
1.16 第十章挖矿和共识
10.1 简介
“挖矿”这个词有点误导。一般意义的挖矿类似贵金属的提炼,于是人们将更多的注意力集中到挖矿的回报,也就是每个区块创造的新比特币。虽然挖矿行为会被这种奖励所激励,但挖矿的主要目的不是这个奖励或者产生新币。如果你只把挖矿看作是创比特币的过程,那么你就会误把这个过程中的手段(作为激励)作为目标。挖矿是一种去中心化的交易清算机制,通过这种机制,交易得到验证和清算。挖矿是使得比特币与众不同的发明,是一种去中心化的安全机制,是点对点数字现金的基础。
挖矿确保了比特币系统安全,并且在全网范围实现了没有中央权威机构的共识。挖出新币以及交易费的奖励是一种激励机制,它将矿工的行为与网络的安全性结合起来,同时实施货币供应。
提示:挖矿的目的不是创造新的比特币。这是激励机制。 挖矿是一种使比特币的安全security去中心化decentralized的机制。
矿工验证新交易并将其记录在全球分类账簿上。每10分钟就会有一个新的区块被“挖掘”出来,这个新区块里包含着从上一个区块产生到目前这段时间内发生的交易,这样这些交易就被添加到区块链中了。我们把包含在区块内且被添加到区块链上的交易称为“已确认confirmed”交易,交易经过“确认”之后,新的拥有者才能够花费他在交易中收到的比特币。
矿工们在挖矿过程中会得到两种类型的奖励:创建新区块的新币奖励,以及区块中所含交易的交易费。为了得到这些奖励,矿工们争相完成一种基于加密哈希算法的数学难题,这些难题的解决方案,称为“工作量证明”,包括在新区块中,作为矿工花费大量计算工作的证明。解决工作证明算法在区块链上获得奖励的竞争以及获胜者有权在区块链上记录交易,这二者是比特币安全模型的基石。
这个过程被称为挖矿,是因为奖励机制(新比特币产生)被设计为模拟收益递减模式,类似于贵重金属的挖矿过程。比特币的货币是通过挖矿发行的,类似于央行通过印刷钞票来发行货币。矿工通过创造一个新区块得到的比特币数量大约每四年(或准确说是每210,000个区块)减少一半。开始时为2009年1月每个区块奖励50个比特币,然后到2012年11月减半为每个区块奖励25个比特币。之后在2016年7月减半为每个新区块奖励12.5个比特币。2020年5月,再次减半为5比特币。基于这个公式,比特币挖矿奖励以指数方式递减,直到2140年。届时所有的比特币(20,999,999,980)全部发行完毕。换句话说在2140年之后,不会再有新的比特币产生。
矿工们同时也会获取交易费。每笔交易都可能包含一笔交易费,交易费是每笔交易记录的输入和输出的差额。在挖矿过程中成功“挖出”新区块的矿工可以得到该区块中包含的所有交易“小费”。目前,这笔费用占矿工收入的0.5%或更少,大部分收益仍来自挖矿所得的新比特币奖励。然而随着挖矿奖励的递减,以及每个区块中包含的交易数量增加,交易费在矿工收益中所占的比重将会逐渐增加。在2140年之后,所有的矿工收益都将由交易费构成。
在本章中,我们先来审视比特币的货币发行机制,然后再来了解挖矿的最重要的功能:支撑比特币安全的去中心化的共识机制。
为了了解挖矿和共识,我们将跟随Alice的交易,是如何被矿工Jing的挖矿设备接收并被添加到区块中的。 然后,我们将继续跟踪区块被挖矿,加入区块链,并通过自发共识被比特币网络接受。
10.1.1 比特币经济学和货币创造
比特币是在每一个区块的创建过程中以固定和递减的速度被“铸造出来”的。大约每十分钟产生一个新区块,每一个新区块都伴随着一定数量的全新比特币,它是从无到有的。每开采210,000个区块,或者大约每4年,货币发行速率降低50%。在比特币运行的第一个四年中,每个区块创造出50个新比特币。
2012年11月,比特币的新发行速度降低到每区块25个比特币。2016年7月,降低到12.5比特币/区块。2020年5月,也就是在区块630,000,减半再次发生,下降至每个区块6.25比特币。新币的发行速度会以指数级进行32次“等分”,直到第6,720,000块(大约会在2137年挖出),达到比特币的最小货币单位1聪。最终,在经过693万个区块之后,所有的共 2,099,999,997,690,000聪,或者说接近 2,100万比特币将全部发行完毕。在那之后,新的区块不再包含比特币奖励,矿工的收益全部来自交易费。图10-1展示了在发行速度不断降低的情况下,比特币总流通量与时间的关系。
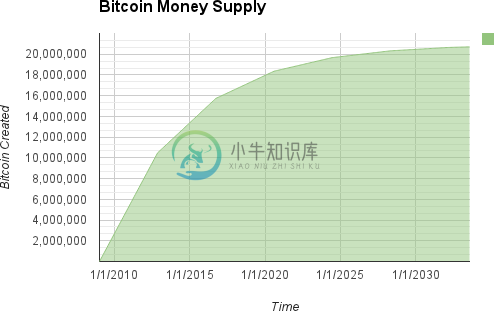
图10-1 基于发行率几何下降的比特币供应量和时间的关系
注意:比特币挖矿发行的最大数量也就成为挖矿奖励的上限。 在实践中,矿工可能故意挖那些低于全额奖励的区块。已经有这些区块被挖出来了,未来就会有更多被开采,这样导致货币发行总量的下降。
在例10-1的代码中,我们计算了比特币的总发行量
例10-1 比特币发行总量的计算脚本
# Original block reward for miners was 50 BTC = 50 0000 0000 Satoshis
start_block_reward = 50 * 10**8
# 210000 is around every 4 years with a 10 minute block interval
reward_interval = 210000
def max_money():
current_reward = start_block_reward
total = 0
while current_reward > 0:
total += reward_interval * current_reward
current_reward /= 2
return total
print("Total BTC to ever be created:", max_money(), "Satoshis")
例10-2显示了运行脚本的输出结果
例10-2 运行上述脚本的输出结果
$ python max_money.py
Total BTC to ever be created: 2099999997690000 Satoshis
总量有限并且发行量递减创造了一个固定的货币供应量来抵御通货膨胀。法币可被央行无限制地印刷出来,而比特币却永远不会因超额印发而出现通胀。
通货紧缩
发行总量固定并且递减的最重要和有争议的后果是,货币往往会趋向于内在通货紧缩性deflationary。通缩是一种由于货币的供应和需求不匹配导致的货币价值(和汇率)上涨的现象。与通货膨胀相反,价格通缩意味着随着时间的推移,货币拥有更多的购买力。
许多经济学家认为,通缩经济是一场灾难,应该不惜一切代价避免。这是因为在快速通货紧缩时期,人们预期商品价格会下跌,倾向于囤积货币而不是消费。这种现象在日本“失落的十年”期间出现,需求崩溃将日元推入通缩漩涡。
比特币专家们认为通缩本身并不坏。相反,通货紧缩与需求崩溃联系在一起,因为这是我们必须研究的通货紧缩的唯一例子。对于存在无限印刷可能的法定货币,除非需求完全崩溃,不愿意印刷货币,否则很难进入通缩漩涡。比特币的通缩不是由需求崩溃造成的,而是由可预见的供应受限造成的。
当然,通货紧缩的积极方面是,它与通货膨胀相反。通货膨胀导致货币的缓慢但不可避免的贬值,造成了一种隐藏的税收形式,惩罚储蓄者,解救了债务人(包括政府这个最大的债务人)。政府控制下的货币遭受轻易发债的道德风险,这种风险后来可能会以牺牲储蓄者为代价,通过贬值来抹去债务。
货币的通缩,如果不是由经济快速收缩所推动,那么这是一个问题,还是一个优势,仍有待观察,因为防止通胀和贬值远远大于通缩带来的风险。
10.2 去中心化共识
在上一章中我们研究了区块链,即所有交易的全球公共分类账(列表),比特币网络中的每个人都接受它,把它作为所有权的权威记录。
但在不考虑相信任何人的情况下,网络中的所有人如何就谁拥有什么这一普遍的“真相”达成一致呢?所有传统的支付系统都依赖于一个信任模型,该模型由一个中央机构提供清算服务,验证和清算所有交易。比特币没有中央权威机构,但是所有的全节点都有一份完整的公共账本副本,可以作为权威记录来信任。区块链不是由中央机构创建的,而是由网络中的每个节点独立组装的。网络中的所有节点,依靠着节点间的不安全的网络连接所传输的信息,最终得出同样的结果并共同维护了同一个公共总帐。本章探讨比特币网络在没有中央权威的情况下达成全球共识的过程。
中本聪的主要发明就是这种去中心化的自发共识emergent consensus机制。自发,是指共识没有明确的完成点,没有选举和共识达成的固定时刻。换句话说,共识是数以千计的独立节点遵守了简单的规则通过异步交互自发形成的产物。所有的比特币属性,包括货币、交易、支付以及不依靠中心机构和信任的安全模型等都依赖于这个发明。
比特币的去中心化共识由所有网络节点的4种独立过程相互作用而产生:
每个全节点依据一个详尽的标准列表对每个交易进行独立验证
挖矿节点将交易记录独立打包进新区块,通过工作证明算法进行证明计算
每个节点独立的对新区块进行校验并组装进区块链
每个节点对区块链进行独立选择,在工作量证明机制下选择累计工作量最大的区块链
在接下来的几节中,我们将研究这些过程,了解它们之间如何相互作用并达成全网的自发共识,从而使任意节点组合出它自己的权威、可信、公开的全局总帐副本。
10.3 交易的独立验证
在【第6章交易】中,我们知道了钱包软件通过收集UTXO、提供正确的解锁脚本、构造一个给新所有者的新输出来创建交易。产生的交易随后将被发送到比特币网络临近的节点,从而使得该交易能够在整个比特币网络中传播。
然而,在交易传递到临近的节点前,每一个收到交易的比特币节点都会首先验证该交易,这将确保只有有效的交易才会在网络中传播,而无效的交易将会被遇到的第一个节点废弃掉。
每一个节点在校验每一笔交易时,都需要对照一个长长的标准列表:
▷交易的语法和数据结构必须正确。
▷输入与输出列表都不能为空。
▷交易的字节数小于 MAX_BLOCK_SIZE 。
▷每一个输出值,以及总量,必须在规定值的范围内 (小于2,100万个币,大于dust参数设置的阈值)。
▷没有哈希等于0,N等于-1的输入(创币交易不应当被传播)。
▷nLockTime等于 INT_MAX ,或者是根据MedianTimePast要求满足nLocktime和nSequence的值
▷交易的大小是大于或等于100字节的。
▷交易中的签名数量(SIGOPS)应小于签名操作数量上限(sigoplimit)。
▷解锁脚本(scriptSig)只能够将数字压入栈中,并且锁定脚本( scriptPubkey )必须要符合isStandard的格式(该格式将会拒绝非标准交易)。
▷匹配的交易必须存在于交易池或主分支区块中。
▷对于每一个输入,如果引用的输出存在于交易池中任何别的交易中,该交易将被拒绝。
▷对于每一个输入,在主分支和交易池中寻找引用的输出交易。如果任何输入缺少输出交易,该交易将成为一个孤儿交易。如果与其匹配的交易还没有出现在池中,那么将被加入到孤儿交易池中。
▷对于每一个输入,如果引用的输出交易是一个创币交易的输出,该输入必须至少获得COINBASE_MATURITY(100)个确认。
▷对于每一个输入,引用的输出必须存在并且是未被使用的。
▷使用引用的输出交易获得输入值,并检查每一个输入值和总值是否在规定值的范围内 (小于2100万个币,大于0)。
▷如果输入值的总和小于输出值的总和,交易将被拒绝。
▷如果交易费用太低(minRelayTxFee) 以至于无法进入一个空的区块,交易将被拒绝。
▷每一个输入的解锁脚本必须依据相应的输出锁定脚本来验证。
这些条件可以在Bitcoin Cor客户端下的 AcceptToMemoryPool 、 CheckTransaction 和 CheckInputs 函数中获得更详细的阐述。 请注意,这些条件会随着时间发生变化,为了处理新型拒绝服务攻击,有时候也为交易类型多样化而放宽规则。
在收到交易后,每一个节点都会在全网广播前对这些交易进行独立校验,并以接收时的相应顺序,为有效的新交易建立一个有效交易池(还未确认),这个池可以叫做交易池,或者内存池或者mempool。
10.4 挖矿节点
在比特币网络中,有一些节点是专业节点称为“矿工”。在【第1章比特币介绍】中,我们介绍了Jing,在中国上海的计算机工程专业学生,他就是一位矿工。Jing通过矿机挖矿获得比特币,矿机是专门设计用于挖比特币的计算机硬件系统。Jing的这台专业挖矿设备连接着一个全节点的服务器。与Jing不同,有一些矿工挖矿没有全节点,正如我们在【10.11.2矿池】中所述的。与其他全节点相同,Jing的节点在比特币网络中接收和传播未确认交易。然而,Jing的节点也能够把这些交易打包进入一个新区块。
同其他节点一样,Jing的节点时刻监听着传播到比特币网络的新区块。而这些新加入的区块对挖矿节点有着特殊的意义。矿工间的竞争以新区块的传播而结束,如同宣布谁是最后的赢家。对于矿工们来说,收到一个有效的新区块意味着别人已经赢了,而自己则输掉了这场竞赛。然而,一轮竞赛的结束也代表着下一轮竞赛的开始。新区块并不仅仅是象征着竞赛结束的方格旗;它也是下一个区块竞赛的发令枪。
10.5 打包交易至区块
验证交易后,比特币节点会将这些交易添加到自己的内存池,也称作交易池中,在该池中,交易将一直等待,直到它们被包含(挖矿)到区块中。与其他节点一样,Jing的节点会收集、验证并传播新的交易。而与其他节点不同的是,Jing的节点会把这些交易整合到一个候选区块中。
让我们继续跟随Alice从Bob咖啡店购买咖啡时产生的那个区块(参见【2.1.2买一杯咖啡】)。Alice的交易在区块 277,316。为了演示本章中提到的概念,我们假设这个区块是由Jing的挖矿系统挖出的,并且在这个交易成为了新区块的一部分后继续跟进Alice的交易。
Jing的挖矿节点维护了一个区块链的本地副本。当Alice买咖啡的时候,Jing节点的区块链已经收集到了区块277,314,并继续监听着网络上的交易,在尝试挖掘新区块的同时,也监听着其他节点发现的区块。当Jing的节点在挖矿时,它从比特币网络收到了区块277,315。这个区块的到来标志着终结了产出区块277,315的竞赛,与此同时也是创造区块277,316竞赛的开始。
在上一个10分钟内,当Jing的节点正在寻找区块277,315的解的同时,它也在收集交易为下一个区块做准备。现在它已经在内存池中收集了几百笔交易。在接收到区块277,315并验证它之后,Jing的节点还会把它与内存池中的所有交易进行比较,并删除区块277315中已经包含的任何交易。内存池中保留的任何交易都是未经确认的,正在等待记录到新区块中。
Jing的节点立刻构建一个新的空区块,做为区块277,316的候选区块。称作候选区块是因为它还没有包含有效的工作量证明,不是一个有效的区块,而只有在矿工成功找到一个工作量证明的解之后,这个区块才生效。
现在,Jing的节点从内存池中整合到了全部的交易,新的候选区块包含有418笔交易,总的交易费为0.09094925个比特币。你可以通过Bitcoin Core客户端命令行来查看这个区块,如例10-3所示:
例10-3 使用命令行检索区块277,316
$ bitcoin-cli getblockhash 277316
0000000000000001b6b9a13b095e96db41c4a928b97ef2d944a9b31b2cc7bdc4
$ bitcoin-cli getblock 0000000000000001b6b9a13b095e96db41c4a928b97ef2d9\
44a9b31b2cc7bdc4
{
"hash" : "0000000000000001b6b9a13b095e96db41c4a928b97ef2d944a9b31b2cc7bdc4",
"confirmations" : 35561,
"size" : 218629,
"height" : 277316,
"version" : 2,
"merkleroot" : "c91c008c26e50763e9f548bb8b2fc323735f73577effbc55502c51eb4cc7cf2e",
"tx" : [
"d5ada064c6417ca25c4308bd158c34b77e1c0eca2a73cda16c737e7424afba2f",
"b268b45c59b39d759614757718b9918caf0ba9d97c56f3b91956ff877c503fbe",
... 417 more transactions ...
