会有:
- ORM
- User Management
- I18n / L10n
- Templates
我一直在使用一个名为Django的Python Web框架,它最初是被开发来用于管理劳伦斯出版集团旗下的一些以新闻内容为主的网站的,即是CMS(内容管理系统)软件。它是一个MTV框架——与多数的框架并没有太大的区别。
| 层次 | 职责 |
|---|---|
| 模型(Model),即数据存取层 | 处理与数据相关的所有事务:如何存取、如何验证有效性、包含哪些行为以及数据之间的关系等。 |
| 模板(Template),即表现层 | 处理与表现相关的决定: 如何在页面或其他类型文档中进行显示。 |
| 视图(View),即业务逻辑层 | 存取模型及调取恰当模板的相关逻辑。模型与模板之间的桥梁。 |
从框架本身来上看它和别的系统没有太大的区别。
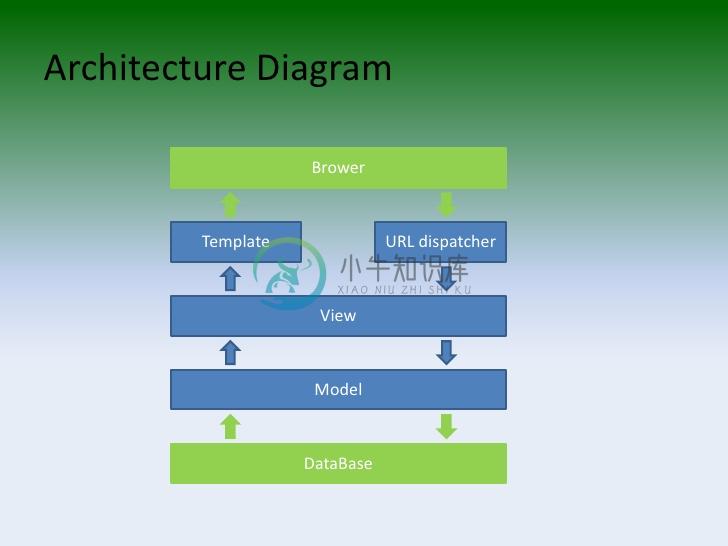
但是如果我们已经有多外模块(即Django中app的概念),那么系统的架构就有所不同了。
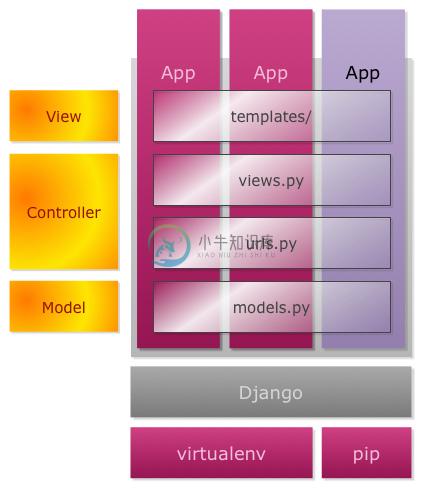
这就是为何我喜欢用这个CMS的原因了,我的每个子系统都以APP的形式提供服务——博客是一个app,sitemap是一个app,api是一个app。系统直接解耦为类似于混合服务的架构,即不像微服务一样多语言化,又不会有宏应用的紧耦合问题。
编辑-发布分离
我们的编辑和发布系统在某种意义上紧耦合在一起了,当用户访问量特别大的时候,这样会让我们的应用变得特定慢。有时候编辑甚至发布不了新的东西,如下图引示:
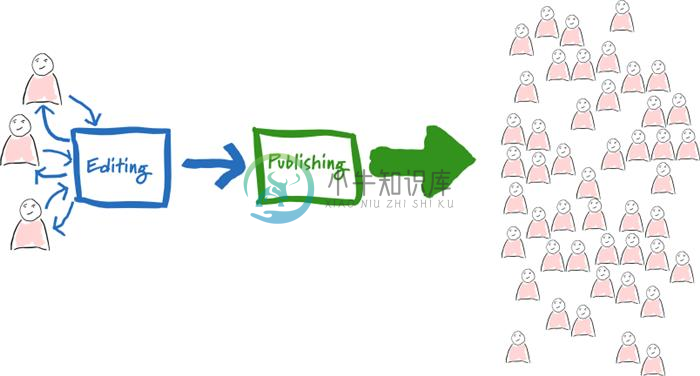
或者你认识出了上图是源自Martin Folwer的编辑-发布分离
编辑-发布分离是几年前解耦复杂系统游来开来带来的一个成果。今天这个似乎已经很常见了,编辑的时候是在后台进行的,等到发布的时候已经变成了一个静态的HTML。
已经有足够多的CMS支持这样的特性,运行起来似乎特别不错,当然这样的系统也会有缓存的问题。有了APP这后,这个趋势就更加明显了——人们需要提供一个API。到底是在现有的系统里提供一个新的API,还是创建一个新的API。
这时候,我更愿意选择后者——毕竟紧耦合一个系统总会在后期带来足够多的麻烦。而且基于数据库构建一个只读的RESTful API并不是一个复杂的过程,而且也危险。这时候的瓶颈就是数据库,但是似乎数据库都是多数系统的瓶颈。人们想出了各种各样的技术来解决这个瓶颈。
