
4.3.1 部署实践
本文介绍了小米公司部署Open-Falcon的一些实践经验,同时试图以量化的方式分析Open-Falcon各组件的特性。
概述
Open-Falcon组件,包括基础组件、作图链路、报警链路。小米公司部署Open-Falcon的架构,如下: 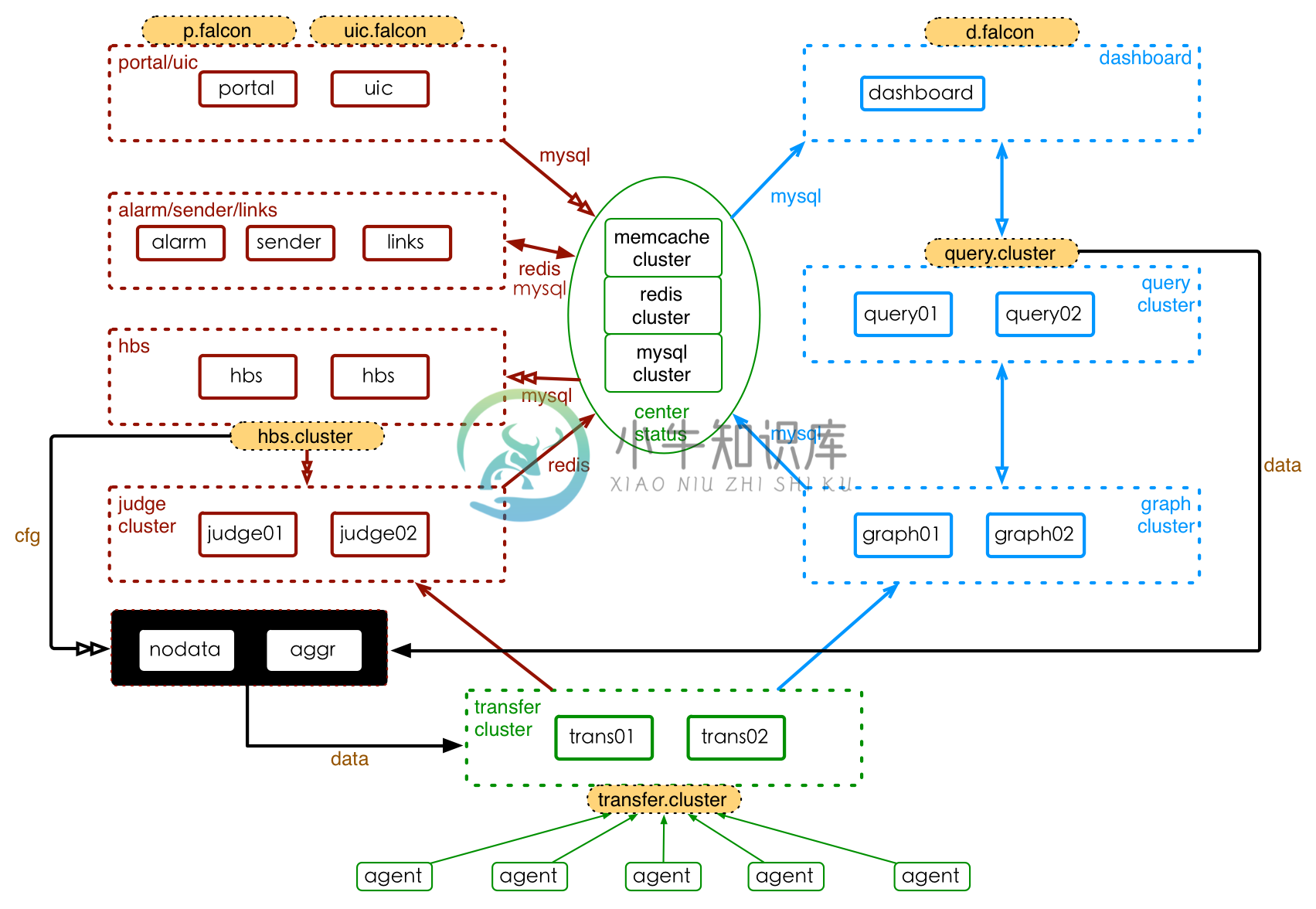
其中,基础组件以绿色标注圈住、作图链路以蓝色圈住、报警链路以红色圈住,橙色填充的组件为域名。每个模块(子服务)都有自己的特性,根据其特性来制定部署策略。接下来,我们首先以白话的方式、定性描述Open-Falcon的部署演进,然后试图量化地分析每个组件的特点并给出一些部署建议。
部署演进
Open-Falon的部署情况,会随着机器量(监控对象)的增加而逐渐演进,描述如下,
初始阶段,机器量很小(<100量级)。几乎无高可用的考虑,所有子服务可以混合部署在1台服务器上。此时,1台中高配的服务器就能满足性能要求。
机器量增加,到500量级。graph可能是第一个扛不住的,拿出来单独部署;接着judge也扛不住了,拿出来单独部署;transfer居然扛不住了,拿出来吧。这是系统的三个大件,把它们拆出来后devops可以安心一段时间了。
机器数量再增加,到1K量级。graph、judge、transfer单实例扛不住了,于是开始考虑增加到2+个实例、并考虑混合部署。开始有明确的高可用要求?除了alarm,都能搞成2+个实例的高可用结构。再往后,机器继续不停的增加,性能问题频现。好吧,见招拆招,Open-Falcon支持水平扩展、表示毫无压力。
机器量达到了10K量级,这正是我们现在的情况。系统已经有3000+万个采集项。transfer部署了20个实例,graph部署了20个实例,judge扩到了60个实例(三大件混合部署在20台高配服务器上,judge单机多实例)。query有5个实例、平时很闲;hbs也有5个实例、很闲的样子;dashborad、portal、uic都有2个实例;alarm、sender、links仍然是bug般的单实例部署(这几个子服务部署在10左右台低配服务器上,资源消耗很小)。graph的db已经和portal、uic的db实例分开了,因为graph的索引已经达到了5000万量级、混用会危及到其他子系统。redis仍然是共享、单实例。这是我们的使用方式,有不合理的地方、正在持续改进。
机器上100K量级了。不好意思、木有经历过。目测graph索引、hbs将成为系统较为头疼的地方,Open-Falcon的系统运维可能需要1个劳动力来完成。
基础组件
agent
agent应该随装机过程部署到每个机器实例上。agent从hbs拉取配置信息,进行数据采集、收集,将数据上报给transfer。agent资源消耗很少、运行稳定可靠。小米公司部署了10K+个agent实例,已稳定运行了1Y+。
transfer
transfer是一个无状态的集群。transfer接收agent上报的数据,然后使用一致性哈希进行数据分片、并把分片后的数据转发给graph、judge集群(transfer还会打一份数据到opentsdb)。