],
"time" : 1388185914,
"nonce" : 924591752,
"bits" : "1903a30c",
"difficulty" : 1180923195.25802612,
"chainwork" : "000000000000000000000000000000000000000000000934695e92aaf53afa1a",
"previousblockhash" : "0000000000000002a7bbd25a417c0374cc55261021e8a9ca74442b01284f0569"
}
10.5.1 创币交易
区块中的第一笔交易是笔特殊交易,称为创币交易coinbase transaction。这个交易是由Jing的节点构造,并包含他的挖矿贡献的奖励。
注意:当区块277,316被挖出来时,每个区块的奖励是25个比特币。此后,已经过了两个“减半”时期。 2016年7月的奖励为12.5个比特币。2020年5月是6.25比特币。
Jing的节点会创建“向Jing的地址支付25.09094928个比特币”这样一个交易,支付到自己的钱包。Jing挖出区块获得的奖励总额是创币奖励(25个新比特币)和区块中全部交易的交易费(0.09094928)的总和,如例10-4所示。
例10-4 创币交易
$ bitcoin-cli getrawtransaction d5ada064c6417ca25c4308bd158c34b77e1c0eca2a73cda16c737e7424afba2f 1
{
"hex" : "01000000010000000000000000000000000000000000000000000000000000000000000000ffffffff0f03443b0403858402062f503253482fffffffff0110c08d9500000000232102aa970c592640d19de03ff6f329d6fd2eecb023263b9ba5d1b81c29b523da8b21ac00000000",
"txid" : "d5ada064c6417ca25c4308bd158c34b77e1c0eca2a73cda16c737e7424afba2f",
"version" : 1,
"locktime" : 0,
"vin" : [
{
"coinbase" : "03443b0403858402062f503253482f",
"sequence" : 4294967295
}
],
"vout" : [
{
"value" : 25.09094928,
"n" : 0,
"scriptPubKey" : {
"asm" : "02aa970c592640d19de03ff6f329d6fd2eecb023263b9ba5d1b81c29b523da8b21OP_CHECKSIG",
"hex" : "2102aa970c592640d19de03ff6f329d6fd2eecb023263b9ba5d1b81c29b523da8b21ac",
"reqSigs" : 1,
"type" : "pubkey",
"addresses" : [
"1MxTkeEP2PmHSMze5tUZ1hAV3YTKu2Gh1N"
]
}
}
]
}
与常规交易不同,创币交易不消耗作为输入的UTXO。相反它只包含一个被称作coinbase的输入,从零开始创建比特币。创币交易有一个输出,支付到这个矿工的比特币地址。创币交易的输出将这25.09094928个比特币发送到矿工的比特币地址,如本例所示的1MxTkeEP2PmHSMze5tUZ1hAV3YTKu2Gh1N。
10.5.2 创币奖励与矿工费
为了构造创币交易,Jing的节点需要计算矿工费的总额,将这418个已添加到区块交易的输入和输出分别进行求和,然后用输入总额减去输出总额得到矿工费总额,公式如下:
Total Fees = Sum(Inputs) - Sum(Outputs)
在区块277,316中,矿工费的总额是0.09094925个比特币。
紧接着,Jing的节点计算出这个新区块正确的奖励额。奖励额的计算是基于区块高度的,以每个区块50个比特币为开始,每产生210,000个区块减半一次。这个区块高度是277,316,所以正确的奖励额是25个比特币。
详细的计算过程可以参看Bitcoin Core客户端中的GetBlockValue函数,如例10-5所示:
例10-5 计算区块奖励—函数GetBlockValue, Bitcoin Core客户端, main.cpp
CAmount GetBlockSubsidy(int nHeight, const Consensus::Params& consensusParams)
{
int halvings = nHeight / consensusParams.nSubsidyHalvingInterval;
// Force block reward to zero when right shift is undefined.
if (halvings >= 64)
return 0;
CAmount nSubsidy = 50 * COIN;
// Subsidy is cut in half every 210,000 blocks which will occur approximately every 4 years.
nSubsidy >>= halvings;
return nSubsidy;
}
最初的奖励是用“聪satoshis”计算的,用50乘以 COIN 常量(100,000,000聪),也就是说初始奖励额(nSubsidy)为50亿聪。
紧接着,这个函数用当前区块高度除以减半间隔(SubsidyHalvingInterval 函数)得到已减半次数。每210,000个区块为一个减半间隔,对应本例中的区块27,7316,所以减半次数为1。
变量halvings最大值64,如果超出这个值,则代码只提供零奖励(仅返回交易费)。
然后,接下来,该函数使用二进制右移运算符将每一轮减半的奖励(nSubsidy)除以2。在这个例子中,对于区块277,316,就是将值为50亿聪的奖励额右移一次(减半),得到25亿聪,也就是25个比特币的奖励额。之所以采用二进制右移操作,是因为相比于整数或浮点数除法,右移操作的效率更高。为了避免潜在的错误,在63次减半后右移操作就被跳过,并将奖励设置为0。
最后,将创币奖励额(nSubsidy )与矿工费(nFee)总额求和,返回这个值。
注意: 如果Jing的挖矿节点把创币交易写入区块,那么如何防止Jing奖励自己100甚至1000比特币? 答案是,不正确的奖励将被其他人视为无效,也就浪费了Jing用于工作证明的投入。只有这个区块被大家认可,Jing才能使用奖励。
10.5.3 创币交易的结构
经过计算,Jing的节点构造了一个创币交易,支付给自己25.09094928个比特币。
例10-4所示,创币交易的结构比较特殊,与交易输入需要指定一个先前的UTXO不同,它包含一个“coinbase“输入。在【6.3.2.1交易序列化--交易输入中的表6-2】中,我们已经研究了交易输入。现在让我们来比较一下常规交易输入与创币交易输入。表10-1给出了常规交易输入的结构,表10-2给出的是创币交易输入的结构。
表10-1 常规交易输入结构
| Size | Field | Description |
|---|---|---|
| 32 bytes | Transaction Hash | Pointer to the transaction containing the UTXO to be spent |
| 4 bytes | Output Index | The index number of the UTXO to be spent, first one is 0 |
| 1–9 bytes (VarInt) | Unlocking-Script Size | Unlocking-Script length in bytes, to follow |
| Variable | Unlocking-Script | A script that fulfills the conditions of the UTXO locking script |
| 4 bytes | Sequence Number | Usually set to 0xFFFFFFFF to opt out of BIP 125 and BIP 68 |
表10-2 创币交易输入结构
| Size | Field | Description |
|---|---|---|
| 32 bytes | Transaction Hash | All bits are zero: Not a transaction hash reference |
| 4 bytes | Output Index | All bits are ones: 0xFFFFFFFF |
| 1–9 bytes (VarInt) | Coinbase Data Size | Length of the coinbase data, from 2 to 100 bytes |
| Variable | Coinbase Data | Arbitrary data used for extra nonce and mining tags. In v2 blocks; must begin with block height |
| 4 bytes | Sequence Number | Set to 0xFFFFFFFF |
在创币交易中,前两个字段设定的值表示不引用UTXO。相反,“Transaction Hash”字段32个字节全部填充0,“Output Index”字段全部填充0xFF(十进制为255)。“解锁脚本”由“Coinbase Data”代替,该字段被矿工使用,接下来会看到。
10.5.4 Coinbase data
创币交易不包含“解锁脚本“(又称作 scriptSig)字段,这个字段被coinbase data字段替代,长度最小2字节,最大100字节。除了开始的几个字节外,矿工可以任意使用coinbase data的其他部分,可以填充任何数据。
以创世区块为例,中本聪在coinbase data中填入了这样的数据“The Times 03/Jan/ 2009 Chancellor on brink of second bailout for banks“(泰晤士报 2009年1月3日 财政大臣将再次对银行施以援手),作为日期的证明,同时也传递了信息。现在,矿工使用coinbase data实现额外的nonce值,以及标识挖出区块的矿池的字符串。
coinbase前几个字节也曾是可以任意填写的,不过在后来的BIP34中规定了版本2的区块(版本字段设置为2的区块),必须包含其区块高度索引,在coinbase字段开头满足脚本“push”操作。
我们以例10-4中的区块277,316为例,coinbase就是交易输入的“解锁脚本“(或scriptSig)字段,其中包含十六进制值为03443b0403858402062f503253482f。下面让我们来解码这段数据。
第一个字节03指示脚本执行引擎将接下来的三个字节推送到脚本堆栈上(参见【附录2、交易脚本语言操作符,常量和符号中表一内容】)。紧接着的3个字节是0x443b04,是以小端格式(最低有效字节在先)编码的区块高度。翻转字节序得到0x043b44,表示为十进制是277,316。
紧接着的几个十六进制数(03858402062)用于编码额外随机数nonce(参见【10.11.1 额外随机数解决方案】),或者一个随机值,从而求解工作量证明。
coinbase data结尾部分(2f503253482f)是ASCII编码字符/P2SH/,表示挖出这个区块的挖矿节点支持BIP-16所定义的pay-to-script-hash(P2SH)改进方案。在P2SH功能引入到比特币的时候,要求矿工发出信号,支持BIP-16还是BIP-17。支持BIP-16的矿工将/P2SH/放入coinbase data中,支持BIP-17的矿工将p2sh/CHV放入coinbase data中。最后,BIP-16在选举中胜出,很多矿工继续在他们的coinbase中填写/P2SH/以表示支持这个功能。
例10-6使用了libbitcoin库(参见【3.5 其他可选的客户端、库、工具包】),从创世区块中提取coinbase data,并显示出中本聪留下的信息。注意libbitcoin库中包含了一份创世块的静态副本,所以这段示例代码可以直接检索库中的创世区块数据。
例10-6 从创世区块中提取coinbase data
/*
Display the genesis block message by Satoshi.
*/
#include <iostream>
#include <bitcoin/bitcoin.hpp>
int main()
{
// Create genesis block.
bc::chain::block block = bc::chain::block::genesis_mainnet();
// Genesis block contains a single coinbase transaction.
assert(block.transactions().size() == 1);
// Get first transaction in block (coinbase).
const bc::chain::transaction& coinbase_tx = block.transactions()[0];
// Coinbase tx has a single input.
assert(coinbase_tx.inputs().size() == 1);
const bc::chain::input& coinbase_input = coinbase_tx.inputs()[0];
// Convert the input script to its raw format.
const auto prefix = false;
const bc::data_chunk& raw_message = coinbase_input.script().to_data(prefix);
// Convert this to a std::string.
std::string message(raw_message.begin(), raw_message.end());
// Display the genesis block message.
std::cout << message << std::endl;
return 0;
}
例10-7中,我们使用GNU C++编译器编译源代码并运行得到的可执行文件。
例10-7 编译并运行satoshi-words示例代码
$ # Compile the code
$ g++ -o satoshi-words satoshi-words.cpp $(pkg-config --cflags --libs libbitcoin)
$ # Run the executable
$ ./satoshi-words
^D��<GS>^A^DEThe Times 03/Jan/2009 Chancellor on brink of second bailout for banks
10.6 构造区块头
为了构造区块头,挖矿节点需要填充六个字段,如表10-3中所示。
表10-3 区块头结构
| Size | Field | Description |
|---|---|---|
| 4 bytes | Version | A version number to track software/protocol upgrades |
| 32 bytes | Previous Block Hash | A reference to the hash of the previous (parent) block in the chain |
| 32 bytes | Merkle Root | A hash of the root of the merkle tree of this block’s transactions |
| 4 bytes | Timestamp | The approximate creation time of this block (seconds from Unix Epoch) |
| 4 bytes | Target | The Proof-of-Work algorithm target for this block |
| 4 bytes | Nonce | A counter used for the Proof-of-Work algorithm |
在区块277,316被挖出的时候,区块结构中用来表示Version的字段值为2,长度为4字节,以小端格式编码值为 0x20000000。
接着,挖矿节点需要填充“Previous Block Hash”,在本例中,这个值为Jing的节点从网络上接收到的区块277,315的区块头哈希值,它是区块277,316候选区块的父区块。区块277,315的区块头哈希值为:
0000000000000002a7bbd25a417c0374cc55261021e8a9ca74442b01284f0569
提示:通过选择候选区块头中的Previous Block Hash字段指定的特定父区块,Jing正在将挖矿能力用于将这个特定区块附加到尾部来扩展区块链。从本质上讲,这就是用他的挖矿权为最长难度的有效链进行的“投票”。
下一步是使用默克尔树归纳所有交易,以便将默克尔树根添加到区块头。创币交易是区块中的第一个交易。然后,在它之后再添加418个交易,在区块中总共添加了419个交易。在【9.7 默克尔树】,我们已经了解,树中必须有偶数个叶子节点,所以需要复制最后一个交易作为第420个叶子节点,每个叶子节点是对应交易的哈希值。这些交易的哈希值成对地组合,再创建每一层树,直到最终组合并成一个根节点。默克尔树根节点将全部交易数据归纳为一个32字节长度的值,例10-3中默克尔树根的值如下:
c91c008c26e50763e9f548bb8b2fc323735f73577effbc55502c51eb4cc7cf2e
然后,JING的挖矿节点会继续添加一个4字节的时间戳,以Unix纪元时间编码,即自UTC时间1970年1月1日周四午夜0点以来总共经历的秒数。本例中的1388185914对应的时间是UTC时间2013年12月27日23:11:54,星期五。
接下来,Jing的节点需要填充Target字段(难度目标值),这个字段定义了使该区块有效所需满足的工作量证明。难度目标作为“目标位target bits”度量存储在区块中,该度量以“尾数-指数”格式编码。这种编码用1个字节表示指数,后面的3字节表示尾数(系数)。例如区块277316,难度位的值为0x1903a30c,0x19是指数的十六进制格式,后半部0x03a30c是系数。这部分的概念在后面的【10.7.3 难度目标与难度调整】和【10.7.2 难度表示】有详细的解释。
最后一个字段是随机数nonce,初始值为0。
在所有字段都已填充的情况下,区块头现在已完成,可以开始挖矿过程。挖矿的目标是找到一个使区块头哈希值小于难度目标的随机数nonce。挖矿节点通常需要尝试数十亿甚至数万亿个不同的随机数取值,直到找到一个满足条件的值。
10.7 构建区块
Jing的节点已经构建了一个候选区块,接下来就该Jing的矿机“挖掘”这个新区块,找到一个使该区块有效的工作证明算法的解决方案。从本书中我们已经学习了加密哈希函数可以用在比特币系统的不同方面。比特币挖矿过程使用的是SHA256哈希函数。
用最简单的术语来说,挖矿就是对区块头重复哈希计算,然后不断修改一个参数,直到得到的哈希值与难度目标相匹配的过程。哈希函数的结果不能预先确定,也不能创建生成特定哈希值的模式。哈希函数的这个特性意味着:找到匹配特定难度目标的最终哈希值的唯一方法就是不断的尝试,每次随机修改输入,直到偶然出现所需的哈希值。
10.7.1 工作量证明算法
哈希算法就是输入一个任意长度的数据,输出一个固定长度的确定性值,称之为输入的数字指纹。对于特定输入,结果哈希值每次都一样,任何人都可以用相同的哈希算法,很容易地计算和验证。加密哈希函数的主要特征就是在计算上不可能找到产生相同指纹的两个不同输入(称为碰撞)。因此,除了尝试随机输入之外,不可能选择特定输入产生期望的指纹。
无论输入的大小是多少,SHA256函数的输出的长度总是256bit。在例10-8中,我们将使用Python解释器来计算语句 "I am Satoshi Nakamoto" 的SHA256的哈希值。
例10-8 SHA256示例
$ python
Python 2.7.1
>>> import hashlib
>>> print hashlib.sha256("I am Satoshi Nakamoto").hexdigest()
5d7c7ba21cbbcd75d14800b100252d5b428e5b1213d27c385bc141ca6b47989e
在例10-8中, 5d7c7ba21cbbcd75d14800b100252d5b428e5b1213d27c385bc141ca6b47989e 是"I am Satoshi Nakamoto"的哈希值。这个256位数字是这句短语的哈希或摘要,与短语的每一部分相关。改变原句中的任何一个字母、标点、或增加字母都会产生不同的哈希值。
如果我们改变原句,得到的应该是完全不同的哈希值。 例如,我们在句子末尾加上一个数字,运行例10-9中的简单Python脚本。
例10-9 通过反复修改 nonce 来生成不同哈希值的脚本(SHA256)
# example of iterating a nonce in a hashing algorithm's input
from __future__ import print_function
import hashlib
text = "I am Satoshi Nakamoto"
# iterate nonce from 0 to 19
for nonce in range(20):
# add the nonce to the end of the text
input_data = text + str(nonce)
# calculate the SHA-256 hash of the input (text+nonce)
hash_data = hashlib.sha256(input_data.encode()).hexdigest()
# show the input and hash result
print(input_data, '=>', hash_data)
执行这个脚本就能生成末尾数字不同的语句的哈希值。例10-10 中显示了我们只是增加了这个数字,却得到了完全不同的哈希值。
例10-10 上面例10-9脚本的输出
$ python hash_example.py
I am Satoshi Nakamoto0 => a80a81401765c8eddee25df36728d732...