于是之前我试着用Node.js + RESTify将我的博客重构成了一个SPA,当然这个时候CMS还在运行着。出于SEO的原因我并没有在最后采用这个方案,因为我网站的主要流量来源是Google和是百度。但是我在另外的网站里混合了SPA与MPA,其中的性能与应用是相当的,除了第一次加载页面的时候会带来一些延时。
除了Node.js + RESTify,也试了试Python + Falcon(一个高性能的RESTful框架)。这个API理论上也应该可以给APP直接使用,并且可以直接拿来生成静态页面。
编辑-发布-开发分离:静态站点生成
如React一样解决DOM性能的问题就是跳过DOM这个坑,要跳过动态网站的性能问题就是让网站变成静态。
越来越多的开发人员开始在使用Github Pages作为他们的博客,这是一个很有意思的转变。主要的原因是这是免费的,并且基本上可以保证24x7小时是可用的——当且仅当Github发现故障的时候才会不可访问。
在这一类静态站点生成器(Github)里面,比较流行的有下面的内容(数据来源: http://segmentfault.com/a/1190000002476681):
- Jekyll / OctoPress。Jekyll和OctoPress是最流行的静态博客系统。
- Hexo。Hexo是NodeJS编写的静态博客系统,其生成速度快,主题数量相对也比较丰富。是OctoPress的优秀替代者。
- Sculpin。Sculpin是PHP的静态站点系统。Hexo和Octopress专注于博客,而有时候我们的需求不仅仅是博客,而是有类似 CMS的页面生成需求。Sculpin是一个泛用途的静态站点生成系统,在支持博客常见的分页、分类tag等同时,也能较好地支持非博客的一般页面生成。
- Hugo。Hugo是GO语言编写的静态站点系统。其生成速度快,且在较好支持博客和非博客内容的同时提供了比较完备的主题系统。无论是自己写主题还是套用别人的主题都比较顺手。
通常这一类的工具里会有下面的内容:
- 模板
- 支持Markdown
- 元数据
如Hexo这样的框架甚至提供了一键部署的功能。
在我们写了相关的代码之后,随后要做的就是生成HTML。对于个人博客来说,这是一个非常不错的系统,但是对于一些企业级的系统来说,我们的要求就更高了。如下图是Carrot采用的架构:
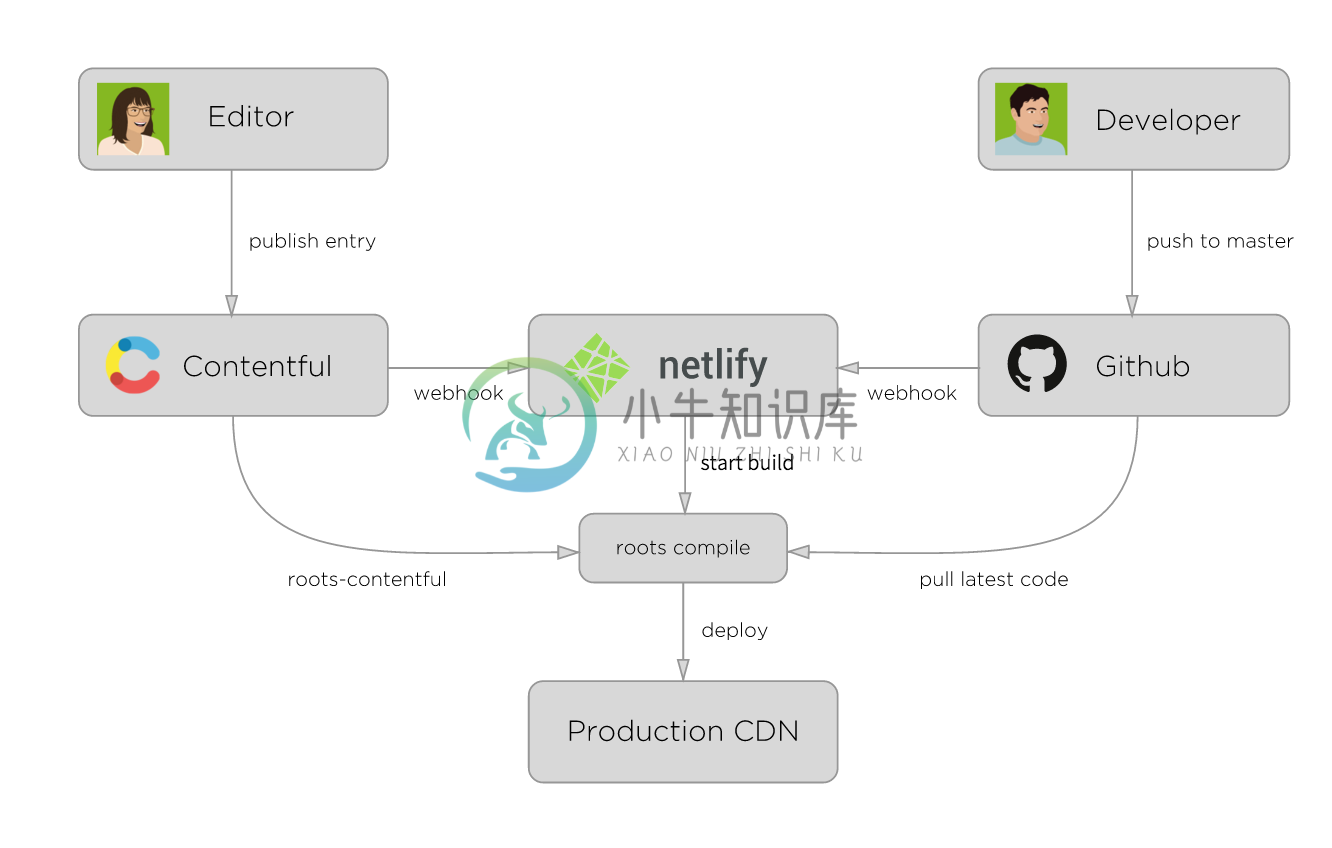
这与我们在项目上的系统架构目前相似。作为一个博主,通常来说我们修改博客的主题的频率会比较低, 可能是半年一次。如果你经常修改博客的主题,你博客上的文章一定是相当的少。
上图中的编辑者通过一个名为Contentful CMS来创建他们的内容,接着生成RESTful API。而类似的事情,我们也可以用Wordpress + RESTful 插件来完成。如果做得好,那么我想这个API也可以直接给APP使用。
上图中的开发者需要不断地将修改的主题或者类似的东西PUSH到版本管理系统上,接着会有webhook监测到他们的变化,然后编译出新的静态页面。
最后通过Netlify,他们编译到了一起,然后部署到生产环境。除了Netlify,你也可以编写生成脚本,然后用Bamboo、Go这类的CI工具进行编译。
通常来说,生产环境可以使用CDN,如CloudFront服务。与动态网站相比,静态网站很容易直接部署到CDN,并可以直接从离用户近的本地缓存提供服务。除此,直接使用AWS S3的静态网站托管也是一个非常不错的选择。
基于Github的编辑-发布-开发分离
尽管我们已经在项目上实施了基于Github的部分内容管理已经有些日子里,但是由于找不到一些相关的资料,便不好透露相关的细节。直到我看到了《An Incremental Approach to Content Management Using Git 1》,我才意识到这似乎已经是一个成熟的技术了。看样子这项技术首先已经应用到了ThoughtWorks的官网上了。
文中提到了使用这种架构的几个点:
- 快速地开始项目,而不是学习或者配置框架。
- 需要使用我们信奉的原则,如TDD。而这是大部分CMS所不支持的。
- 基于服务的架构。
- 灵活的语言和工具
- 我们是开发人员。
So,so,这些开发人员做了些什么:
- 内容存储为静态文件
- 不是所有的内容都是平等的
- 引入内容服务
- 使用Github。所有的content会提交到一个repo里,同时在我们push内容的时候,可以实时更新这些内容。
- 允许内容通过内容服务更新
- 使用Github API
于是,有了一个名为Hacienda的框架用于管理内容,并存储为JSON。这意味着什么?