transfer集群会有缩扩容的情况,也会有服务器迁移的情况,导致集群实例不固定。如某个transfer实例故障后,要将其从transfer集群中踢出。为了屏蔽这种变化对agent的影响,建议在transfer集群前挂一个域名,agent通过域名方式访问transfer集群、实现自动切换。多IDC时,为了减少跨机房流量,建议每个IDC都部署一定数量的transfer实例、agent将数据push到本IDC的transfer(可以配置dns规则,优先将transfer域名解析为本地IDC内的transfer实例)。
transfer消耗的资源 主要是网络和CPU。使用机型/操作系统选择为Dell-R620/Centos6.3,对transfer进行性能测试。Dell-R620配置为24核心、1000Gb双工网卡。测试的结果为:
| 进入数据吞吐率 | 流出数据吞吐率 | 进入流量 | 流出流量 | CPU消耗(均值) |
|---|---|---|---|---|
| 50K条/s | 100K条/s | 180Mb/s | 370Mb/s | 300% |
| 100K条/s | 200K条/s | 360Mb/s | 740Mb/s | 620% |
性能测试是在理想条件下进行的,且远远未达到服务器的资源极限。当出现流量峰值、数据接收端处理缓慢时,transfer的内存会积压一些待发送的数据、使MEM消耗出现增加(可以调整发送缓存上限,来限制最大内存消耗)。考虑到流量不均、流量峰值、集群高可用等问题,评估transfer集群容量时要做至少1倍的冗余。这里给一个建议,10K/s的进入数据吞吐率、20K/s的流出数据吞吐率,网卡配置不小于100Mb、CPU不小于100%。
opentsdb
该功能已经完成。欢迎进群一起交流tsdb相关的使用经验。
center-status
center-status是中心存储的统称。Open-Falcon用到的中心存储,包括Mysql、Redis(Memcached要被弃用)。Mysql主要用于存储配置信息(如HostGroup、报警策略、UIC信息、Screen信息等)、索引数据等,Redis主要被用作报警缓存队列。索引生成、查询比较频繁和耗资源,当监控数据上报量超过100K条/min时 建议为其单独部署Mysql实例、并配置SSD硬盘。一个有意义的数据是: graph索引库,开启bin日志,保存4000万个counter且连续运行60天,消耗了20GB的磁盘空间。
当前,我们的Mysql和Redis都是单实例部署的、存在高可用的问题。Mysql还没有做读写分离、分库分表等。
作图链路
graph
graph组件用于存储、归档作图数据,可以集群部署。每个graph实例会处理一个分片的数据: 接收transfer发送来的分片数据,归档、存储、生成索引;接受query对该数据分片的查询请求。
graph会持久存储监控数据,频繁写入磁盘,状态数据会缓存在内存,因此graph消耗的主要资源是磁盘存储、磁盘IO和内存资源。用"机型/系统/磁盘"为"Dell-R620/Centos6.3/SSD 2TB"的环境 对graph进行性能测试,结果为:
| 采集项数目 | 存储时长 | DISK | 进入数据 吞吐率 | DISK.WIRTE REQUEST | DISK.IO UTIL | MEM |
|---|---|---|---|---|---|---|