I am Satoshi Nakamoto1 => f7bc9a6304a4647bb41241a677b5345f...
I am Satoshi Nakamoto2 => ea758a8134b115298a1583ffb80ae629...
I am Satoshi Nakamoto3 => bfa9779618ff072c903d773de30c99bd...
I am Satoshi Nakamoto4 => bce8564de9a83c18c31944a66bde992f...
I am Satoshi Nakamoto5 => eb362c3cf3479be0a97a20163589038e...
I am Satoshi Nakamoto6 => 4a2fd48e3be420d0d28e202360cfbaba...
I am Satoshi Nakamoto7 => 790b5a1349a5f2b909bf74d0d166b17a...
I am Satoshi Nakamoto8 => 702c45e5b15aa54b625d68dd947f1597...
I am Satoshi Nakamoto9 => 7007cf7dd40f5e933cd89fff5b791ff0...
I am Satoshi Nakamoto10 => c2f38c81992f4614206a21537bd634a...
I am Satoshi Nakamoto11 => 7045da6ed8a914690f087690e1e8d66...
I am Satoshi Nakamoto12 => 60f01db30c1a0d4cbce2b4b22e88b9b...
I am Satoshi Nakamoto13 => 0ebc56d59a34f5082aaef3d66b37a66...
I am Satoshi Nakamoto14 => 27ead1ca85da66981fd9da01a8c6816...
I am Satoshi Nakamoto15 => 394809fb809c5f83ce97ab554a2812c...
I am Satoshi Nakamoto16 => 8fa4992219df33f50834465d3047429...
I am Satoshi Nakamoto17 => dca9b8b4f8d8e1521fa4eaa46f4f0cd...
I am Satoshi Nakamoto18 => 9989a401b2a3a318b01e9ca9a22b0f3...
I am Satoshi Nakamoto19 => cda56022ecb5b67b2bc93a2d764e75f...
每个语句都生成了一个完全不同的哈希值。它们看起来是完全随机的,但你在任何计算机上用Python执行上面的脚本都能重现这些完全相同的哈希值。
上述场景中在语句末尾的变化的数字叫做随机数nonce。随机数是用来改变加密函数输出的,在这个示例中用于改变这个语句的 SHA256指纹。
为了使这个哈希算法变得富有挑战,我们来设定一个目标:找到一个语句,生成的16进制哈希值第一位是0。幸运的是,这很容易!在例10-10中语句 "I am Satoshi Nakamoto13" 的哈希值是 0ebc56d59a34f5082aaef3d66b37a661696c2b618e62432727216ba9531041a5 ,刚好满足条件。我们得到它用了13次。从概率的角度来看,如果哈希函数的输出是平均分布的,我们可以期望每16次(十六进制数字从0到F)就可以得到一个以0开头的16进制哈希值。从数字的角度来看,我们要找的是小于 0x1000000000000000000000000000000000000000000000000000000000000000 的哈希值。我们称这个阈值为难度目标Target,我们的目的是找到一个小于这个难度目标的哈希值。如果我们减小这个目标值,那找到一个小于它的哈希值会越来越难。
简单打个比方,想象人们不断扔一对骰子以得到小于一个特定点数的游戏。第一局,目标是12。只要你不扔出两个6, 你就会赢。然后下一局目标为11。玩家只能扔10或更小的点数才能赢,不过也很简单。假如几局之后目标降低为了5。现在有一半机率以上扔出来的骰子点数加起来会超过5,因此无效。随着目标越来越小,要想赢的话,扔骰子的次数会指数级的上升。最终当目标为2时(最小可能点数),只有一个人平均扔36次或扔的次数中的2%,他才能赢。
从一个知道骰子游戏目标为2的观察者的角度来看,如果有人成功投了一个赢的骰子,可以假设他平均投了36次。换句话说,你可以从目标所带来的困难中估算出成功所需的工作量。当该算法基于确定函数(如SHA256)时,输入本身就构成了为产生低于难度目标值的结果而做了一定工作量的证明。因此,称之为工作量证明Proof-of-Work。
提示:尽管每次尝试产生一个随机的结果,但是任何可能的结果的概率可以预先计算。 因此,指定特定难度目标的结果构成了特定的工作量证明。
在例10-10中,成功的随机数为13,且这个结果能被所有人独立确认。任何人将13加到语句 "I am Satoshi Nakamoto" 后面再计算哈希值都能确认它比目标值要小。这个成功的结果同时也是工作量证明,因为它证明找到了这个随机数所做的工作。虽然验证这个哈希值只需要一次计算,但是找到有效的随机数却花了13次哈希计算。如果目标值更小(难度更大),那我们需要多得多的哈希计算才能找到合适的随机数,但其他人验证它时只需要一次哈希计算。此外,知道难度目标值后,任何人都可以用统计学来估算其难度,因此就能知道找到一个随机数需要多少工作量。
提示:工作量证明必须产生小于难度目标的哈希值。 更高的目标意味着不难找到低于目标的哈希。较低的目标意味着在目标下方更难找到哈希。目标和难度是成反比。
比特币的工作量证明和例10-10中的挑战非常类似。矿工用一些交易构建一个候选区块。接下来,矿工计算这个区块头的哈希值,看其是否小于当前难度目标值。如果这个哈希值不小于目标值,矿工就会修改随机数(通常将之加1)然后再试一次。按当前比特币系统的难度,矿工得试数万亿次才能找到一个合适的随机数,使区块头哈希值足够小。
例10-11是一个简化很多的工作量证明算法的实现。
例10-11 简化的工作量证明算法
#!/usr/bin/env python
# example of proof-of-work algorithm
import hashlib
import time
try:
long # Python 2
xrange
except NameError:
long = int # Python 3
xrange = range
max_nonce = 2 ** 32 # 4 billion
def proof_of_work(header, difficulty_bits):
# calculate the difficulty target
target = 2 ** (256 - difficulty_bits)
for nonce in xrange(max_nonce):
hash_result = hashlib.sha256((str(header) + str(nonce)).encode()).hexdigest()
# check if this is a valid result, below the target
if long(hash_result, 16) < target:
print("Success with nonce %d" % nonce)
print("Hash is %s" % hash_result)
return (hash_result, nonce)
print("Failed after %d (max_nonce) tries" % nonce)
return nonce
if __name__ == '__main__':
nonce = 0
hash_result = ''
# difficulty from 0 to 31 bits
for difficulty_bits in xrange(32):
difficulty = 2 ** difficulty_bits
print("Difficulty: %ld (%d bits)" % (difficulty, difficulty_bits))
print("Starting search...")
# checkpoint the current time
start_time = time.time()
# make a new block which includes the hash from the previous block
# we fake a block of transactions - just a string
new_block = 'test block with transactions' + hash_result
# find a valid nonce for the new block
(hash_result, nonce) = proof_of_work(new_block, difficulty_bits)
# checkpoint how long it took to find a result
end_time = time.time()
elapsed_time = end_time - start_time
print("Elapsed Time: %.4f seconds" % elapsed_time)
if elapsed_time > 0:
# estimate the hashes per second
hash_power = float(long(nonce) / elapsed_time)
print("Hashing Power: %ld hashes per second" % hash_power)
你可以任意调整难度值(按二进制bit数来设定,即哈希值开头多少个bit必须是0)。然后执行代码,看看在你的计算机上求解需要多久。在例10-12中,你可以看到该程序在一个普通笔记本电脑上的执行情况。
例10-12 多种难度值的工作量证明算法的运行输出
$ python proof-of-work-example.py*
Difficulty: 1 (0 bits)
[...]
Difficulty: 8 (3 bits)
Starting search...
Success with nonce 9
Hash is 1c1c105e65b47142f028a8f93ddf3dabb9260491bc64474738133ce5256cb3c1
Elapsed Time: 0.0004 seconds
Hashing Power: 25065 hashes per second
Difficulty: 16 (4 bits)
Starting search...
Success with nonce 25
Hash is 0f7becfd3bcd1a82e06663c97176add89e7cae0268de46f94e7e11bc3863e148
Elapsed Time: 0.0005 seconds
Hashing Power: 52507 hashes per second
Difficulty: 32 (5 bits)
Starting search...
Success with nonce 36
Hash is 029ae6e5004302a120630adcbb808452346ab1cf0b94c5189ba8bac1d47e7903
Elapsed Time: 0.0006 seconds
Hashing Power: 58164 hashes per second
[...]
Difficulty: 4194304 (22 bits)
Starting search...
Success with nonce 1759164
Hash is 0000008bb8f0e731f0496b8e530da984e85fb3cd2bd81882fe8ba3610b6cefc3
Elapsed Time: 13.3201 seconds
Hashing Power: 132068 hashes per second
Difficulty: 8388608 (23 bits)
Starting search...
Success with nonce 14214729
Hash is 000001408cf12dbd20fcba6372a223e098d58786c6ff93488a9f74f5df4df0a3
Elapsed Time: 110.1507 seconds
Hashing Power: 129048 hashes per second
Difficulty: 16777216 (24 bits)
Starting search...
Success with nonce 24586379
Hash is 0000002c3d6b370fccd699708d1b7cb4a94388595171366b944d68b2acce8b95
Elapsed Time: 195.2991 seconds
Hashing Power: 125890 hashes per second
[...]
Difficulty: 67108864 (26 bits)
Starting search...
Success with nonce 84561291
Hash is 0000001f0ea21e676b6dde5ad429b9d131a9f2b000802ab2f169cbca22b1e21a
Elapsed Time: 665.0949 seconds
Hashing Power: 127141 hashes per second
你可以看出,随着难度位一位一位地增加,查找正确结果的时间会加倍增长。如果考虑整个256bit数字空间,每次要求多一个0,就把哈希查找空间缩减了一半。在例10-12中,为寻找一个随机数使得哈希值开头的26位值为0,一共尝试了8千多万次。即使笔记本电脑每秒可以达120,000多次哈希计算,找到结果依然需要10分钟。
在写这本书的时候,比特币网络要寻找区块头信息哈希值小于
0000000000000000029AB9000000000000000000000000000000000000000000
可以看出,这个难度目标开头的0多了很多。这意味着可接受的哈希值范围大幅缩减,因而找到正确的哈希值更加困难。网络平均每秒要花费超过1.8个zeta次哈希(千亿个哈希)才能发现下一个区块。这似乎是一项不可能完成的任务,但幸运的是,网络每秒有3exa次哈希(EH/sec)的处理能力,平均10分钟左右就能找到一个区块。
10.7.2 难度表示
在例10-3中,我们看到区块中包含难度目标,其被标为"目标位"或简称"bits"。在区块277,316中,它的值为 0x1903a30c。 这个标记的值被存为系数/指数格式,前两位16进制数字为指数,接下来6位16进制数字为系数。在这个区块里,0x19为指数,而 0x03a30c为系数。
计算难度目标的公式为:
目标target = 系数coefficient 2(8 (指数exponent – 3))</sup>
由此公式及难度位的值 0x1903a30c,可得:
目标 = 0x03a30c 20x08(0x19-0x03)</sup>
=> 目标 = 0x03a30c 2(0x080x16)</sup>
=> 目标 = 0x03a30c * 20xB0
按十进制计算为:
=> 目标 = 238,348 * 2176
=> 目标 = 22,829,202,948,393,929,850,749,706,076,701,368,331,072,452,018,388,575,715,328
转换为16进制:
=> 目标 = 0x0000000000000003A30C00000000000000000000000000000000000000000000
也就是说高度为277,316的有效区块的头信息哈希值是小于这个目标值的。这个数字用二进制表示,开头超过60位都是0。在 这个难度上,一个每秒可以处理1万亿次哈希计算的矿工(1 tera-hash每秒简称 1 TH/sec)平均每8,496个区块才能找到一个正确结果,换句话说,平均每59天,才能为某一个区块找到正确的哈希值。
10.7.3 难度目标与难度调整
如前所述,目标决定了难度,进而影响求解工作量证明算法所需要的时间。那么问题来了:为什么这个难度值是可调整的?由谁来调整?如何调整?