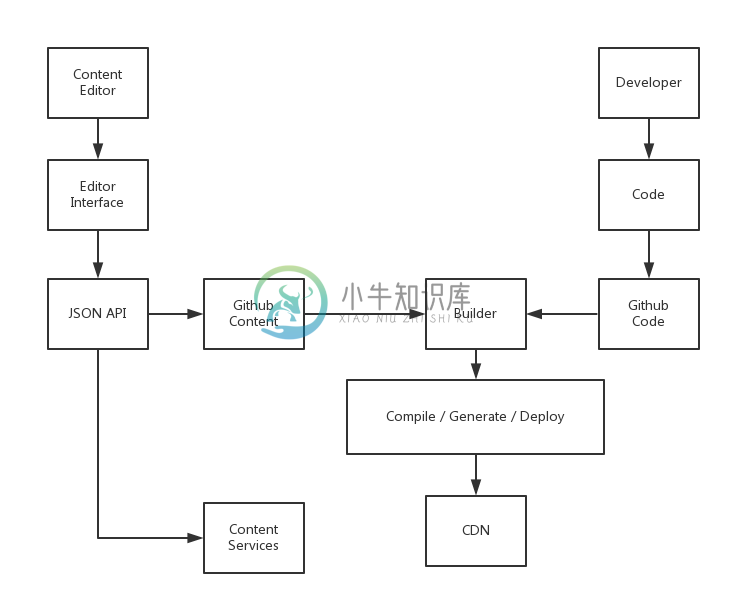
因为使用了Git,我们可以了解到一个文件内容的历史版本,相比于WordPress来说更直观,而且更容易 上手。
开发人员修改完他们的代码后,就可以直接提交,不会影响到Editor使用网站。Editor通过一个编辑器添加内容,在保存后,内容以JSON的 形式出现直接提交代码到Github上相应的代码库中。CI或者Builder监测到他们的办法,就会生成新的静态页面。在这时候,我们可以选择有一个预 览的平台,并且可以一键部署。那么,事情似乎就完成得差不多了。
如果我们有APP,那么我们就可以使用Content Servies来做这些事情。甚至可以直接拿其搭建一个SPA。
如果我们需要全文搜索功能,也变得很简单。我们已经不需要直接和数据库交互,我们可以直接读取JSON并且构建索引。这时候需要一个简单的Web服务,而且这个服务还是只读的。
在需要的时候,如手机APP,我们可以通过Content Servies来创建博客。
Repractise
动态网页是下一个要解决的难题。我们从数据库中读取数据,再用动态去渲染出一个静态页面,并且缓存服务器来缓存这个页面。既然我们都可以用Varnish、Squid这样的软件来缓存页面——表明它们可以是静态的,为什么不考虑直接使用静态网页呢?
思考完这些后,我想到了一个符合学习的场景。
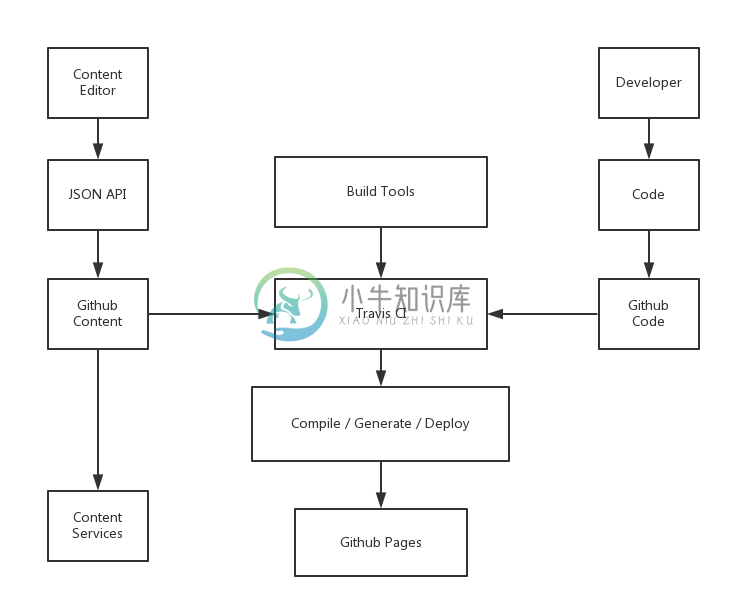
我们构建的核心都可以基于Travis CI来完成,唯一存在风险的环节是我们似乎需要暴露我们的Key。
其他
参考文章:
- 静态网站生成器将会成为下一个大热门
- EditingPublishingSeparation
- An Incremental Approach to Content Management Using Git 1
- Part 2: Implementing Content Management and Publication Using Git
构建基于Git为数据中心的CMS
或许你也用过Hexo / Jekyll / Octopress这样的静态博客,他们的原理都是类似的。我们有一个代码库用于生成静态页面,然后这些静态页面会被PUSH到Github Pages上。
从我们设计系统的角度来说,我们会在Github上有三个主要代码库:
- Content。用于存放编辑器生成的JSON文件,这样我们就可以GET这些资源,并用Backbone / Angular / React 这些前端框架来搭建SPA。
- Code。开发者在这里存放他们的代码,如主题、静态文件生成器、资源文件等等。
- Builder。在这里它是运行于Travis CI上的一些脚本文件,用于Clone代码,并执行Code中的脚本。
以及一些额外的服务,当且仅当你有一些额外的功能需求的时候。
- Extend Service。当我们需要搜索服务时,我们就需要这样的一些服务。如我正考虑使用Python的whoosh来完成这个功能,这时候我计划用Flask框架,但是只是计划中——因为没有合适的中间件。
- Editor。相比于前面的那些知识这一步适合更重要,也就是为什么生成的格式是JSON而不是Markdown的原理。对于非程序员来说,要熟 练掌握Markdown不是一件容易的事。于是,一个考虑中的方案就是使用 Electron + Node.js来生成API,最后通过GitHub API V3来实现上传。
- Mobile App。
So,这一个过程是如何进行的。
用户场景
整个过程的Pipeline如下所示:
- 编辑使用他们的编辑器来编辑的内容并点击发布,然后这个内容就可以通过GitHub API上传到Content这个Repo里。
- 这时候需要有一个WebHooks监测到了Content代码库的变化,便运行Builder这个代码库的Travis CI。
- 这个Builder脚本首先,会设置一些基本的git配置。然后clone Content和Code的代码,接着运行构建命令,生成新的内容。
- 然后Builder Commit内容,并PUSH内容。
在这种情形中,编辑能否完成工作就不依赖于网站——脱稿又少了 个借口。这时候网站出错的概率太小了——你不需要一个缓存服务器、HTTP服务器,由于没有动态生成的内容,你也不需要守护进程。这些内容都是静态文件, 你可以将他们放在任何可以提供静态文件托管的地方——CloudFront、S3等等。或者你再相信自己的服务器,Nginx可是全球第二好(第一还没出 现)的静态文件服务器。
开发人员只在需要的时候去修改网站的一些内容。So,你可能会担心如果这时候修改的东西有问题了怎么办。
- 使用这种模式就意味着你需要有测试来覆盖这些构建工具、生成工具。
- 相比于自己的代码,别人的CMS更可靠?
需要注意的是如果你上一次构建成功,你生成的文件都是正常的,那么你只需要回滚开发相关的代码即可。旧的代码仍然可以工作得很好。其次,由于生成的是静态文件,查错的成本就比较低。最后,重新放上之前的静态文件。