| 900K | 5Y | 91GB | 4.42K/s | 1.6K/s | 3.0% | 5.2GB |
| 1800K | 5Y | 183GB | 8.78K/s | 3.2K/s | 7.9% | 10.0GB |
上述测试远远没有达到服务器的资源极限。根据测试结果,建议部署graph的服务器,配置大容量SSD硬盘、大容量内存。一个参考值是: 存储10K个采集项、数据吞吐率100条/s时,配置SSD磁盘不小于1GB、MEM 不小于100M;一个采集项存5年,消耗100KB的磁盘空间。
query
数据分片存储在graph上,用户查询起来比较麻烦。query负责提供一个统一的查询入口、屏蔽数据分片的细节。query的使用场景主要有:(1)dashboard图表展示 (2)使用监控数据做二次开发。
为了方便用户访问,建议将query集群挂载到一个域名下。考虑到高可用,query至少部署两个实例(当前,两个实例部署的IDC、机架等需要负责高可用的规范)。具体的性能统计,待续。小米公司的部署实践为: 公司开发和运维人员均使用Open-Falcon的情况下,部署5个query实例(这个其实非常冗余,2个实例足够)。
dashboard
dashboard用户监控数据的图表展示,是一个web应用。对于监控系统来说,读数据 或者 看图的需求相对较少,需要的query较少、需要的dashboard更少。建议以web应用的方式 部署2+个实例。小米公司的部署实践为: 公司开发和运维人员均使用dashboard的情况下,部署2个dashboard实例。
报警链路
judge
judge用于实现报警策略的触发逻辑。judge可以集群部署,每个实例上处理固定分片的采集项数据(transfer给哪些,就处理哪些)。judge实现触发计算时,会在本地缓存 触发逻辑的中间状态和定量的监控历史数据,因此会消耗较多的内存资源和计算资源。下面给出一组统计数据,
| 采集项数目 | 报警策略数 | MEM消耗 | CPU消耗(均值) |
|---|---|---|---|
| 550K | xxx | 10GB | 100% |
| 1100K | xxx | 20GB | 200% |
上述统计值来自线上judge的运行数据。根据上述统计,MEM消耗、CPU消耗(均值) 随着 处理的采集项数目 基本呈线性增长。关于MEM消耗的一个参考值是,10K个采集项占用200MB的内存资源、50%个CPU资源。建议部署judge时,单实例处理的采集项数目不大于1000K。
hbs
hbs是Open-Falcon的配置中心,负责 适配系统的配置信息、管理agent信息等。hbs单实例部署,每个实例都有完整的配置信息。可以考虑,部署2+个实例、挂在hbs域名下,实现高可用的同时又方便用户使用。
hbs消耗的资源较少,这里给出小米公司部署hbs的参考值: 10K个agent实例、3000万个采集项、150K/s的监控数据吞吐率时,部署5个hbs实例,每个hbs实例的资源消耗为{MEM:1.0GB, CPU:<100%, NET、DISK消耗忽略不计}; 这5个hbs需要处理的配置数据,量级如下
| host数量 | hostGroup数量 | hostGroup策略数量 | express策略数量 |
|---|---|---|---|