比特币的区块平均每10分钟生成一个。这就是比特币的心跳,是货币发行频率和交易达成速度的基础。不仅在短期内,还要在几十年内都必须要保持恒定。在此期间,计算机性能将飞速提升。此外,参与挖矿的人和计算机也会不断变化。为了能让新区块生成时间保持10分钟,挖矿的难度必须可以根据这些变化进行调整。事实上,工作量证明的难度目标是一个动态的参数,会周期调整以达到每10分钟一个新区块的间隔目标。简单地说,设定目标是为了使当前的挖矿能力产生10分钟的区块间隔。
那么,在一个完全去中心化的网络中,这样的调整是如何做到的呢?重新调整目标是自动发生的,并且是每个节点独立进行的。每2,016个区块,所有节点都会重新调整难度目标。难度目标的调整公式测量了找到最后2016个区块所用的时间,并将其与预期时间20160分钟(2016个区块乘以预期的10分钟区块间隔)进行了比较。首先计算实际时间间隔和所需时间间隔之间的比率,然后对目标进行比例调整(向上或向下)。简单地说,如果网络找到一个区块的速度比10分钟快,难度就会增加(目标减少)。如果区块发现速度慢于预期,则难度降低(目标增加)。
难度(或目标值)调整公式可以总结为如下形式:
New Difficulty = Old Difficulty * (20160 minutes / Actual Time of Last 2016 Blocks)
New Target = Old Target * (Actual Time of Last 2016 Blocks / 20160 minutes)
例10-13展示了Bitcoin Core客户端中的难度调整代码。
例10-13 源文件pow.cpp中的工作量证明的难度调整CalculateNextWorkRequired()函数
// Limit adjustment step
int64_t nActualTimespan = pindexLast->GetBlockTime() - nFirstBlockTime;
LogPrintf(" nActualTimespan = %d before bounds\n", nActualTimespan);
if (nActualTimespan < params.nPowTargetTimespan/4)
nActualTimespan = params.nPowTargetTimespan/4;
if (nActualTimespan > params.nPowTargetTimespan*4)
nActualTimespan = params.nPowTargetTimespan*4;
// Retarget
const arith_uint256 bnPowLimit = UintToArith256(params.powLimit);
arith_uint256 bnNew;
arith_uint256 bnOld;
bnNew.SetCompact(pindexLast->nBits);
bnOld = bnNew;
bnNew *= nActualTimespan;
bnNew /= params.nPowTargetTimespan;
if (bnNew > bnPowLimit)
bnNew = bnPowLimit;
注意:虽然目标调整每2,016个区块发生一次,但是由于Bitcoin Core客户端的一个错误,它是基于之前的2,015个区块的总时间(而不是2,016个),导致目标调整出现偏差,向较高难度提高0.05%。
参数Interval(2,016区块)和TargetTimespan(1,209,600秒即两周)的定义在文件chainparams.cpp中。
为了防止难度变化过快波动,每个周期的调整幅度必须小于4倍。如果所需的目标要调整的幅度大于4倍,则按4倍调整,不会超过4倍。任何进一步的调整都将在下一个目标调整期内完成,因为这种不平衡将持续到后面的2016个区块。因此,哈希能力和难度之间的巨大差异可能需要几个2016区块周期来平衡。
提示:寻找一个比特币区块需要整个网络花费10分钟来处理,基于前2016个区块挖矿所需的时间,每2016个区块调整一次。这是通过降低或提高难度目标来实现的。
值得注意的是目标难度与交易的数量和金额无关。比特币安全所需的哈希运算能力以及由此产生的电量也和交易数量无关。比特币可以扩大规模,被更广泛的采用,并保持安全,但不是一定需要增加当前的算力能力水平。随着新矿工进入市场争夺奖金,哈希算力的增加代表了市场力量。只要诚实地追求回报的矿工们保持足够的哈希算力,就足以防止“接管”攻击,因此,确保比特币的安全。
目标难度和挖矿电力消耗与将比特币兑换成现金以支付这些电力之间的关系密切相关。随着当前硅制造技术的发展,高性能挖矿系统将尽可能高效,尽可能高的速度将电能转换为哈希算力。挖矿市场的关键因素就是每千瓦时的比特币电价,因为这决定着挖矿的赢利能力,也因此刺激着人们选择进入或退出挖矿市场。
10.8 成功挖出区块
前面已经看到,Jing的节点创建了一个候选区块,准备用来挖矿。Jing有几台ASIC(专用集成电路)矿机, 上面有成千上万个集成电路可以超高速地并行运行SHA256算法。许多专用机器通过USB或者局域网连接到他的挖矿节点上。接下来,运行在Jing的电脑上的挖矿节点将区块头信息传送给这些硬件,让它们以每秒亿万次的速度进行随机数测试。由于随机数只有32位,在耗尽所有随机数可能性(大约40亿)之后,挖矿硬件更改区块头(调整coinbase额外的随机数空间或时间戳),并重置随机数计数器,测试新的组合。
在对区块277,316的挖矿工作开始大概11分钟后,这些硬件里的其中一个找到了解并发回挖矿节点。
当把这个随机数924,591,752 放进区块头时,就会产生一个区块哈希值:
0000000000000001b6b9a13b095e96db41c4a928b97ef2d944a9b31b2cc7bdc4
而这个值小于难度目标值:
0000000000000003A30C00000000000000000000000000000000000000000000
Jing的挖矿节点立刻将这个区块发给它所有的对等节点。这些节点在接收并验证这个新区块后,也会继续传播此区块。当这个新区块在网络中扩散时,每个节点将其添加到自己的区块链副本中,将区块链扩展到277,316个区块的新高度。当挖矿节点收到并验证了这个新区块后,它们会放弃之前对构建这个相同高度区块的计算,使用JING的区块作为父区块,立即开始计算区块链中下一个区块。
在下一节中,我们将查看每个节点验证区块和选择最长链,并以此形成一个去中心化区块链共识的过程。
10.9 验证新区块
比特币共识机制的第三步是网络中的每个节点独立校验每个新区块。当新解出的区块在网络中传播时,每一个节点在将它转发到其节点之前,会进行一系列的测试去验证它。这确保了只有有效的区块会在网络中传播。独立校验还确保了诚实的矿工生成的区块可以被纳入到区块链中,从而获得奖励。行为不诚实的矿工所产生的区块将被拒绝,这不但使他们失去了奖励,而且也浪费了寻找工作量证明解的努力,因而导致电费亏损。
当一个节点接收到一个新的区块,它将对照一个长长的标准清单中列出的必须满足的条件对该区块进行验证,若没有通过验证,这个区块将被拒绝。这些标准可以在Bitcoin Core客户端的CheckBlock函数和CheckBlockHead函数中获得。
它包括:
区块的数据结构语法上有效
区块头的哈希值小于目标难度(确认执行工作量证明)
区块时间戳早于验证时刻未来两个小时(允许时间错误)
区块大小在长度限制之内
第一个交易(且只有第一个)是创币交易
使用【10.3 交易的独立验证】检查清单验证区块内的交易并确保它们的有效性
网络上每个节点对每个新区块的独立验证确保了矿工不会作弊。在前面的章节中,我们看到了矿工们如何去记录一笔交易,以获得在此区块中创造的新比特币和交易费。为什么矿工不为他们自己记录一笔交易去获得数以千计的比特币?这是因为每一个节点根据相同的规则对区块进行校验。一个无效的创币交易将使整个区块无效,这将导致该区块被拒绝,因此,该交易就永远不会成为总账的一部分。矿工们必须基于所有节点共享的规则,构建一个完美的区块,并且根据正确的工作量证明的解决方案进行挖矿,他们要花费大量的电力挖矿才能做到这一点。如果他们作弊,所有的电力和努力都会浪费。这就是独立验证是去中心化共识的重要组成部分的原因。
10.10 区块链的组装与选择
比特币去中心化共识机制的最后一步是将区块组装成区块链,并选择累积最大工作证明的区块链。一旦一个节点验证了一个新的区块,它将尝试通过将它连接到现有的区块链来组装一个区块链。
节点维护三种区块:第一种是连接到主链上的区块,第二种是主链的分支(候选链)的区块,最后一种是在已知链中没有找到父区块的区块(孤块)。在验证过程中,一旦验证标准中任何一条失败,这个区块就会被节点拒绝,所以也不会包含到任何一条链中。
任何时候,主链都是累计了最多工作量证明的有效区块组成的链。在大多数情况下,主链也是包含最多区块的那个链,除非有两个等长的链并且其中一个有更多的工作量证明。主链也会有一些分支,这些分支中的区块与主链上的区块互为“兄弟”区块。这些区块是有效的,但不是主链的一部分。保留这些分支的目的是如果在未来的某个时刻它们中的一个延长了并在工作量上超过了主链,那么后续的区块就会引用它们。在【10.10.1 区块链分叉】,我们将会看到在同样的区块高度,几乎同时挖出区块时,候选链是如何产生的。
当节点接收到新区块,它会尝试将这个区块插入到现有区块链中。节点会看一下这个区块的“previous block hash”字 段,这个字段是该区块对其父区块的引用。然后,新的节点将尝试在已存在的区块链中找出它的父区块。大多数情况下,父区块是主块链的“末端”,这就意味着这个新的区块延长了主链。举个例子,一个新的区块277,316引用了它的父区块277,315。收到277,316区块的大部分节点都已经将277,315最为主链的末端,因此,将会连接这个新区块并延长区块链。
有时候,就像在【10.10.1 区块链分叉】看到的,新区块所延长的区块链并不是主链。在这种情况下,节点将新的区块添加到候选链,同时比较候选链与主链的工作量。如果候选链比主链积累了更多的工作量,节点将收敛于候选链,意味着节点将选择候选链作为其新的主链,而之前那个老的主链则成为了候选链。如果节点是一个矿工,它将开始构造新的区块,来延长这个更新更长的区块链。
如果节点收到了一个有效的区块,而在现有的区块链中却未找到它的父区块,那么这个区块被认为是“孤块”。孤块会被保存在孤块池中,直到它们的父区块被节点收到。一旦收到了父区块并且将其连接到现有区块链上,节点就会将孤块从孤块池中取出,连接到它的父区块,让它作为区块链的一部分。当两个区块在很短的时间间隔内被挖出来,节点接收到它们的顺序可能是相反的(子比父先到),这个时候孤块现象就会出现。
选择了最大难度的区块链后,所有的节点最终在全网范围内达成共识。随着更多的工作量证明被添加到链中,链的暂时性差异最终会得到解决,从而扩展可能的链中的一条。挖矿节点通过挖出下一个区块来选择要扩展的链,从而用它们的挖矿算力进行“投票”。当它们挖出一个新区块并且延长了一个链,新区块本身就代表它们的投票。
在下一节中,我们将研究如何通过独立选择累积最大工作量来解决竞争链(分叉)之间的差异。
10.10.1 区块链分叉