Code: 生成静态页面
Assemble是一个使用Node.js,Grunt.js,Gulp,Yeoman 等来实现的静态网页生成系统。这样的生成器有很多,Zurb Foundation, Zurb Ink, Less.js / lesscss.org, Topcoat, Web Experience Toolkit等组织都使用这个工具来生成。这个工具似乎上个Release在一年多以前,现在正在开始0.6。虽然,这并不重要,但是还是顺便一说。
我们所要做的就是在我们的Gruntfile.js中写相应的生成代码。
assemble: {
options: {
flatten: true,
partials: ['templates/includes/*.hbs'],
layoutdir: 'templates/layouts',
data: 'content/blogs.json',
layout: 'default.hbs'
},
site: {
files: {'dest/': ['templates/*.hbs']}
},
blogs: {
options: {
flatten: true,
layoutdir: 'templates/layouts',
data: 'content/*.json',
partials: ['templates/includes/*.hbs'],
pages: pages
},
files: [
{ dest: './dest/blog/', src: '!*' }
]
}
}配置中的site用于生成页面相关的内容,blogs则可以根据json文件的文件名生成对就的html文件存储到blog目录中。
生成后的目录结果如下图所示:
.
├── about.html
├── blog
│ ├── blog-posts.html
│ └── blogs.html
├── blog.html
├── css
│ ├── images
│ │ └── banner.jpg
│ └── style.css
├── index.html
└── js
├── jquery.min.js
└── script.js
7 directories, 30 files这里的静态文件内容就是最后我们要发布的内容。
还需要做的一件事情就是:
grunt.registerTask('dev', ['default', 'connect:server', 'watch:site']);用于开发阶段这样的代码就够了,这个和你使用WebPack + React 似乎相差不了多少。
Builder: 构建生成工具
Github与Travis之间,可以做一个自动部署的工具。相信已经有很多人在Github上玩过这样的东西——先在Github上生成Token,然后用travis加密:
travis encrypt-file ssh_key --add加密后的Key就会保存到.travis.yml文件里,然后就可以在Travis CI上push你的代码到Github上了。
接着,你需要创建个deploy脚本,并且在after_success执行它:
after_success:
- test $TRAVIS_PULL_REQUEST == "false" && test $TRAVIS_BRANCH == "master" && bash deploy.sh在这个脚本里,你所需要做的就是clone content和code中的代码,并执行code中的生成脚本,生成新的内容后,提交代码。
#!/bin/bash
set -o errexit -o nounset
rev=$(git rev-parse --short HEAD)
cd stage/
git init
git config user.name "Robot"
git config user.email "robot@phodal.com"
git remote add upstream "https://$GH_TOKEN@github.com/phodal-archive/echeveria-deploy.git"
git fetch upstream
git reset upstream/gh-pages
git clone https://github.com/phodal-archive/echeveria-deploy code
git clone https://github.com/phodal-archive/echeveria-content content
pwd
cp -a content/contents code/content
cd code
npm install
npm install grunt-cli -g
grunt
mv dest/* ../
cd ../
rm -rf code
rm -rf content
touch .