| 10K | 1.2K | 1.1K | 300 |
portal
portal提供监控策略管理相关的UI,使用频率较低、系统负载很小。建议以web应用的方式 部署2+个实例。小米公司的部署实践为: 公司开发和运维人员均使用portal的情况下,部署2个portal实例。
uic
uic是用户信息管理中心,提供用户管理的UI,使用频率较低、系统负载较小。建议以web应用的方式 部署2+个实例。小米公司的部署实践为: 360个用户、120个用户分组,部署2个uic实例。
alarm(sender)
alarm负责整理报警信息,使变成适合发送的形式。alarm做了一些报警合并相关的工作,当前只能单实例部署(待优化);报警信息的数量很少,alarm服务的压力非常小、单实例完全满足资源要求;考虑到高可用,当前只能做一个冷备。sender负责将报警内容发送给最终用户。sender本身无状态,可以部署多个实例。考虑到报警信息很少,2个sender实例 能满足性能及高可用的要求。
links
links负责报警合并后的详情展示工作。links支持多实例部署、分片处理报警合并相关的工作。该服务压力很小,资源消耗很少;可以部署2个实例。
混合部署
混合部署可以提高资源使用率。这里先总结下Open-Falcon各子服务的资源消耗特点,
| 子服务 | MEM消耗 | CPU消耗 | DISK消耗 | NET消耗 | 关键资源 |
|---|---|---|---|---|---|
| agent | 低 | 低 | 低 | 低 | |
| transfer | 低 | 低 | 可忽略 | 高 | NET |
| graph | 中 | 中 | 高 | 中 | DISK |
| query | 低 | 低 | 可忽略 | 中 | |
| dashboard | 低 | 低 | 可忽略 | 低 | |
| judge | 高 | 中 | 可忽略 | 低 | MEM |
| hbs | 中 | 中 | 可忽略 | 低 | |
| portal | 低 | 低 | 可忽略 | 低 | |
| uic | 低 | 低 | 可忽略 | 低 | |
| alarm | 低 | 低 | 可忽略 | 低 | |
| sender | 低 | 低 | 可忽略 | 低 | |
| links | 低 | 低 | 可忽略 | 低 |
根据资源消耗特点、高可用要求等,可以尝试做一些混合部署。比如,
- transfer&graph&judge是Open-Falcon的三大件,承受的压力最大、资源消耗最大、但彼此间又不冲突,可以考虑在高配服务器上混合部署这三个子服务
- alarm&sender&links资源消耗较少、但稳定性要求高,可以选择低配稳定机型、单独部署
- hbs资源消耗稳定、不易受外部影响,可以选择低配主机、单独部署
- dashboard、portal、uic等是web应用,资源消耗都比较小、但易受用户行为影响,可以选择低配主机、混合部署、并留足余量
- query受用户行为影响较大、资源消耗波动较大,建议选择低配主机、单独部署、留足余量
踩过的坑
- 为了提高服务器的资源利用率,单机部署了同一子服务的多个实例。这种情况会加大系统运维的难度、可能占用较多的人力资源。可以考虑使用低配服务器,来解决单机资源使用率低的问题。