因为区块链是去中心化的数据结构,所以不同副本之间不能总是保持一致。区块有可能在不同时间到达不同节点,导致不同的节点有不同的区块链全貌。解决的办法是,每一个节点总是选择并尝试延长代表累计了最大工作量证明的区块链,也就最长的或最大累计工作链(greatest cumulative work chain)。节点通过累加链上的每个区块的工作量,计算创建这个链所付出的累积工作量。只要所有的节点选择最大累计工作链,整个比特币网络最终会收敛到一致的状态。分叉即在不同版本区块链间发生的临时不一致,当更多的区块添加到了某个分叉中,这个问题会被最终的再收敛解决。
提示 本节中描述的区块链分叉是由于全球网络中的传输延迟而自然发生的。 我们也将在本章稍后再看看故意引起的分叉。
在接下来的几个图表中,我们将通过网络跟踪“分叉”事件的进展。该图是比特币网络的简化表示。为了便于描述,不同的区块被显示为不同的形状(星形,三角形,倒三角形,菱形),遍布网络。 网络中的每个圆表示一个节点。
每个节点都有自己的全局区块链视图。当每个节点从其邻居接收区块时,它会更新自己的区块链副本,选择最大累积工作链。 为便于描述,每个节点包含一个图形形状,表示它认为是主链的顶端的区块。 因此,如果在节点里面看到星形,那就意味着该节点认为星形区块处于主链的顶端。
在第一张图(图10-2)中,网络有一个统一的区块链视角,以星形区块为主链的顶端。
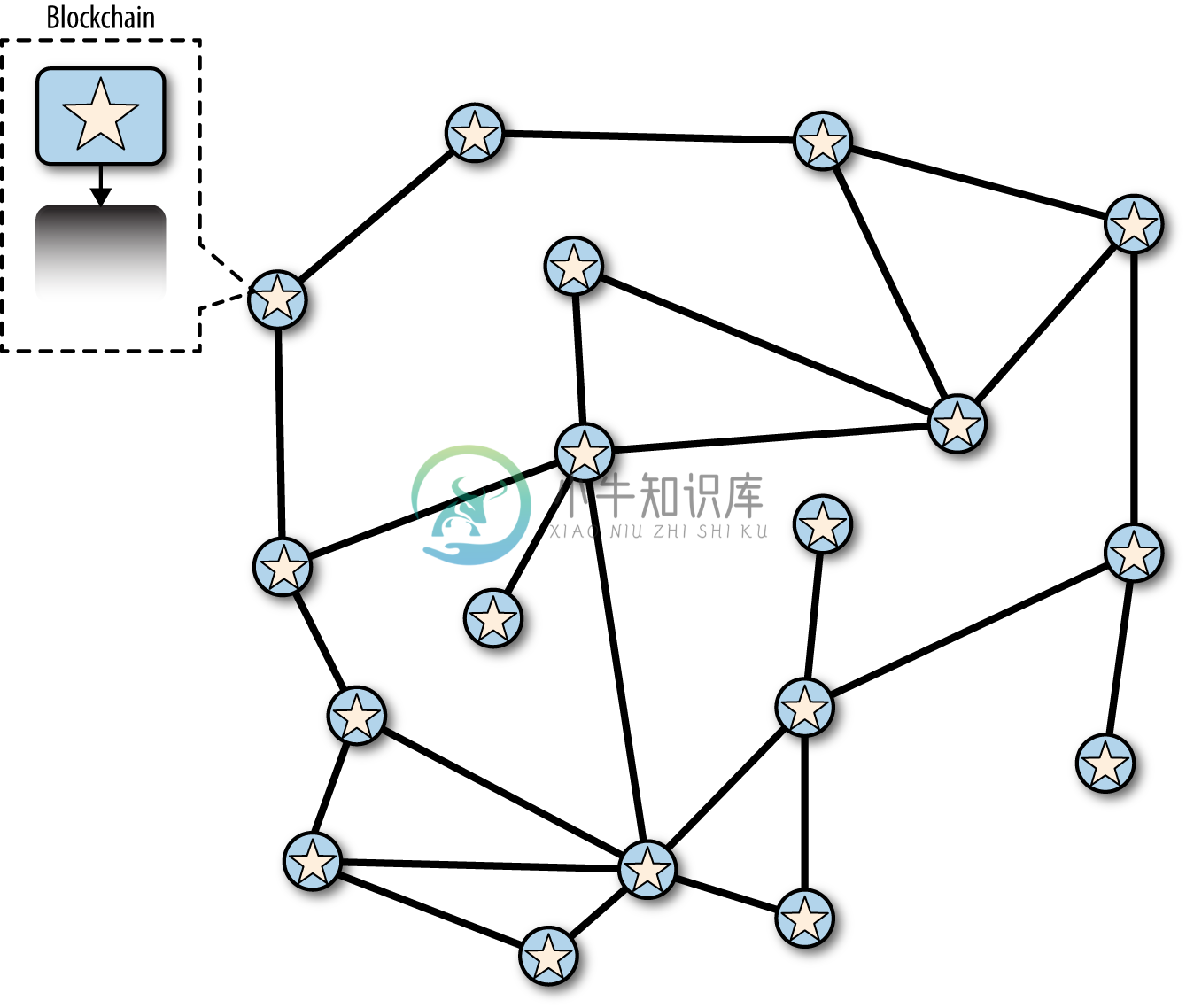
图10-2 分叉前所有节点都有相同的全貌
当有两个候选区块出现竞争同时想要延长最长区块链时,分叉事件就会发生。正常情况下,分叉发生在两名矿工在较短的时间内,各自都算得了工作量证明解的时候。两个矿工在各自的候选区块一发现解,便立即传播自己的“获胜”区块给邻近的节点,后者开始在网络上传播。每个收到有效区块的节点都会将其合并到自己的区块链中,为区块链延长一个区块。如果该节点随后看到另一个候选区块,在扩展同样的父区块,那么节点会将这个区块连接到候选链上。其结果是,一些节点收到了一个候选区块,而另一些节点收到了另一个候选区块,这时两个竞争版本的区块链就出现了。
在图10-3中,我们看到两个矿工(节点X和节点Y)几乎同时挖到了两个不同的区块。这两个区块都是星形区块的子区块,构造在星形区块顶端延长这个区块链。为了方便查看,我们把节点X产生的区块标记为三角形,把节点Y生产的区块标记为倒三角形。
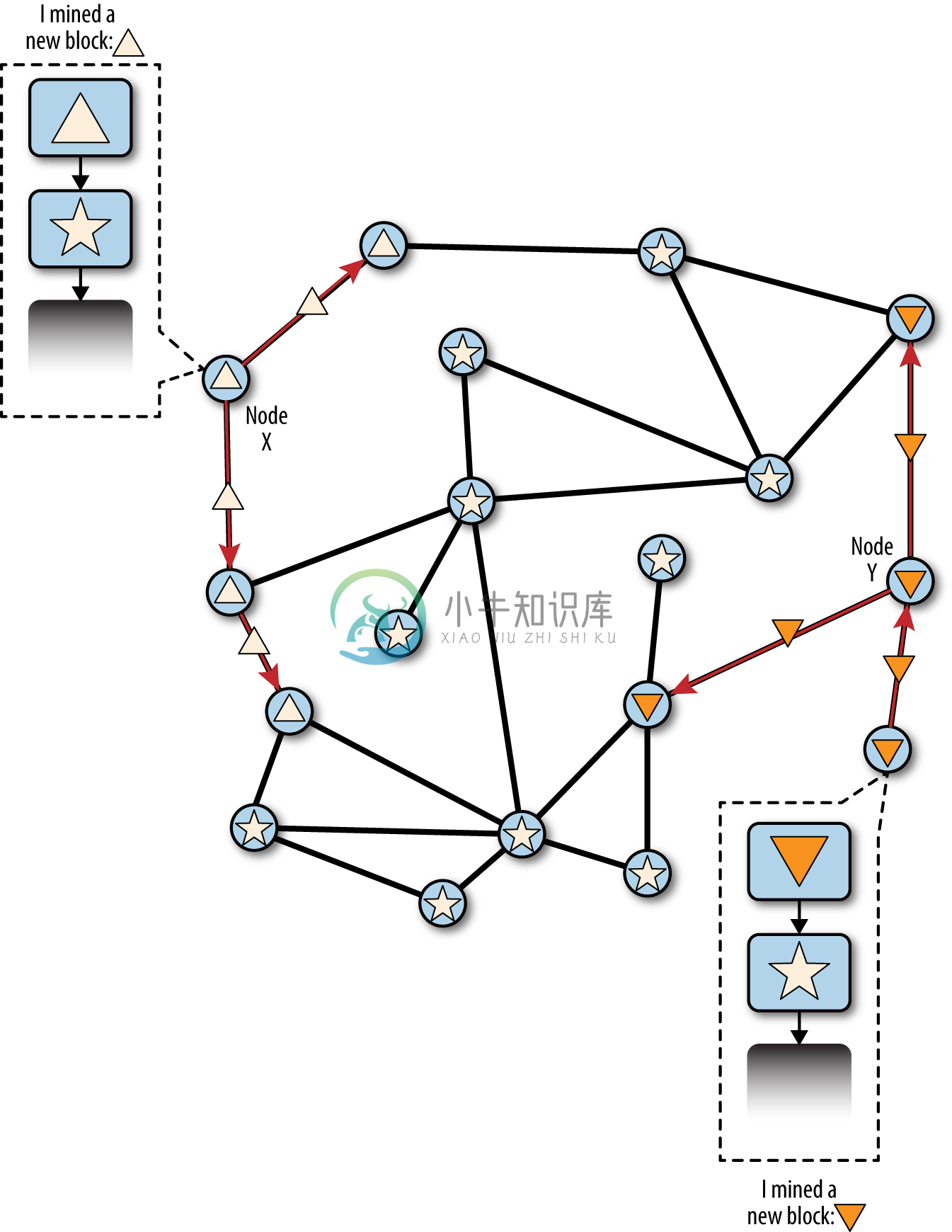
图10-3 区块链分叉事件的可视化:同时找到两个区块
例如,我们假设矿工节点X找到扩展区块链工作量证明的解,即三角形区块,构建在星形父区块的顶端。与此同时,同样进行星形区块扩展的节点Y也找到了扩展区块链工作量证明的解,它使用倒三角形区块作为候选区块。现在有两个可能的区块,节点X的三角形区块和节点Y的倒三角形区块,这两个区块都是有效的,均包含有效的工作量证明解并延长同一个父区块。这个两个区块可能包含了几乎相同的交易,只是在交易的排序上有些许不同。
当两个区块开始在网络传播时,一些节点首先接收到三角形区块,另外一些节点首先接收倒三角形区块。如下图10-4所示,比特币网络被分成了两个不同的区块链视角,一边以三角形区块为顶点,而另一边以倒三角形区块为顶点。
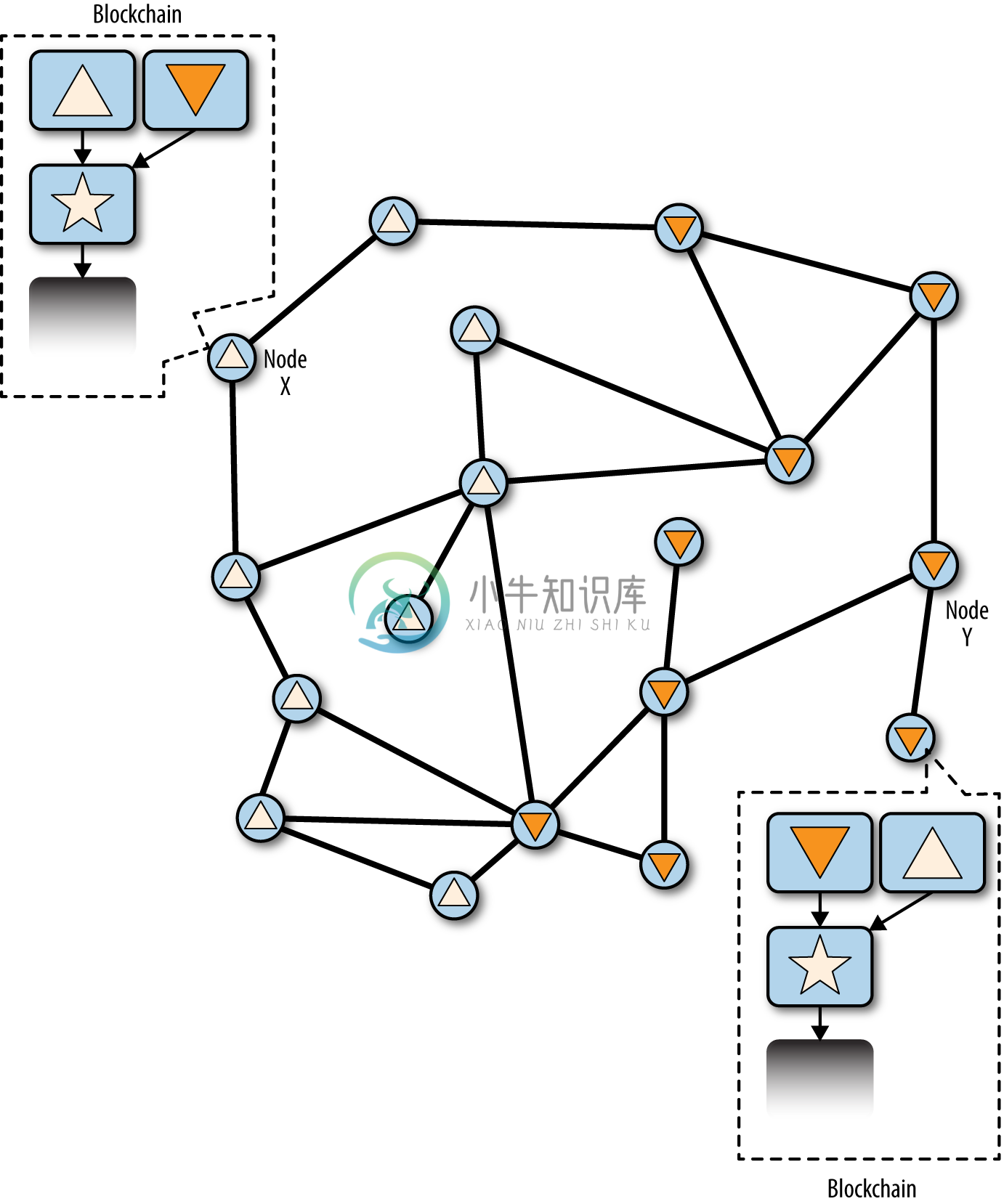
图10-4 区块链分叉事件的可视化:两个区块传播,分割了网络
在图中,假设节点X首先接收到三角形块,并用它扩展星形链。节点X选择三角形区块为主链。之后,节点X也收到倒三角区块。由于是第二次收到,因此它判定这个倒三角形区块是竞争失败的产物。然而,倒三角形的区块不会被丢弃。它被链接到星形链的父区块,并形成候选链。虽然节点X认为自己已经正确选择了获胜链,但是它还会保存“失败”链,使得“失败”链如果可能最终“获胜”,它还具有重新收敛所需的信息。
在网络的另一端,节点Y根据自己的视角构建一个区块链。首先收到倒三角形区块,并选择这条链作为“赢家”。当它稍后收到三角形区块时,它也将三角形区块连接到星形链的父区块作为候选链。
双方都是“正确的”或“不正确的”。两者都是自己关于区块链的有效视角。只有事后,才能理解这两个竞争链如何通过额外的工作量得到延伸。
节点X阵营的其他节点将立即开始以“三角形”作为扩展区块链的顶端,挖掘候选区块。通过将三角形作为候选区块的父区块,它们用自己的哈希算力进行投票。它们的投票表明支持自己选择的链为主链。
同样,节点Y阵营的其他节点,将开始构建一个以倒三角形作为其父节点的候选区块,扩展它们认为是主链的链。比赛再次开始。
分叉问题几乎总是在一个区块内就被解决了。网络中的一部分算力专注于“三角形”区块为父区块;另一部分算力则专注在“倒三角形”区块上。即便算力在这两个阵营中平均分配,也总有一个阵营抢在另一个阵营前发现工作量证明解并将其传播出去。假如工作在“三角形”区块上的矿工找到了一个“菱形”区块延长了区块链(星形-三角形-菱形),他们会立刻传播这个新区块,整个网络会都会认为这个区块是有效的,如下图10-5所示。
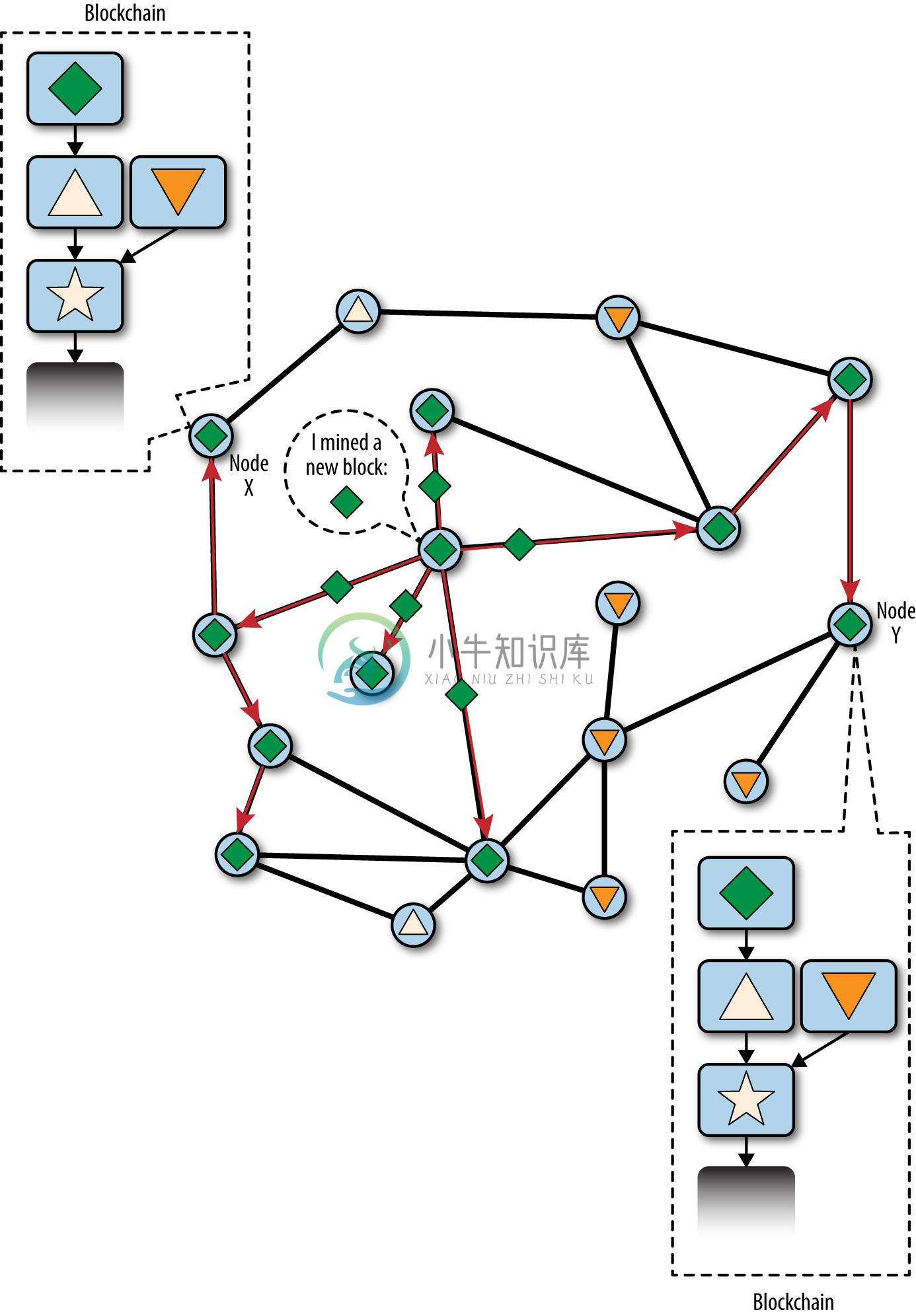
图10-5 区块链分叉事件的可视化:一个新的区块扩展一个分叉,重新收敛网络
所有在上一轮选择“三角形”胜出的节点只需简单地将区块链再扩展一个区块。然而,选择“倒三角”的节点现在将看到两个链:星形-三角形-菱形和星型-到三角形。星形-三角形-菱形这条链现在比其他链条更长(累积更多的工作量)。因此,这些节点将星形-三角形-菱形设置为主链,并将星型-倒三角形链变为候选链,如图10-6所示。这是一个链的重新收敛,因为这些节点被迫修改他们对块链的视角,把新证明纳入更长的链。任何延伸星形-倒三角形的矿工现在都将停止这项工作,因为他们的候选区块是“孤块”,其父区块“倒三角形”不再是最长的链。 “倒三角形”内的交易重新插入到内存池中用来包含在下一个区块中,成为主链的一部分。整个网络重新回到单一链状态,收敛为星形-三角形-菱形,“菱形”成为链中的最后一个区块。所有矿工立即开始研究以“菱形”为父区块的候选块,以扩展这条星形-三角形-菱形链。
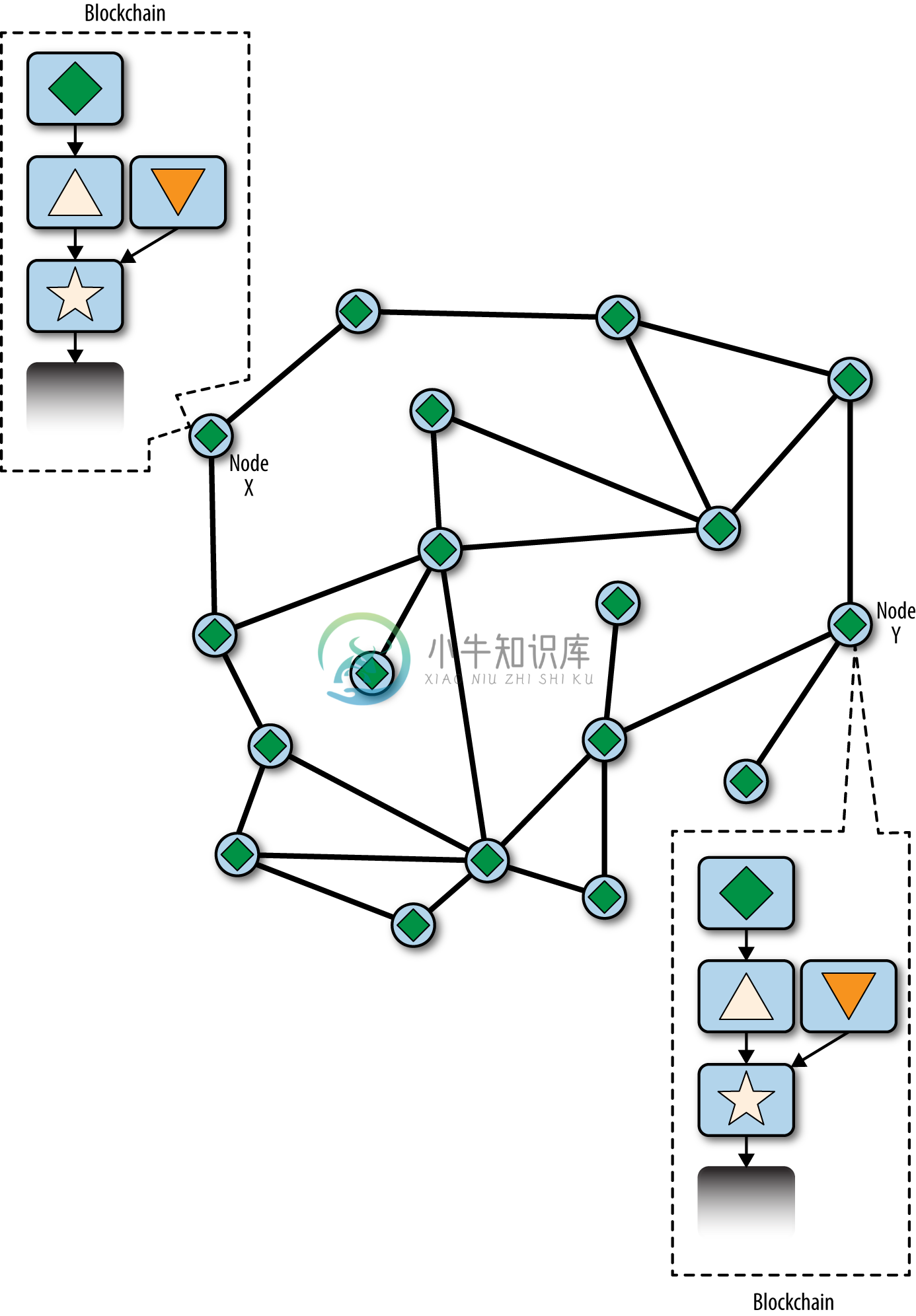
图10-6 区块链分叉事件的可视化:网络重新收敛在新的最长链上
从理论上来说,两个区块的分叉是有可能的,这种情况发生在因先前分叉而相互对立起来的矿工,又几乎同时发现了两个不同区块的解。然而,这种情况发生的几率是很低的。单区块分叉每天都会发生,而双区块分叉最多每几周才会出现一次。
比特币将区块间隔设计为10分钟,是在更快速的交易确认和更低的分叉概率间作出的妥协。更短的区块产生间隔会让交易清算更快地完成,也会导致更加频繁的区块链分叉。与之相对,更长的间隔会减少分叉数量,却会导致更长的清算时间。
10.11 挖矿和算力竞赛
比特币挖矿是一个极富竞争性的行业。比特币存在的每一年,哈希算力都成指数增长。一些年份的增长反映出技术的变革,比如在2010年和2011年,很多矿工开始从使用CPU升级到使用GPU,进而使用现场可编程门阵列(FPGA)进行挖矿。在2013年,ASIC挖矿的引入,把SHA256算法直接固化在挖矿专用的硅芯片上,导致了算力的另一次巨大飞跃。2010年,第一批这样的芯片可以在一个盒子里提供比整个比特币全网更多的挖矿算力。
下面的列表显示了比特币网络在网的前8年的总哈希算力:
2009 0.5 MH/sec–8 MH/sec (16× growth)
2010 8 MH/sec–116 GH/sec (14,500× growth)
2011 116 GH/sec–9 TH/sec (78× growth)
2012 9 TH/sec–23 TH/sec (2.56× growth)
2013 3 TH/sec–10 PH/sec (450× growth)
2014 10 PH/sec–300 PH/sec (30× growth)
2015 300 PH/sec-800 PH/sec (2.66× growth)
2016 800 PH/sec-2.5 EH/sec (3.12× growth)
在图10-7中,我们可以看到近两年里,比特币网络算力的增长。正如您所看到的,矿工之间的竞争和比特币的发展导致算力(网络中每秒的总哈希值)呈指数级增长。
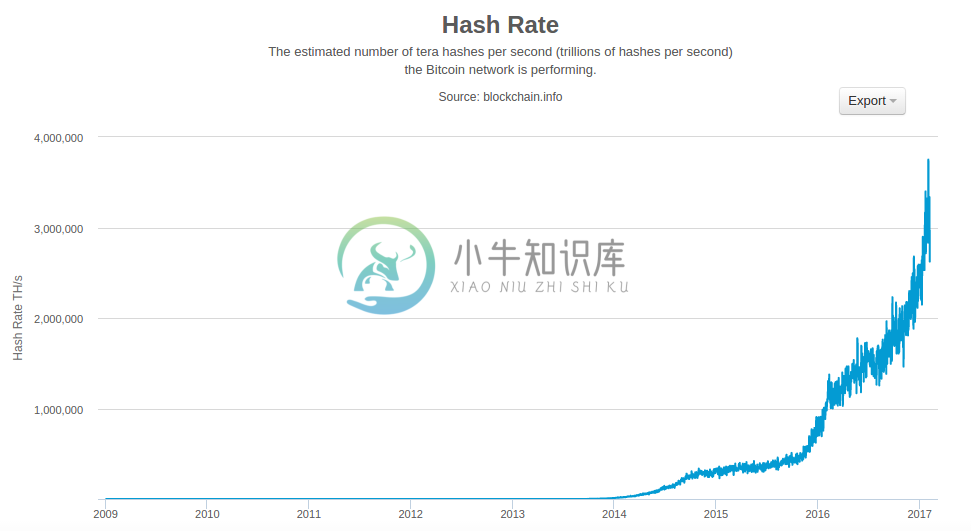
图10-7 总散列算力(TH/sec)
随着比特币挖矿算力的爆炸性增长,与之匹配的难度也相应增长。图10-8中的难度指标显示了当前难度与最小难度(第一个区块的难度)的比率。
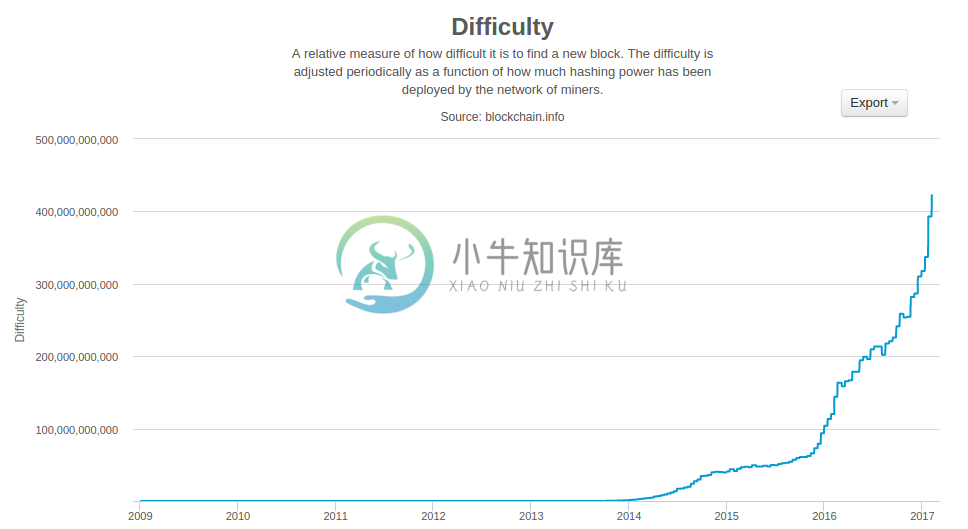
图10-8 比特币挖矿难度指标
近两年,ASIC芯片变得更加密集,已经接近芯片制造业前沿的16纳米特征尺寸。目前,由于挖矿的利润率驱动这个行业以比通用计算更快的速度发展,ASIC制造商的目标是超越通用CPU芯片制造商,设计特征尺寸为14纳米的芯片。对比特币挖矿而言,已经没有更多飞跃的空间,因为这个行业已经触及了摩尔定律的最前沿,摩尔定律是指计算密度每18个月翻一番。尽管如此,随着更高密度的芯片和高密度数据中心的部署竞赛,网络算力继续保持指数级增长,数据中心可以部署数千个这样的芯片。现在的竞争已经不再是比较单一芯片的能力,而是一个矿场能塞进多少芯片,还能处理好散热和供电问题。
10.11.1 额外随机数解决方案
2012年以来,比特币挖矿已经发展到需要解决区块头结构的基本限制。在比特币的早期,矿工可以通过遍历随机数,直到产生的哈希值低于目标值,从而挖到一个区块。难度增长后,矿工们经常循环查找了随机数的全部40亿个值,还是找不到区块。然而,这很容易通过更新区块的时间戳并计算经过的时间来解决。因为时间戳是区块头的一部分,它的变化可以让矿工用不同的随机数再次遍历。但是当挖矿硬件的速度达到了4GH/秒,这种方法变得越来越困难,因为随机数的取值范围在一秒内就被用尽了。当出现ASIC矿机并很快达到了TH/秒的哈希率后,挖矿软件为了找到有效的块,需要更多的空间来储存随机数值。可以把时间戳延后一点,但如果把它移动到太远的将来,会导致区块无效。区块头需要一个新的“更改”随机数值的来源。解决方案是使用创币交易作为额外的随机数值来源,因为创币脚本可以储存2-100字节的数据,矿工们开始使用这个空间作为额外随机数的来源,允许他们去探索一个大得多的区块头取值范围来找到有效的区块。这个创币交易也包含在默克尔树中,这意味着任何创币脚本的变化将导致默克尔树根的变化。8个字节的额外随机数,加上4个字节的“标准”随机数,允许矿工每秒尝试296(8后面跟28个零)种可能性而无需修改时间戳。如果未来矿工用尽了以上所有的可能性,他们还可以通过修改时间戳来解决。同样,创币脚本中也有更多额外的空间可以用于将来随机数的扩展。
10.11.2 矿池
在这个激烈竞争的环境中,个体矿工独立工作(也就是solo挖矿)没有一点机会。他们找到一个区块以抵消电力和硬件成本的可能性非常小,以至于可以称得上是赌博,或是买彩票。就算是最快的消费型ASIC矿机也不能和那些在巨大机房里拥有数万芯片并靠近水电站的商业矿场竞争。现在矿工们合作组成矿池,汇集数以千计参与者们的算力并分享奖励。通过参加矿池,矿工们虽然只能得到整体奖励的一小部分,但通常每天都能得到,因而减少了不确定性。
让我们来看一个具体的例子。假设一名矿工已经购买了算力共计14,000GH/S,或14TH/S的设备,在2017年,它的价值大约是2500美元。该设备运行功率为1375W(1.3KW),每日耗电33度,电价比较低的情况下每日成本1或2美元。以目前的比特币难度,该矿工独立挖矿方式挖出一个区块平均需要4年。我们如何计算出这个概率?这是基于全网哈希速率3EH/sec(2017年)和矿工速率14TH/sec计算的:
P = (14 1012 / 3 1018) * 210240 = 0.98
其中210240是4年内的区块数量。根据计算周期初的全网哈希率,该矿工在4年内找到区块的概率为98%。
如果这个矿工确实在这个时限内挖出一个区块,奖励6.25比特币,如果每个比特币价格约为1000美元,可以得到6,250美元的收入,这将产生净利润约750美元。然而,在4年的时间周期内能否挖出一个区块还主要靠矿工的运气。他有可能在4年中找到2个块从而赚到非常大的利润。或者,他可能5年都找不到一个块,从而遭受更大的经济损失。更糟的是,比特币的工作量证明算法的难度可能在这段时间内显著上升,按照目前算力增长的速度,意味着矿工在设备过时而必须被下一代更有效率的矿机取代之前,最多有1年的时间取得盈亏平衡。从财务数据分析,这只有非常低的电力成本(每千瓦不到1美分),非常大的规模时才有意义。
矿池通过专用挖矿协议协调成百上千的矿工。个人矿工在建立矿池账号后,设置他们的矿机连接到矿池服务器。他们的挖矿设备在挖矿时保持和矿池服务器的连接,和其他矿工同步各自的工作。这样,矿池中的矿工共同努力挖矿区块,之后分享奖励。
成功出块的奖励支付到矿池的比特币地址,而不是单个矿工的。一旦奖励达到一个特定的金额,矿池服务器便会定期支付奖励到矿工的比特币地址。通常情况下,矿池服务器会为提供矿池服务收取一定百分比的费用。
参加矿池的矿工把搜寻候选区块的工作量拆分,并根据他们挖矿的贡献赚取“份额”。矿池为赚取“份额”设置了一个较高的目标值(较低难度),通常比比特币网络的难度低1000倍以上。当矿池中有人成功挖出一个区块,矿池获得奖励,并按照矿工们做出算力贡献的份额的比例给他们分配奖励。
矿池对任何矿工开放,无论大小、专业或业余。一个矿池的参与者中,有人只有一台小矿机,而有些人有一车库高端挖矿硬件。有的只用几十度电挖矿,也有的会运营着一个消耗兆瓦级的电量的数据中心。矿池如何衡量每个人的贡献,既能公平分配奖励,又避免作弊的可能?答案是使用比特币的工作量证明算法来衡量每个矿池矿工的贡献,但设置的难度较小,以至于即使是矿池中最小的矿工也经常能分得奖励,这足以激励他们为矿池做出贡献。通过设置一个较低的取得份额的难度,矿池可以计量出每个矿工完成的工作量。每当矿工发现一个小于矿池难度的区块头散列值,就证明了它已经完成了分配给自己的寻找结果所需的哈希计算。更重要的是,寻找份额的工作以一种统计上可测量的方式,有助于找到比比特币网络目标更低的哈希值。成千上万试图寻找低哈希值的矿工最终会找到一个足够低的哈希值,满足比特币网络难度目标。
让我们回到骰子游戏的类比。如果骰子玩家的目标是扔骰子结果都小于4(整体网络难度),矿池可以设置一个更容易的目标,统计有多少次池中的玩家扔出的结果小于8。当池中的玩家扔出的结果小于8(矿池份额目标),他们得到份额,但他们没有赢得游戏,因为没有达到游戏目标(小于4)。但池中的玩家会经常地达到较容易的矿池份额目标,规律地赚取他们的份额,尽管他们没有达到赢得比赛的更难的目标。时不时地,池中的一个成员有可能会扔出一个小于4的结果,矿池就获胜了。然后,收益可以在池中玩家获得的份额基础上分配。尽管目标设置为8或更少并没有赢得游戏,但是这是一个衡量玩家们扔出的点数的公平方法,同时它偶尔会产生一个小于4的结果。
同样的,一个矿池也会设置(更高更容易)矿池难度目标,保证一个单独的矿工能够频繁找到一个小于矿池难度目标的区块头散列值来赢取份额。时不时的,某次尝试会产生一个符合比特币网络难度目标值的区块头散列值,成为一个有效区块,然后整个矿池获胜。
10.11.2.1 托管矿池
大部分矿池是“托管的”,意思是有一个公司或者个人经营一个矿池服务器。矿池服务器的所有者叫矿池经营者pool operator,同时他从矿工的收入中收取一定百分比的费用。
矿池服务器运行专业软件以及协调池中矿工们活动的矿池采矿协议。矿池服务器同时也连接到一个或更多比特币全节点,可以直接访问一个区块链数据库的完整副本。这使得矿池服务器可以代替矿池中的矿工验证区块和交易,缓解他们运行全节点的负担。对于矿池中的矿工,这是一个重要的考虑因素,因为一个全节点要求是一个拥有最少100-150GB的永久储存空间(磁盘)和最少2GB到4GB内存(RAM)的专用计算机。此外,运行一个全节点的比特币软件需要监控、维护和频繁升级。由于缺乏维护或资源导致的任何宕机都会伤害到矿工的利润。对于很多矿工来说,不需要运行一个全节点就能采矿,也是加入托管矿池的一大好处。
矿工使用挖矿协议比如Stratum(STM)或者 GetBlockTemplate(GBT)连接到矿池服务器。一个旧标准GetWork(GWK)自从2012年底已经基本上过时了,因为它不支持在算力超过4GH/S时挖矿。STM和GBT协议都创建包含候选区块头模板的区块模板。矿池服务器通过打包交易、添加创币交易(具有额外的随机数空间)、计算默克尔树根,并链接到父区块散列,来构造一个候选区块。这个候选区块的头部作为模板分发给每个矿工。矿工用这个区块模板以比比特币网络的难度目标更高(更容易)为目标进行挖矿,并发送任何成功的结果给矿池服务器以赚取份额。
10.11.2.2 点对点矿池((P2Pool)
托管矿池存在管理员作弊的可能,管理员可以利用矿池进行双重支付或使区块无效。(参见【10.12 共识攻击】)。此外,中心化的矿池服务器代表着单点故障。如果因为拒绝服务攻击导致服务器宕机或者反应减慢,池中所有矿工就都不能挖矿。在2011年,为了解决由中心化造成的这些问题,提出和实施了一个新的矿池挖矿方法:P2Pool,它是一个点对点的矿池,没有中心管理员。
P2Pool通过将矿池服务器的功能去中心化,实现一个并行的类区块链系统,名叫份额链share chain。一个份额链是一个难度低于比特币区块链的区块链系统。份额链允许池中矿工在一个去中心化的池中合作,以每30秒一个份额区块的速度在份额链上挖矿,获得份额。份额链上的每个区块都记录了贡献工作的矿工的份额,并且继承了上一个份额区块上的份额记录。当其中一个份额区块达到了比特币网络的难度目标时,它将被广播并包含到比特币的区块链上,并奖励所有已经在份额链区块中取得份额的池中矿工。本质上说,比起用一个矿池服务器记录矿工的份额和奖励,份额链使用的是允许所有矿工通过类似比特币区块链系统的去中心化的共识机制跟踪所有份额。
P2P矿池挖矿方式比在中心化矿池中挖矿要复杂的多,因为它要求矿工运行空间、内存、带宽充足的专用计算机来支持一个比特币的全节点和P2P矿池节点软件。P2P矿池矿工连接他们的挖矿硬件到本地P2P矿池节点,节点通过发送区块模板到矿机来模拟矿池服务器的功能。在P2P矿池中,矿工需要独自创建自己的候选区块,打包交易,非常类似于独立矿工,但是他们在份额链上合作采矿。与单独挖矿相比,P2P矿池是一种混合方式,有更精细的支出优势,但是不会像托管矿池那样给管理人太多权力。
即使P2P矿池减少了采矿池运营商的中心化程度,但也很容易受到针对份额链本身的51%攻击。广泛采用P2P矿池并不能解决比特币本身的51%攻击问题。相反,作为多样化挖矿生态系统的一部分,P2P矿池使得比特币整体更加强大。
10.12 共识攻击
至少理论上,比特币的共识机制是容易受到矿工(或矿池)试图使用自己的算力欺骗破坏进行攻击的。就像我们前面讲的,比特币的共识机制依赖于这样一个前提,那就是绝大多数的矿工,出于自己利益最大化的考虑,都会通过诚实地挖矿来维持整个比特币系统。然而,当一个或者一群矿工拥有了整个系统中足够算力之后,他们就可以攻击比特币的共识机制,从而破坏比特币网络的安全性和可靠性。
值得注意的是,共识攻击只能影响整个区块链未来的共识,或者说,最多能影响最近的区块的共识(最多影响过去几十个块)。而且随着时间的推移,整个比特币区块链被篡改的可能性越来越低。理论上,一个区块链分叉可以是任意深度,但实际上,要想实现一个非常深度的区块链分叉需要的算力非常非常大,这使得旧的区块几乎根本无法改变。同时,共识攻击也不会影响用户的私钥以及签名算法(ECDSA)。共识攻击也不能从其他的钱包窃取比特币、没有签名情况下支付比特币、改变比特币支付方向、改变过去的交易或者改变比特币持有纪录。共识攻击只能影响最近的区块,通过拒绝服务来破坏未来区块的生成。
共识攻击的典型场景就是“51%攻击”。想象这么一个场景,一群矿工控制了整个比特币网络大多数(51%)的算力,他们串通起来攻击整个比特币系统。由于这群矿工有生成绝大多数的区块的算力,他们就可以故意制造区块链分叉和“双重支付”,或者针对特定的交易或者特定的钱包地址进行拒绝服务攻击。区块链分叉/双重支付攻击指的是攻击者通过从指定区块之前的区块开始分叉,导致其后的已经确认的区块无效,然后重新收敛这些区块到一个替代的区块链。有了充足算力的保证,一个攻击者可以一次性篡改最近的6个或者更多的区块,从而使得这些区块包含的本应无法篡改的交易(6个确认)无效。值得注意的是,双重支付只能针对攻击者拥有的钱包所发生的交易,因为只有钱包的拥有者才能生成一个合法的签名。如果攻击者可以通过使交易无效获得不可逆的兑换支付或者商品,而且不用付费,这种双重支付攻击就是有利可图的。
让我们看一个“51%攻击”的实际案例。在第1章我们讲到,Alice和Bob之间使用比特币完成了一杯咖啡的交易。咖啡店老板Bob愿意在Alice给自己的转账交易未经确认(区块挖矿)的时候就向其提供咖啡,这是因为与顾客购物的即时性便利性相比,一杯咖啡的双重支付风险很低。这就和大部分的咖啡店对低于25美元的信用卡消费不会向顾客索要签名是一样的,因为和信用卡退款的风险比起来,由于向用户索要信用卡签名导致交易延迟的成本更高。相比之下,使用比特币支付的大额交易被双重支付的风险就高得多了,因为买家(攻击者)可以通过在全网广播一个和真实交易的UTXO一样的伪造交易,以达到取消真实交易的目的。双重支付的发生有两种方式:要么是在交易被确认之前,要么攻击者通过区块链分叉来撤销几个区块。进行51%攻击的人,在新分叉链上双重支付自己的交易,从而撤销在旧链上的交易。
再举个例子:攻击者Mallory在Carol的画廊购买了将中本聪描绘为普罗米修斯的三联组画(名为The Great Fire),Carol出售给Mallory的价格是25万美元的比特币。在等到一个而不是六个或更多的交易确认之后,Carol将这幅组画包好,交给了Mallory。这时,Mallory的一个同伙,一个拥有大量算力的矿池的Paul,在这笔交易写进区块链的时候,开始了51%攻击。首先,Paul指示矿池使用同样的区块高度重新对包含这笔交易的区块进行挖矿,并且在新区块里将原来的交易替换成了双重支付给Mallory相同输入的另外一笔交易。这笔双重支付交易使用了跟原有交易一致的UTXO,但收款人被替换成了Mallory的钱包地址而不是Carol的,实际上就是Mallory继续持有自己的比特币。然后,Paul指示矿池在伪造的区块的基础上,又计算出一个更新的块,这样,包含这笔双重支付交易的区块链比原有的区块链高出了一个区块(导致从包含Mallory交易之后的区块开始分叉)。到此,高度更高的分叉区块链取代了原有的区块链,双重支付交易取代了原来给Carol的交易,Carol既没有收到价值25万美金的比特币,原本拥有的组画也被Mallory拿走了。在整个过程中,Paul矿池里的其他矿工可能自始至终都没有觉察到这笔双重支付交易有什么异样,因为挖矿程序都是自动在运行,并且不会时时监控每一个区块中的每一笔交易。