if [ ! -f CNAME ]; then
echo "deploy.baimizhou.net" > CNAME
fi
git add -A .
git commit -m "rebuild pages at ${rev}"
git push -q upstream HEAD:gh-pages这就是这个builder做的事情——其中最主要的一个任务是grunt,它所做的就是:
grunt.registerTask('default', ['clean', 'assemble', 'copy']);Content:JSON格式
在使用Github和Travis CI完成Content的时候,发现没有一个好的Webhook。虽然我们的Content只能存储一些数据,但是放一个trigger脚本也是可以原谅的。
var Travis = require('travis-ci');
var repo = "phodal-archive/echeveria-deploy";
var travis = new Travis({
version: '2.0.0'
});
travis.authenticate({
github_token: process.env.GH_TOKEN
}, function (err, res) {
if (err) {
return console.error(err);
}
travis.repos(repo.split('/')[0], repo.split('/')[1]).builds.get(function (err, res) {
if (err) {
return console.error(err);
}
travis.requests.post({
build_id: res.builds[0].id
}, function (err, res) {
if (err) {
return console.error(err);
}
console.log(res.flash[0].notice);
});
});
});这里主要依赖于Travis CI来完成这部分功能,这时候我们还需要数据。
从Schema到数据库
我们在我们数据库中定义好了Schema——对一个数据库的结构描述。在《编辑-发布-开发分离 》一文中我们说到了echeveria-content的一个数据文件如下所示:
{
"title": "白米粥",
"author": "白米粥",
"url": "baimizhou",
"date": "2015-10-21",
"description": "# Blog post \n > This is an example blog post \n Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. ",
"blogpost": "# Blog post \n > This is an example blog post \n Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. \n Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum."
}比起之前的直接生成静态页面这里的数据就是更有意思地一步了,我们从数据库读取数据就是为了生成一个JSON文件。何不直接以JSON的形式存储文件呢?
我们都定义了这每篇文章的基本元素:
- title
- author
- date
- description
- content
- url
即使我们使用NoSQL我们也很难逃离这种模式。我们定义这些数据,为了在使用的时候更方便。存储这些数据只是这个过程中的一部分,下部分就是取出这些数据并对他们进行过滤,取出我们需要的数据。
Web的骨架就是这么简单,当然APP也是如此。难的地方在于存储怎样的数据,返回怎样的数据。不同的网站存储着不同的数据,如淘宝存储的是商品的 信息,Google存储着各种网站的数据——人们需要不同的方式去存储这些数据,为了更好地存储衍生了更多的数据存储方案——于是有了GFS、 Haystack等等。运营型网站想尽办法为最后一公里努力着,成长型的网站一直在想着怎样更好的返回数据,从更好的用户体验到机器学习。而数据则是这个 过程中不变的东西。
尽管,我已经想了很多办法去尽可能减少元素——在最开始的版本里只有标题和内容。然而为了满足我们在数据库中定义的结构,不得不造出来这么多对于一般用户不友好的字段。如链接名是为了存储的文件名而存在的,即这个链接名在最后会变成文件名:
repo.write('master', 'contents/' + data.url + '.json', stringifyData, 'Robot: add article ' + data.title, options, function (err, data) {
if(data.commit){
that.setState({message: "上传成功" + JSON.stringify(data)});
that.refs.snackbar.show();
that.setState({
sending: 0
});
}
});然后,上面的数据就会变成一个对象存储到“数据库”中。
今天 ,仍然有很多人用Word、Excel来存储数据。因为对于他们来说,这些软件更为直接,他们简单地操作一下就可以对数据进行排序、筛选。数据以怎样的形式存储并不重要,重要的是他们都以文件的形式存储着。
git作为NoSQL数据库
不同的数据库会以不同的形式存储到文件中去。blob是git中最为基本的存储单位,我们的每个content都是一个blob。redis可以以rdb文件的形式存储到文件系统中。完成一个CMS,我们并不需要那么多的查询功能。
这些上千年的组织机构,只想让人们知道他们想要说的东西。
我们使用NoSQL是因为:
- 不使用关系模型
- 在集群中运行良好
- 开源
- 无模式
- 数据交换格式
我想其中只有两点对于我来说是比较重要的集群与数据格式。但是集群和数据格式都不是我们要考虑的问题。。。
我们也不存在数据格式的问题、开源的问题,什么问题都没有。。除了,我们之前说到的查询——但是这是可以解决的问题,我们甚至可以返回不同的历史版本的。在这一点上git做得很好,他不会像WordPress那样存储多个版本。
JSON文件 + Nginx就可以变成这样一个合理的API,甚至是运行方式。我们可以对其进行增、删、改、查,尽管就当前来说查需要一个额外的软件来执行,但是为了实现一个用得比较少的功能,而去花费大把的时间可能就是在浪费。
git的“API”提供了丰富的增、删、改功能——你需要commit就可以了。我们所要做的就是:
- git commit
- git push
于是,就会有一个很忙的Travis-Github Robot在默默地为你工作。
一键发布:编辑器
为了实现之前说到的编辑-发布-开发分离的CMS,我还是花了两天的时间打造了一个面向普通用户的编辑器。效果截图如下所示:
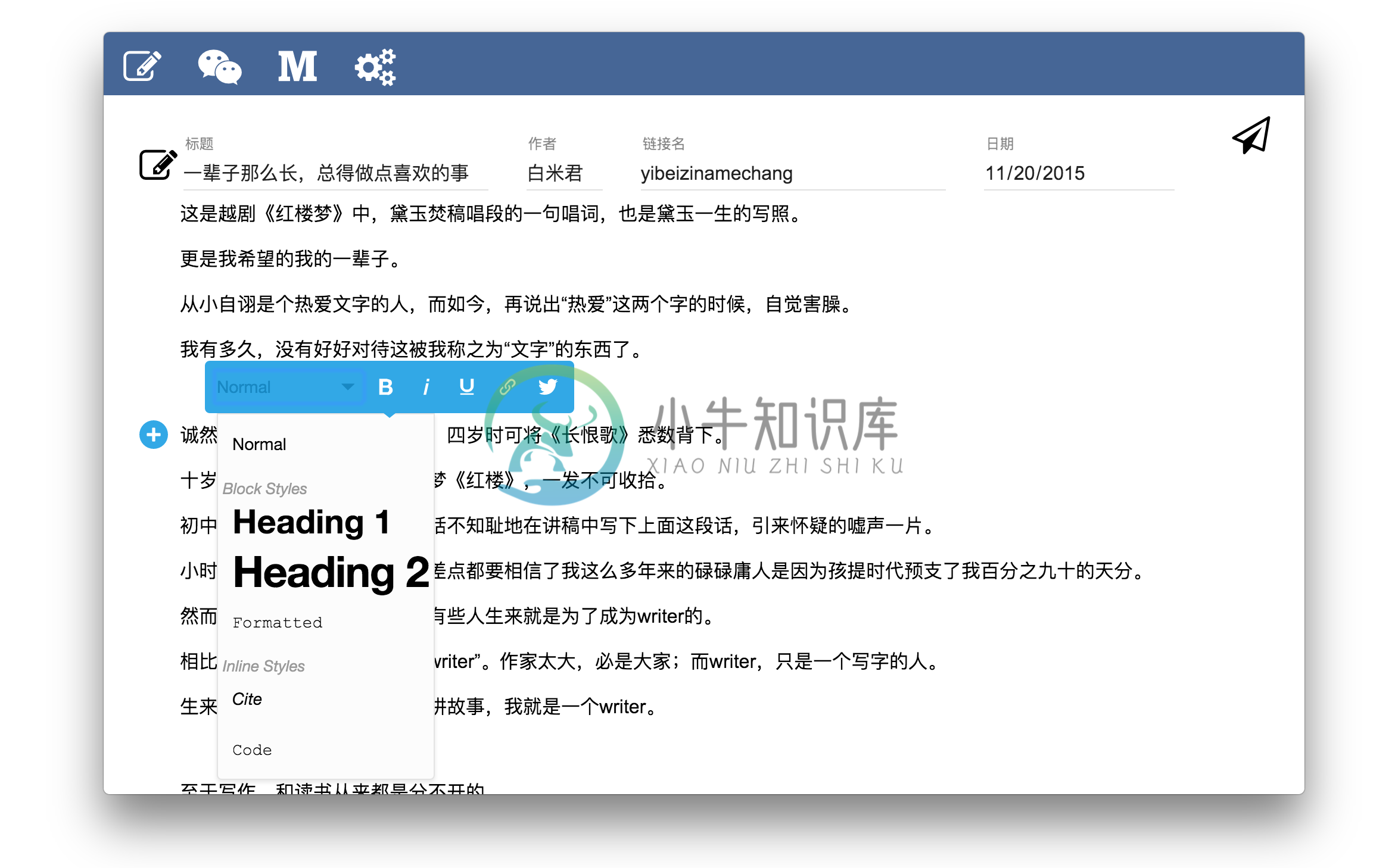
作为一个普通用户,这是一个很简单的软件。除了Electron + Node.js + React作了一个140M左右的软件,尽管压缩完只有40M左右 ,但是还是会把用户吓跑的。不过作为一个快速构建的原型已经很不错了——构建速度很快、并且运行良好。
- Electron
- React
- Material UI
- Alloy Editor
尽管这个界面看上去还是稍微复杂了一下,还在试着想办法将链接名和日期去掉——问题是为什么会有这两个东西?