为了避免这类攻击,售卖大宗商品的商家应该在交易得到全网的6个确认之后再交付商品。或者,商家应该使用托管多重签名签名的账户进行交易,并且也要等到托管账户收到资金并获得全网多个确认之后再交付商品。一条交易的确认数越多,越难被攻击者通过51%攻击篡改。对于大宗商品的交易,即使在付款24小时之后,也就是这笔交易的全网确认数将达到至少144个,再发货,对买卖双方来说使用比特币支付也是方便并且有效率的。
共识攻击中除了“双重支付”攻击,还有一种攻击场景就是拒绝对某个特定参与者(特定比特币地址)提供服务。一个拥有了系统中绝大多数算力的攻击者,可以轻易地忽略某一笔特定的交易。如果这笔交易存在于另一个矿工所产生的区块中,该攻击者可以故意分叉,然后重新产生这个区块,并且把想忽略的交易从这个区块中移除。这种攻击造成的结果就是,只要这名攻击者拥有系统中的绝大多数算力,那么他就可以持续地干预某一个或某一批特定钱包地址产生的所有交易,从而达到拒绝为这些地址服务的目的。
需要注意的是,51%攻击并不是像它的名字说的那样,攻击者需要至少51%的算力才能发起,实际上,即使其拥有不到51%的系统算力,依然可以尝试发起这种攻击。之所以命名为51%攻击,只是因为在攻击者的算力达到51%这个阈值的时候,其发起的攻击尝试几乎肯定会成功。本质上来看,共识攻击,就像是针对下一个区块的拔河比赛,强壮的组最可能赢。随着算力的降低,成功的可能性降低,因为其他矿工以“诚实”的挖矿能力控制着一些区块的产生。从另一个角度讲,一个攻击者拥有的算力越多,其故意创造的分叉区块链就可能越长,可能被篡改的过去最近的区块或者受其控制的未来的区块就会越多。一些安全研究组织利用统计模型得出的结论是,算力达到全网的30%,各种类型的共识攻击都是可能的。
全网算力的急剧增长已经使得比特币系统不再可能被某一个矿工攻击。独立矿工不可能控制总算力的哪怕是很小一部分。但是中心化控制的矿池则带来了矿池操作者出于利益而施行攻击的风险。矿池运营者控制了候选区块的生成,同时也控制哪些交易会被放到新生成的区块中。这样一来,矿池操作者就拥有了剔除特定交易或者双重支付的权力。如果这种权利被矿池操作者以微妙而有节制的方式滥用的话,那么矿池操作者就可以在不为人知的情况下发动共识攻击并获益。
但是,并不是所有的攻击者都是为了利益。一个潜在的场景就是,攻击者仅仅是为了破坏整个比特币系统而发动攻击,而不是为了利益。这种意在破坏比特币系统的攻击者需要巨大的投入和精心的计划,因此可以想象,很有可能来自资金充足、最有可能由国家资助的攻击者发起的。或许,这类资金充足的攻击者或许也会聚敛矿机,勾结矿池运营者,对其他矿池施行拒绝服务等共识攻击。但是,随着比特币网络的算力呈指数级快速增长,上述这些理论上可行的攻击场景,实际操作起来已经越来越困难了。
毫无疑问,一次严重的共识攻击事件势必会降低人们对比特币系统的信心,进而可能导致比特币价格的跳水。然而,比特币系统和相关软件也一直在持续改进,所以比特币社区也势必会对任何一次共识攻击快速做出响应,使整个比特币系统比以往更加稳健和可靠。
10.13 改变共识规则
共识规则决定交易和区块的有效性。这些规则是所有比特币节点之间协作的基础,并负责将整个网络中所有不同角色的本地观点融合为一条一致的区块链。
虽然共识规则在短期内是不变的,并且在所有节点之间必须一致,但长期来看它们并不总是不变的。为了演进和发展比特币系统,规则必须随时改变以适应新功能、改进或修复错误。然而,与传统软件开发不同,升级到共识系统要困难得多,需要所有参与者之间的协调。
10.13.1 硬分叉
在【10.10.1 区块链分叉】,我们研究了比特币网络如何短暂地分叉,网络中的两个部分在短时间内处于区块链的两个不同分支。我们看到这个过程是如何自然发生的,作为网络的正常运行的一部分,以及如何在一个或多个区块被挖掘之后,网络在一个统一的区块链上重新收敛。
另一种情况是,网络也可能会分叉到两条链,这是由于共识规则的变化。这种分叉称为硬分叉hard fork,因为这种分叉后,网络不会重新收敛到统一区块链上。相反,这两条区块链独立发展。当比特币网络的一部分节点按照与网络的其余部分节点不同的共识规则运行时,硬分叉就会发生。这可能是由于错误或者是对共识规则实施的故意修改。
硬分叉可用于改变共识规则,但需要在系统中所有参与者之间进行协调。没有升级到新的共识规则的任何节点都不能参与共识机制,并且在硬分叉的那一刻都被迫进入一条单独的链。因此,硬分叉引入的变化可以被认为不是“前向兼容”,因为未升级的系统不能再处理新的共识规则。
让我们来通过一个特定例子来检查下硬分叉的机制。
下图10-9显示区块链出现两个分叉。在区块高度4处,发生单一区块分叉。这是我们在【10.10.1 区块链分叉】中看到的自发分叉的类型。经过区块5的挖掘,网络在一条链上重新收敛,分叉被解决。
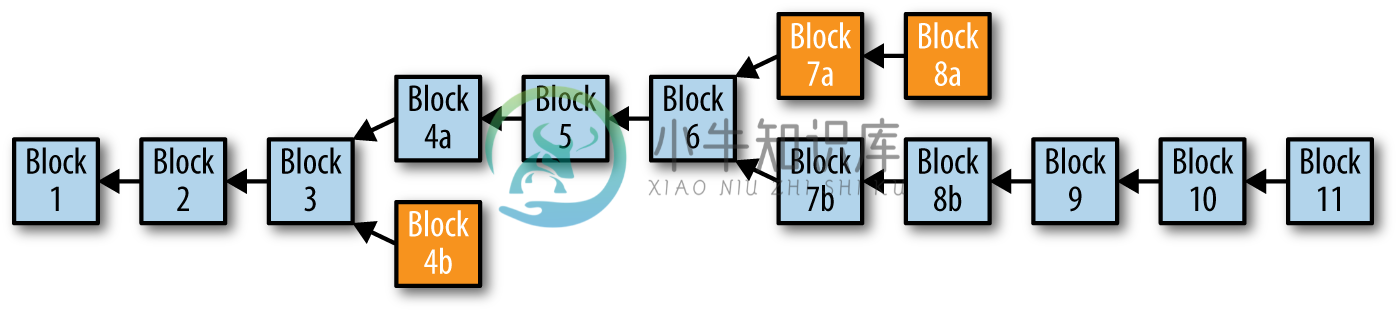
图10-9 分叉的区块链
然而,后来在区块高度6处发生了硬分叉。我们假设原因是由于一个新功能的客户端随着共识规则的改变而发布。从区块高度7开始,运行新的版本的矿工,需要接受新类型的数字签名,我们称之为“Smores”签名,它不是基于ECDSA的签名。紧接着,运行新版本的节点创建了一笔包含Smores签名的交易,一个更新了软件的矿工挖矿出了包含此交易的区块7b。
任何尚未升级验证Smores签名的软件的节点或矿工现在都无法处理区块7b。从他们的角度来看,包含Smores签名的交易和包含该交易的区块7b都是无效的,因为它们是根据旧的共识规则进行评估的。这些节点将拒绝该笔交易和区块,并且不会传播它们。正在使用旧规则的任何矿工都不接受块7b,并且将继续挖掘其父区块6的候选区块。实际上,如果遵守旧规则的矿工连接的所有节点都是遵守旧的规则,那么他们甚至可能接收不到区块7b,因此也不会传播这个区块。最终,他们将挖出区块7a,这个在旧规则是有效的,其中不包含使用Smores签名的任何交易。
这两个链条从这一点继续分裂。 ”b”链的矿工将继续接受并开采含有Smores签名的交易,而“a”链上的矿工将继续忽视这些交易。即使区块8b不包含任何Smores签名的交易,“a”链上的矿工也无法处理。对他们来说,它似乎是一个孤立的区块,因为它的父区块“7b”不被识别为一个有效的区块。
10.13.2 硬分叉:软件,网络,挖矿和链
对于软件开发人员来说,术语“分叉”具有另一个含义,对“硬分叉”一词增加了混淆。在开源软件中,当一组开发人员选择遵循不同的软件路线图并启动开源项目的竞争实现时,会发生分叉。我们已经讨论了导致硬分叉的两种情况:共识规则中的错误,以及对共识规则的故意修改。在故意改变共识规则的情况下,软件叉要比硬分叉先发生。但是,对于这种类型的硬分叉,新的共识规则必须通过开发,采用和启动新的软件实现。
试图改变共识规则的软分叉的例子包括Bitcoin XT,Bitcoin Classic和最近的Bitcoin Unlimited。但是,这些软分叉都没有产生硬分叉。虽然软分叉是一个必要的前提条件,但它本身不足以发生硬分叉。为了实现硬分叉,矿工、钱包和中间节点必须采用竞争实现并激活新规则。相反,有许多Bitcoin Core的替代实现方案,甚至还有软分叉,这些没有改变共识规则,只是去除错误,也可以在网络上共存并交互操作,最终并未导致硬分叉。
共识规则会在交易或区块的验证中表现出明确清晰的不同之处。比如共识规则适用于比特币脚本或数字签名的加密原语时,这种差别可能以微妙的方式表现。最后,由于系统限制或实现细节所产生的隐含共识约束,共识规则还可能以意外的方式有所不同。比如后者的例子是在将Bitcoin Core 0.7升级到0.8中过程中,出现意外的硬分叉,这是由于用于存储区块的Berkley DB实现的限制引起的。
从概念上讲,我们可以将硬分叉看成四个阶段:软分叉,网络分叉,挖矿分叉和区块链分叉。
当开发人员使用修改后的共识规则创建客户端的替代实现时,该流程就开始了。
当这个分叉实现的客户端部署在网络中时,一定比例的矿工,钱包用户和中间节点可以采用并运行该版本客户端。产生的分叉将取决于新的共识规则是否适用于区块,交易或系统其他方面。如果新的共识规则与交易有关,那么根据新规则创建交易的钱包可能会导致网络分叉,随后在交易被挖掘到区块中时发生硬分叉。如果新规则与区块有关,那么当一个区块根据新规则被挖掘时,硬分叉流程开始。
首先,是网络分叉。基于旧的共识规则的节点将拒绝根据新规则创建的任何交易和区块。此外,遵循旧的共识规则的节点将暂时禁止和断开与发送这些无效交易和区块的任何节点的连接。因此,网络将分为两部分:旧节点只连接到旧节点,新节点只连接到新节点。基于新规则的单个交易或区块将通过网络发生连锁反应,导致网络被分裂成了两个。
一旦使用新规则的矿工开采了一个块,挖矿算力和区块链也将分叉。新的矿工将在新区块之上挖掘,而老矿工将根据旧的规则挖掘一个单独的链。分裂的网络使得按照各自共识规则运行的矿工不会接收彼此的块,因为它们连接到两个独立的网络。
10.13.3 分离矿工和难度
随着分裂的矿工们开始开采两条不同的链,链上的算力也被分裂。两个链之间的挖矿算力可以按任意比例分配。新的规则可能只有少数矿工跟随,也可能是绝大多数矿工遵循新规则。
我们假设,例如是80%和20%比例的分配,大多数挖矿算力使用新的共识规则。我们还假设分叉在重新设定难度目标阶段后立即出现。
这两条链将各自继承重定难度目标阶段之后的难度。新的共识规则得到了以前可用的挖矿算力中80%的承诺。从这个链的角度来看,与上一阶段相比,挖矿算力突然下降了20%。平均每12.5分钟就会发现一个区块,这意味着可以扩展这条链的挖矿算力下降了20%。这个区块发行速度将持续下去(除非有任何改变算力的因素出现),直到挖到第2016个区块,这将需要大约25,200分钟(每个区块需要12.5分钟)或17.5天。17.5天后,重定难度目标将再次发生,基于此链中算力的减少量将难度调整(减少20%)到每10分钟产生一个区块。
少数人认可的那条链,根据旧规则继续挖矿,现在只有20%的算力,将面临更加艰巨的任务。在这条链上,平均每隔50分钟挖出一个区块。这个难度将不会在2016个区块之前进行调整,这将需要100,800分钟,或大约10周的时间。假设每个区块具有固定容量,这也将导致交易容量减少5倍,因为每小时可用于记录交易的区块大幅减少了。
10.13.4 有争议的硬分叉
这是共识软件开发的黎明。正如开源开发改变了软件的方法和产品,创造了新的方法论,新工具和新社区,共识软件开发也代表了计算机科学的新前沿。在比特币发展路线图的争论、实验和磨难中,我们将看到新的开发工具、实践、方法论和社区的出现。
硬分叉被视为有风险,因为它们迫使少数人被迫选择升级或是必须保留在少数派链条上。将整个系统分为两个竞争系统被许多人认为是不可接受的风险。结果,许多开发人员不愿使用硬分叉机制来实现对共识规则的升级,除非整个网络都能达成一致。任何没有被所有人支持的硬分叉建议都被认为是“有争议”的,都是不可能不危及系统分裂的尝试。
硬分叉的问题在比特币开发社区也是非常有争议的,尤其是与控制区块大小限制的共识规则的任何相关提议。一些开发人员反对任何形式的硬分叉,认为它太冒险了。另一些人认为硬分叉机制是提升共识规则的重要工具,避免了“技术债务”,并与过去进行了一个干净的了断。最后,还有些开发人员认为硬分叉应该作为一种很少使用的机制,只有经过认真的计划,并且在近乎一致的共识下才建议使用。
我们已经看到出现了新的方法论来解决硬分叉的危险。在下一节中,我们将看一下软分叉,以及BIP-34和BIP-9,用于发送信号和激活共识修改。
10.13.5 软分叉
并非所有共识规则的变化都会导致硬分叉。只有前向不兼容的共识规则的变化才会导致分叉。如果共识规则的改变也能够让未修改的客户端仍然按照先前的规则对待交易或者区块,那么就可以在不进行分叉的情况下实现共识修改。
这就是术语软分叉soft fork,区别于之前的硬分叉升级方法。实际上软分叉不是分叉。软分叉是对共识规则的前向兼容的改变,允许未升级的客户端程序继续在新的共识规则下工作。
软分叉的一个不是很明显的方面就是,软分叉只能用于增加共识规则约束,而不能扩展它们。为了向前兼容,根据新规则创建的交易和区块也必须在旧规则下有效,但是反之不然。新规则只能增加约束条件,否则如果放宽了约束条件,那么新规则所产生的区块(或者交易)在旧规则下被拒绝时,还是会触发硬分叉。
软分叉可以通过多种方式实现,所谓软分叉并不特指某种单一的方法,而是很多种方法,它们都有一个共同点:不要求所有节点升级,也不强制非升级节点脱离共识。
10.13.5.1 软分叉重新定义NOP操作码
基于对NOP操作码的重新解释,比特币已经实现了许多软分叉。比特币脚本有10个操作码保留供将来使用,NOP1到NOP10。根据共识规则,这些操作码在脚本中的存在被解释为无效的运算符,这意味着它们不会产生任何影响。在NOP操作码之后继续执行,就好像它不存在一样。
因此,软分叉可以修改NOP代码的语义给它新的含义。例如,BIP-65(CHECKLOCKTIMEVERIFY)重新解释了NOP2操作码。实施BIP-65的客户端将NOP2解释为OP_CHECKLOCKTIMEVERIFY,针对在锁定脚本中包含该操作码的UTXO,添加绝对锁的共识规则。这种变化是一个软分叉,因为在BIP-65下有效的交易在任何没有实现(不识别)BIP-65的客户端上也是有效的。对于旧的客户端,该脚本包含一个NOP代码,这被忽略。
10.13.5.2 其他方式软分叉升级
NOP操作码的重新解释既是共识升级的规划,同时也是一种明显的升级机制。然而,最近,引入了另一种软分叉机制,其不依赖于NOP操作码来进行特定类型的共识更改。这在【7.8 隔离见证】中有更详细的说明。隔离见证是一个交易结构的体系架构变化,它将解锁脚本(见证)从交易内部移动到外部数据结构(将其隔离)。隔离见证最初被设想为硬分叉升级,因为它修改了一个基本的结构(交易)。在2015年11月,一位致力于Bitcoin Core的开发人员提出了一种机制,通过这种机制,可以将隔离见证作为软分叉引入。此机制是在隔离见证规则下对于UTXO的锁定脚本的修正,使得未升级的客户端将锁定脚本视为可用任何解锁脚本进行兑换。因此,可以不需要每个节点必须升级或从链中脱离就可以引入隔离见证:这就是软分叉。
有可能还有其他尚未被发现的机制,通过这种机制可以用前向兼容的方式作为软分叉进行升级。
10.13.6 对软分叉的批评
基于NOP操作码的软分叉是相对无争议的。NOP操作码被放置在比特币脚本中,明确的目的就是允许无中断升级。
然而,许多开发人员担心软分叉升级的其他方法会产生不可接受的妥协。对软分叉的常见批评包括:
技术性债务
由于软分叉在技术上比硬分叉升级更复杂,所以引入了技术性债务,这是指由于过去的设计权衡而增加未来代码维护的成本。代码复杂性又增加了错误和安全漏洞的可能性。
验证放松
未经修改的客户端将交易视为有效,而无需评估已修改的共识规则。实际上,未经修改的客户端不会使用所有共识规则来验证,因为它们对新规则视而不见。这适用于基于NOP的升级,以及其他软分叉升级。
不可逆转升级
因为软分叉产生额外的共识约束的交易,所以它们在实践中成为不可逆转的升级。如果软分叉升级在激活后被回退,那么任何根据新规则创建的交易都可能导致在旧规则下的资金损失。例如,如果根据旧规则对CLTV交易进行评估,则不存在任何时间锁定约束,并且可以随时花费。因此,批评人士认为,由于错误而不得不回退的失败的软分叉几乎肯定会导致资金的损失。
10.14 使用区块版本发出软分叉信令
由于软分叉允许未经修改的客户在共识内继续工作,“激活”软分叉是通过矿工发出的准备就绪信号:大多数矿工必须同意,准备并愿意执行新的共识规则。为了协调他们的行动,有一个信令机制,使他们能够表达对共识规则改变的支持。该机制是在2013年3月激活BIP-34后引入的,并在2016年7月被BIP-9激活取代。
10.14.1 BIP-34信令和激活
在BIP-34中,第一次实现使用区块版本字段来允许矿工通过信令表示特定的共识规则改变。在BIP-34之前,将区块版本设定为”1”是由于惯例,而不是来自于执行共识。
BIP-34定义了一个共识规则变更,要求在创币交易的coinbase字段(相当于普通交易的输入字段)中包含区块高度。在BIP-34之前,矿工可以在coinbase中填充任意数据。在BIP-34激活之后,有效区块必须在coinbase的开头包含特定的区块高度,并且使用大于或等于“2“的版本号进行标识。
为了通知BIP-34的更改和激活,矿工们将区块版本设置为“2”而不是“1”。这没有立即使版本“1”区块无效。一旦激活,版本“1”的区块将变得无效,并且所有版本“2”的区块需要在coinbase中包含区块高度才能有效。
BIP-34基于1000个区块的滚动窗口定义了两步激活机制。矿工将以“2”作为版本号来构建区块,从而表示他或她已经准备好使用BIP-34。严格来说,由于共识规则尚未被激活,这些区块还无须遵守新的共识规则,也就是不必将区块高度包括在创币交易中。共识规则分为两个步骤激活:
如果75%(最近1000个区块中的750个)标有版本“2”,则版本“2”的区块的创币交易中必须包含区块高度,否则这些区块被会拒绝导致无效。版本“1”的区块仍然被网络接受,不需要包含块高度。这个时期新旧共识规则共存。
当95%(最近1000区块中的950)是版本“2”时,版本“1”的区块不再被视为有效。版本“2”的区块只有当它们在coinbase字段中包含区块高度(根据先前阈值)时才有效。此后,所有区块必须符合新的共识规则,所有有效区块必须在创币交易中包含区块高度。
在成功发出信令并激活BIP-34规则后,该机制又被使用过两次以激活软分叉:
通过BIP-34类型的信令以及区块版本“3”,BIP-66严格DER编码签名被激活,版本“2”的区块无效。
通过BIP-34类型的信令以及区块版本“4”,BIP-65 CHECKLOCKTIMEVERIFY被激活,版本“3”的区块无效。
BIP-65激活后,BIP-34的信令和激活机制退出,并被下面描述的BIP-9信令机制代替。这个标准在BIP-34(Block v2, Height in Coinbase)中定义。
10.14.2 BIP-9信令和激活
BIP-34,BIP-66和BIP-65使用的机制成功地激活了三个软分叉。然而,它被替换是因为它有几个限制:
由于区块版本使用的是整数值,一次只能激活一个软分叉,因此需要在软分叉提议之间进行协调,并就其优先级和排序达成一致。
此外,由于区块版本增加,所以机制并没有提供一种直接的方式来拒绝变更,然后提出一个不同的建议。如果老客户端仍然在运行,他们可能会错误地把新的变更的支持信号,当成旧的变更的拒绝信号。
每个新的更改不可逆转地减少了将来可用于变更的区块版本号。
提出BIP-9用来克服这些困难,提升未来实施变更的速度和便利。
BIP-9将区块版本解释为位字段而不是整数。因为区块版本最初作为整数:版本1到4,因此只有29位可用作为位字段。这样就有了29位,可用于独立和同时发出29个不同提案的准备就绪信号。
BIP-9还设置了发信令和激活的最大时间。这样矿工们不需要永远发出信号。如果一个提案在TIMEOUT期限内(这个值在提案中定义)未激活,则该提案视为被拒绝。该提案可以使用不同位的信令重新提交,更新激活周期。
此外,在TIMEOUT已经过去并且特征被激活或被拒绝之后,信令位可以被再次用于另一个特征而不会混淆。因此,多达29次更改信号可以并行发出,而且超时后可将这些位“再循环”以提出新的更改。
注意 虽然只要投票周期不重叠,信令位可以重复使用或循环使用,但是BIP-9的作者还是建议仅在必要时重复使用位,主要是由于旧软件中的错误,可能会发生意想不到的行为。总之,在全部29位都被使用过一次前,我们不期望看到重复使用。
用于提案变更的数据结构包含以下字段:
名称(name)
用于区分提案的简短描述。通常,BIP将该提案描述为“bipN”,其中N是BIP编号。
位(bit)
0到28,在区块版本中矿工使用这个位用于表示对提案的批准。
开始时间(starttime)
信令开始的时间(基于Median Time Past或MTP),之后该位的值被解释为提案的准备就绪信令。
结束时间(endtime)
该时间(基于MTP),如果尚未达到激活阈值,则认为该更改被拒绝。
与BIP-34不同,BIP-9在2016个区块的难度目标调整周期内,计算激活信号的数量。在每个难度调整周期内,如果针对某个提案的信令区块总数超过95%(2016中的1916),则该提案将在下一个难度调整周期内激活。
BIP-9提供了一个提案状态图,以说明一个提案的各个阶段和转换,如图10-10所示。
一旦参数在比特币软件中已知(定义),提案就以定义(DEFINED)状态开始。对于MTP时间在开始时间之后的区块,提案状态转换为开始(STARTED)。如果在难度调整周期内,投票数超过了阈值,并且尚未超时,则提案状态转换为锁定(LOCKED_IN)。一个难度调整周期后,提案变为激活(ACTIVE)。一旦达到该状态,提案会永久保持激活状态。如果投票还没有达到阈值前,超时时间已到,那么提案状态更改为失败(FAILED),这表示提案被拒绝了。一个失败(FAILED)的提案会永久保持在这个状态。
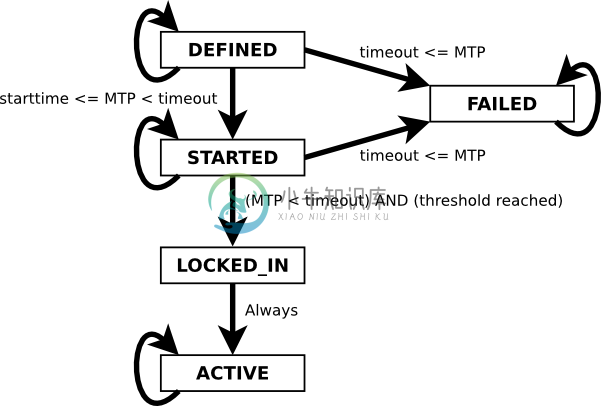
图10-10 BIP-9状态转换图
BIP-9首次实施用于激活CHECKSEQUENCEVERIFY和相关的BIP(68,112,113)。名为“csv”的提案在2016年7月成功激活。
该标准在BIP-9(带有超时和延时的版本位)中定义。
10.15 共识软件发展
共识软件不断发展,对于改变共识规则的各种机制进行了很多讨论。就其本质而言,比特币在协调和共识变化方面树立了非常高的标杆。作为一个去中心化的系统,不存在凌驾于网络参与者之上的“权威”。权力分散在多个支持者,如矿工,核心开发者,钱包开发者,交易所,商家和最终用户之间。这些支持者不能单方面做出决定。例如,尽管矿工在理论上可以使用过半数(51%)来改变规则,但受到其他支持者准许的限制。如果他们单方面行事,其他参与者可能会拒绝遵从,使其经济活动保持在少数链上。如果没有经济活动(交易,商人,钱包,交易所),矿工们只能用空的区块开采一个毫无价值的货币。这种权力的分散意味着所有参与者必须协作,否则任何改变都不能实现。现状就是这个系统是稳定的,如果大多数人有强烈的共识,才可能会有一些变化。软分叉中的95%阈值就反映了这一现实。
重要的是要认识到,对于共识发展没有完美的解决办法。硬分叉和软分叉都涉及权衡。对于某些类型的更改,软分叉可能是一个更好的选择;对于另外一些情况,硬分叉又可能更好。没有完美的选择,都带有风险。共识软件发展的一个不变特征是变革是困难的,共识促成了妥协。有些人认为这是共识制度的弱点。
一些人认为这是共识体系的弱点。随着时间的推移,你可能会像我一样,把它视为系统的最强大的优势。