Webpack 打包
if (process.env.HOT) {
mainWindow.loadUrl('file://' + __dirname + '/app/hot-dev-app.html');
} else {
mainWindow.loadUrl('file://' + __dirname + '/app/app.html');
}上传代码
repo.write('master', 'content/' + data.url + '.json', stringifyData, 'Robot: add article ' + data.title, options, function (err, data) {
if(data.commit){
that.setState({message: "上传成功" + JSON.stringify(data)});
that.refs.snackbar.show();
that.setState({
sending: 0
});
}
});当我们点下发送的时侯,这个内容就直接提交到了Content Repo下,如上上图所示。
当我们向Content Push代码的时候,就会运行一下Trigger脚本:
after_success:
- node trigger-build.js脚本的代码如下所示:
var Travis = require('travis-ci');
var repo = "phodal-archive/echeveria-deploy";
var travis = new Travis({
version: '2.0.0'
});
travis.authenticate({
github_token: process.env.GH_TOKEN
}, function (err, res) {
if (err) {
return console.error(err);
}
travis.repos(repo.split('/')[0], repo.split('/')[1]).builds.get(function (err, res) {
if (err) {
return console.error(err);
}
travis.requests.post({
build_id: res.builds[0].id
}, function (err, res) {
if (err) {
return console.error(err);
}
console.log(res.flash[0].notice);
});
});
});由于,我们在这个过程我们的Content提交的是JSON数据,我们可以直接用这些数据做一个APP。
移动应用
为了快速开发,这里我们使用了Ionic + ngCordova来开发 ,最后效果图如下所示:

在这个代码库里,主要由两部分组成:
- 获取全部文章
- 获取特定文章
为了获取全部文章就意味着,我们在Builder里,需要一个task来合并JSON文件,并删掉其中的一些无用的内容,如articleHTML和article。最后,将生成一个名为articles.json。
if (!grunt.file.exists(src))
throw "JSON source file \"" + chalk.red(src) + "\" not found.";
else {
var fragment;
grunt.log.debug("reading JSON source file \"" + chalk.green(src) + "\"");
try {
fragment = grunt.file.readJSON(src);
}
catch (e) {
grunt.fail.warn(e);
}
fragment.description = sanitizeHtml(fragment.article).substring(0, 200);
delete fragment.article;
delete fragment.articleHTML;
json.push(fragment);
}接着,我们就可以获取所有的文章然后显示~~。在这里又顺便加了一个pullToRefresh。
.controller('ArticleListsCtrl', function ($scope, Blog) {
$scope.articles = null;
$scope.blogOffset = 0;
$scope.doRefresh = function () {
Blog.async('http://deploy.baimizhou.net/api/blog/articles.json').then(function (results) {
$scope.articles = results;
});
$scope.$broadcast('scroll.refreshComplete');
$scope.$apply()
};
Blog.async('http://deploy.baimizhou.net/api/blog/articles.json').then(function (results) {
$scope.articles = results;
});
})最后,当我们点击特定的url,将跳转到相应的页面:
<ion-item class="item item-icon-right" ng-repeat="article in articles" type="item-text-wrap" href="#/app/article/{{article.url}}">
<h2>{{article.title}}</h2>
<i class="icon ion-ios-arrow-right"></i>
</ion-item>就会交由相应的Controller来处理。
.controller('ArticleCtrl', function ($scope, $stateParams, $sanitize, $sce, Blog) {
$scope.article = {};
Blog.async('http://deploy.baimizhou.net/api/' + $stateParams.slug + '.json').then(function (results) {
$scope.article = results;
$scope.htmlContent = $sce.trustAsHtml($scope.article.articleHTML);
});
});小结
尽管没有一个更成熟的环境可以探索这其中的问题,但是我想对于当前这种情况来说,它是非常棒的解决方案。我们面向的不是那些技术人员,而是一般的用户。他们能熟练使用的是:编辑器和APP。
- 不会因为后台的升级来困扰他们,也不会受其他组件的影响。
- 开发人员不需要担心,某个功能影响了编辑器的使用。
- Ops不再担心网站的性能问题——然后要么转为DevOps、要么被Fire。
其他
最后的代码库: