
1.4.4 Mesos 全方位烹饪指南
如今与Mesos相关的文章可谓层出不穷,不过展示能够直接用于生产的完整基础设施的资料却相当少见。在今天的文章中,我将介绍各组件的配置与使用方式,旨在帮助大家利用Mesos构建起持续交付且拥有容错能力的运行时平台。不过设备配置脚本属于基础设施当中的主体部分,因此在文章中无法完全公布——但值得大家了解的内容已经全部到位。
概述
我们不会具体探讨设备的实际安装与配置,不过大家可以通过下图了解我们已经安装的软件:
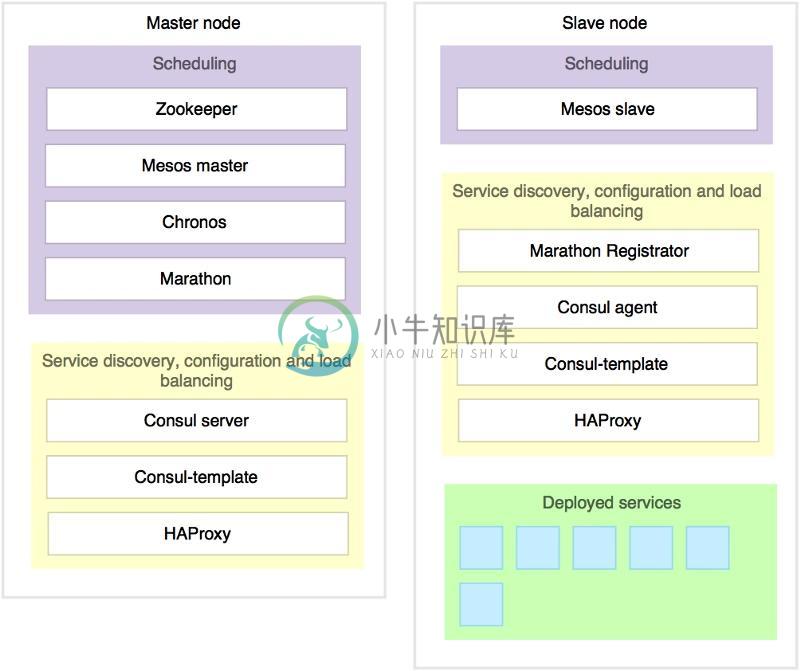
目前,我们运行有3台主节点与3台从节点,并利用Saltstack进行配置。
下面让我们从宏观角度审视代码构建与配置及执行的完整部署流程。
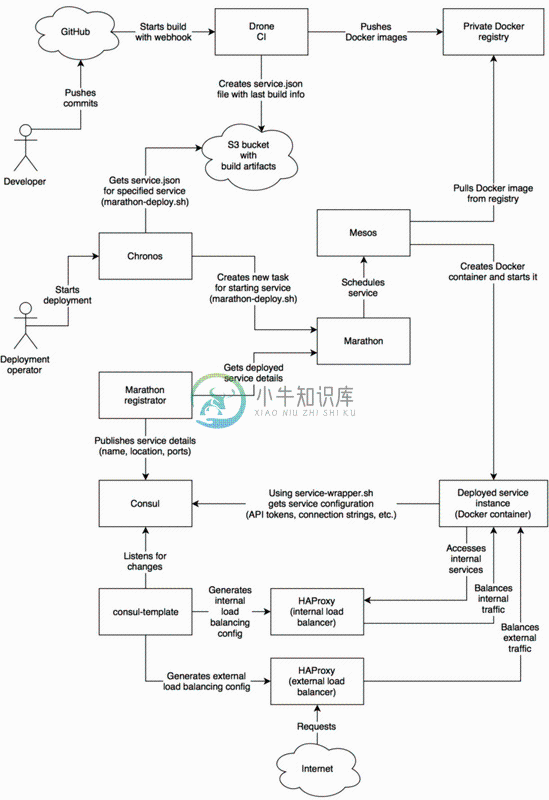
在以下章节中,我们将探讨各组件是如何交互及运作的。
准备Docker镜像
虽然Mesos能够利用自身默认容器完美处理各类可执行文件,但我们仍然推荐运行Docker化应用。我们需要向每套Docker镜像中添加一点内容,从而保证其能够轻松同这套运行时平台相集成。
首先,我们需要了解Docker宿主主机的实际IP地址。虽然人们一直要求支持特殊的Docker标记,可以很容易的通过定制化脚本轻松实现:
#!/bin/sh
set -e
DOCKERHOST=$(ip route show 0.0.0.0/0 | grep -Eo 'via \S+' | awk '{ print $2 }')
echo "$DOCKERHOST dockerhost" >> /etc/hosts
exec "$@"
现在容器化中的应用程序已经能够可靠地引用“dockerhost”主机名称,在必要时接入该Docker宿主主机。
接下来是服务配置管理(我们将在后文中详尽讨论),我们需要向Docker镜像中添加一套名为service-wrapper的脚本。另外,我们还需要安装其关联性元素——jq。如果大家使用精简化Linux镜像(例如Alpine),请确保其中包含curl命令工具。这一切汇总起来,我们就拥有了以下面向Node.js应用程序的Docker镜像:
FROM node:4
RUN apt-get update && apt-get install -y jq && \
rm -rf /var/lib/apt/lists/*
ADD service-wrapper.sh /usr/bin/
ADD entrypoint.sh /usr/bin/
此镜像应被推送至Docker 仓库并由CI服务器进行访问。在我们的示例中,将是可用的私有Docker仓库在registry.local这台宿主主机上。
构建与部署
我们利用Drone实现持续集成,其使用方式非常简单但却能够在Docker容器当中很好地执行构建任务。另外,其全部插件也都是普通的Docker容器,其能够获取build信息载荷并能够以独特的插件方式加以处理。而且没错,甚至是克隆代码库也能够通过单独的Docker容器实现。
由于我们使用的技术相当多元化,因此需要利用Drone简化很多我们的服务器构件设置——我们只需要为每种不同技术堆栈准备单独的Docker镜像,并要求其利用此镜像进行构建。举例来说,这些镜像分别用于运行Node.js、Java以及Mono的构建。当然,它们同样由Drone负责构建。
为了便于理解,我创建一款名为test-server的Node.js Web应用,其只负责显示各项环境变量——大家可以 点击此处 在GitHub上查看源代码。我们在后文中还将多次提到这款示例应用,了解如何利用test-server创建一套Docker镜像并将其部署至Marathon。需要强调的是,该服务应当尽可能遵循十二因素应用原则,从而更好地与这套运行时平台相集成。
在进行构建之前,需要注意的是,我们会利用Marathon调度自己的长期运行服务。它正是整套运行时平台的基石,其负责控制服务可用性并用于实现服务发现。其拥有非常直观的“可curl”API,我们可以利用它实现自动部署。为了利用Marathon部署服务,大家需要调用其API并发送JSON文件以进行服务描述,具体如下所示:
{
"id": "/app/production/test-server",
"labels": {
"version": "master-ef5a154e25b268c611006d08a78a3ec0a451e7ed-56",
"environment": "production"
},
"env": {
"SERVICE_TAGS": "production,internal-listen-http-3000",
"SERVICE_NAME": "test-server"
},
"cpus": 0.05,
"mem": 64.0,
"instances": 4,
"args": [
"service-wrapper.sh", "dockerhost:18080", "dockerhost:18500", "app/production/test-server",
"node", "/app/server.js"
],
"container": {
"type": "DOCKER",
"docker": {
"image": "registry.local/test-server:master-ef5a154e25b268c611006d08a78a3ec0a451e7ed-56",
"forcePullImage": true,
"network": "BRIDGE",
"portMappings": [{
"containerPort": 3000
}]
}
},
"healthChecks": [{
"protocol": "HTTP",
"path": "/healthcheck",
"gracePeriodSeconds": 2,
"intervalSeconds": 10,
"maxConsecutiveFailures": 3
}],
"upgradeStrategy": {
"minimumHealthCapacity": 0.5,
"maximumOverCapacity": 0.5
}
}
它会指示Marathon调用4个Docker服务实例,来源则为来自registry.local/test-server且拥有master-ef5a154e25b268c611006d08a78a3ec0a451e7ed-56标签的镜像。我们将其称为服务定义。我们不会对其规范进行具体讨论,感兴趣的朋友可以 点击此处 查阅Marathon API参考。更重要的是,此文件能够在构建过程中自动生成。对于每一项可部署服务,其服务定义模板中都包含一个以“$”开头的占位符。之前提到的文件即可利用以下模板生成:
{
"id": "/app/$environment/test-server",
"labels": {
"version": "$tag",
"environment": "$environment"
},
"env": {
"SERVICE_TAGS": "$environment,internal-listen-http-3000",
"SERVICE_NAME": "test-server"
},
"cpus": 0.05,
"mem": 64.0,
"instances": $instances,
"args": [
"service-wrapper.sh", "dockerhost:18080", "dockerhost:18500", "app/$environment/test-server",
"node", "/app/server.js"
],
"container": {
"type": "DOCKER",
"docker": {
"image": "registry.local/test-server:$tag",
"forcePullImage": true,
"network": "BRIDGE",
"portMappings": [{
"containerPort": 3000
}]
}
},
"healthChecks": [{
"protocol": "HTTP",
"path": "/healthcheck",
"gracePeriodSeconds": 2,
"intervalSeconds": 10,
"maxConsecutiveFailures": 3
}],
"upgradeStrategy": {
"minimumHealthCapacity": 0.5,
"maximumOverCapacity": 0.5
}
}
请注意,其中的$tag、$environment与$instances就是占位符。$tag值会在构建过程中生成并被以下简单脚本添加至service.json当中:
#!/bin/bash
set -e
VERSION="$CI_BRANCH-$CI_COMMIT-$CI_BUILD_NUMBER"
declare -A TARGETS=(
[test-server]="."
)
# Set version in service.json
for i in "${!TARGETS[@]}"
do
SERVICE=${TARGETS[$i]}/service.json
TARGET=service-defs/${TARGETS[$i]}
mkdir -p $TARGET
echo "Setting version $VERSION for $SERVICE"
sed "s/\$tag/$VERSION/g" $SERVICE > $TARGET/service-$CI_BRANCH.json
cp $TARGET/service-$CI_BRANCH.json $TARGET/service-$VERSION.json
done
它创建两条服务定义:其一以完整版本命名,其二以分支版本命名,即 service-master-ef5a154e25b268c611006d08a78a3ec0a451e7ed-56.json 与 service-master.json。在这两个文件当中,$tag会被替换为 master-ef5a154e25b268c611006d08a78a3ec0a451e7ed-56,但 $environment 与 $instances 则仍然保持不变,我们随后还需要在部署阶段使用它们。下面来看看Drone的build配置(其完整语法可 点击此处 查看):
build:
image: registry.local/buildimage-nodejs:latest
commands:
- tools/gen-service-defs.sh
publish:
docker:
image: plugins/drone-docker
repo: registry.local/test-server
tag:
- latest
- $BRANCH
- $BRANCH-$COMMIT-$BUILD_NUMBER
s3:
image: plugins/drone-s3
acl: public-read
region: eu-west-1
bucket: build-artifacts
access_key: $S3_ACCESS_KEY
secret_key: $S3_SECRET_KEY
source: service-defs/
target: test-server/
recursive: true
而后,CI根据指令发布build构件:
- 创建一套Docker镜像并将其推送至Docker仓库
- 将生成的服务定义发送至S3
我们完全可以将一部分最新发布的Docker镜像标签存储在Docker 仓库当中,甚至可以在磁盘空间比较充裕时全部加以存储。通过这种方式,我们就能在新近部署的版本出现问题时利用Marathon轻松回滚至原有版本。
现在我们已经可以部署自己的全新服务版本了。为了完成这项任务,我们需要将服务定义JSON发送至Marathon的/v2/apps API。不过首先,我们需要替换现有占位符,即$environment与$instances。尽管相关操作非常简单,但我们仍然要利用marathon-deploy工具实现自动化处理。其能够自动下载服务定义模板,利用对应值替换点位符并创建/更新Marathon中的应用。具体方式如下:
`marathon-deploy.sh <service-template-url> <environment> [instances-count]`
其中service-template-url为被发布至S3的服务定义构件的URL,而environment则可为任意其它运行时环境(例如分段、生产、A/B分组测试等),instances-count则允许指定需要启动的服务实例数量,默认情况下为1。例如:
`marathon-deploy.sh https://build-artifacts.s3.amazonaws.com/test-server/service-master.json staging`
其将主分支的最新build部署至分段环境并运行单一实例。如:
`marathon-deploy.sh https://build-artifacts.s3.amazonaws.com/test-server/service-master-ef5a154e25b268c611006d08a78a3ec0a451e7ed-56.json production 4`
将某一特定build部署至生产环境并运行4个实例。
在本示例中,我们将marathon-deploy脚本复制到全部Mesos-slave 的宿主机当中,并通过Chronos进行配置与部署。因为我们已经将各关键服务预部署到了不同环境当中,因此这一部署流程只需要一次点击即可完成。Chronos的最大优势在于,它能够将大量任务串联起来,意味着大家能够通过配置在实际部署前、后执行一次性任务以准备运行时环境。
服务发现与负载均衡
分布式系统中的服务总是出于种种原因而不断上线、下线,例如服务启动/停止,规模伸缩或者服务故障。与利用已知IP地址及主机名称同服务器协作的静态负载均衡器不同,Marathon中的负载均衡机制的实时性使得其需要以更为复杂的方式进行服务注册与注销。有鉴于此,我们需要利用某种服务注册表以容纳已注册服务信息并将此信息提供给客户端。这一概念也就是服务发现,且成为大多数分布式系统中的核心组件。
这里就要用到Consul了。正如其官方网站上所言,“Consul能够轻松帮助服务进行自我注册,同时通过DNS或者HTTP接口发现其它服务”。除此之外,它还拥有其它一些非常实用的功能,我们将在后文提到。现在我们已经拥有了服务注册表,接下来要做的就是告知其哪些服务需要启动、这些服务的具体位置(主机名称与端口)并可选择提供其它相关元信息。实现这一目标的方法之一在于让服务本身直接使用Consul API,但这种作法会导致各项服务必须拥有内置通信逻辑。如果服务数量不多还好,面对大规模服务集时这将成为一场灾难,特别是当它们由不同编程语言编写而成时。另一种方式在于利用某些第三方工具对服务进行监控,并将服务报告给Consul。我们使用的程序名为marathon-registrator,它能够与Marathon紧密集成并注册Marathon所运行的任何服务类型。另一种选项则是使用Gliderlabs registrator,当然前提是大家的服务全部存在于Docker容器当中。选择一种工具,将其实例运行在Mesos-slave宿主机上即可。
服务注册完成之后,其它服务就能够对其进行定位了。如此一来,它们就能够利用Consul API或者DNS进行直接通信并获取此类元信息(即客户端发现)。而另一种方式则是使用HAProxy等负载均衡器(即服务器端发现)。
HAProxy服务发现较客户端发现拥有多种优势:
- 免费负载均衡机制。
- 能够将服务注册表中的变更即时传播至消费方。HAProxy可重配置且能够在变更发生后立即将请求路由至新实例。
- 配置更为灵活,例如:负载均衡策略、运行状态检查、ACL、A/B测试、日志记录以及统计等等。
- 不需要由服务实现额外的发现逻辑。
不过HAProxy是如何在Consul中追踪已注册服务的?一般来讲,其配置会利用全部已知后端以静态方式完成。不过我们也可以例如consul-template等外部工具对其进行动态构建。这款工具能够监控Consul中的变更并生成任意文本文件,因此其并不只限于配置HAProxy,亦可用于其它能够利用文本文件实现配置的工具(例如nginx、varnish以及apache等等)。该模板语言的说明文档非常全面,感兴趣的朋友可以点击此处查看。
大家可能已经注意到,我们在概览图中运行有两套不同的HAProxy配置:一套用于内部负载均衡,另一套用于外部负载均衡。内部实例跨越各后端服务提供实际服务发现与负载流量。外部实例则额外将服务发现声明至TCP 80端口并接收来自外部的请求,以此实现前端服务负载均衡。
在这些不同的HAProxy实例中,我们需要管理两套独立的consul-template模板文件——这两个文件本身则由另一套模板引擎(即Jinja2)在Saltstack进行设备配置时构建完成。这种作法主要是为了保证流程清晰,同时将来自设备配置软件的数据填充至其中的特定部分。让我们首先来看外部负载均衡器配置模板。请注意,raw/endraw标记负责让Jinja引擎忽略Go模板的大括号并按原样使用初始内容:
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
user haproxy
group haproxy
daemon
maxconn {{key "service/haproxy/maxconn"}}
# Default SSL material locations
ca-base /etc/ssl/certs
crt-base /etc/ssl/private
ssl-default-bind-options no-sslv3 no-tls-tickets
ssl-default-bind-ciphers EECDH+AESGCM:EDH+AESGCM:AES256+EECDH:AES256+EDH
tune.ssl.default-dh-param 2048
{% include 'mesos/files/haproxy-defaults.ctmpl.jinja' %}
{% include 'mesos/files/haproxy-internal-frontend.ctmpl.jinja' %}
{% include 'mesos/files/haproxy-external-frontend.ctmpl.jinja' %}
{% include 'mesos/files/haproxy-wellknown-services.ctmpl.jinja' %}
{% include 'mesos/files/haproxy-backends.ctmpl.jinja' %}
其中还包含其它一些关联性。haproxy-defaults.ctmpl.jinja属于常见于各类HAProxy配置示例中的静态部分,而haproxy-internal-frontend.ctmpl.jinja则比较有趣——它负责指定内部服务发现配置的实现位置。
其基本思路在于为每一项可发现服务匹配一条已知端口编号,同时创建一套HAProxy前端以监听该端口。我们将使用与每项已注册服务一同存储的元信息。Consul允许用户为服务指定一套关联标签列表,而marathon-registrator会通过名为SERVICE_TAGS的服务环境变量读取这些标签。查看test-server的service.json模板,其中包含两个以逗号隔开的标签,即$environment与internal-listen-http-3000。后者在consul-template模板中用于标记已声明端口以实现服务发现的服务(在本示例中为3000)。以下代码片段会自动生成必要的HTTP前端:
{% raw %}
{{range $service := services}}{{range $tag := $service.Tags}}
{{$servicePort := $service.Name | regexReplaceAll "^[\\w-]+?(\\d*)$" "$1"}}{{$tagPort := $tag | regexReplaceAll "^[\\w-]+?(\\d*)$" "$1"}}
{{if or (not $servicePort) (eq $servicePort $tagPort)}}
{{if $tag | regexMatch "internal-listen-http-\\d+"}}
##
# Production internal http frontend for {{$service.Name}}
##
frontend internal_http_in_production:{{$service.Name}}
{% endraw %} bind :{{$tag | replaceAll "internal-listen-http-" ""}}
use_backend cluster_production:{{$service.Name}}
{% raw %} ##
# Staging internal http frontend for {{$service.Name}}
##
frontend internal_http_in_staging:{{$service.Name}}
{% endraw %} bind :1{{$tag | replaceAll "internal-listen-http-" ""}}
use_backend cluster_staging:{{$service.Name}}
{{end}}
{{end}}
{{end}}{{end}}
{% raw %} {% endraw %}它的外环会列出全部Consul服务,内环则列出每项服务的标签并尝试找到与internal-listen-http-匹配的条目。每一次匹配成功,其都会创建对应的HTTP前端。这里的每项服务都拥有两种硬编码环境:production与staging,用于进行区分。其中分段环境的端口编号会以“1”开头,因此如果生产前端监听端口3000,那么分段则监听端口13000。
另外,if语句允许我们为单一服务指定多个可发现端口。要实现这一效果,我们只需要在标签列表当中额外添加internal-listen-http-标记,例如:
$environment,internal-listen-http-3000,internal-listen-http-3010
现在我们需要添加一个指向container.docker.portMappings服务定义文件组的声明端口,从而保证Marathon能够正确配置我们的容器网络。请注意,本示例中的marathon-registrator将分别注册两项服务:test-server-3000与test-server-3010,对二者进行分别解析并避免名称混淆。
大家也可以利用其它预定义标记在模板中实现其它逻辑类型,例如引入internal-listen-tcp-以生成TCP前端,或者利用balance-roundrobin或balance-leastconn控制均衡策略。
这套模板允许我们配置HAProxy,从而指定每台设备通过接入localhost:以访问每项Consul已知服务,最终解决服务发现问题。
在haproxy-wellknown-services.ctmpl.jinja当中,我们可以指定多种静态管理服务,例如Marathon、Consul以及Chronos,这是因为它们较易于发现。它们会在设备配置过程中由systemd/upstart/etc启动。举例来说,以下代码片段允许来自集群内任意设备的请求通过联系localhost:18080 轻松访问Marathon实例,而localhost:14400 与localhost:18500 则分别对应Chronos与Consul(在本示例中,集来自配置管理软件):
frontend internal_http_in:marathon
bind :18080
use_backend cluster:marathon
frontend internal_http_in:chronos
bind :14400
use_backend cluster:chronos
listen internal_http_in:consul
bind :18500
timeout client 600000
timeout server 600000
server local 127.0.0.1:8500
backend cluster:marathon
option forwardfor
option httpchk GET /ping
balance roundrobin
{% - for host, ip in master_nodes.iteritems() %}
server {{ host }} {{ ip }}:8080 check inter 10s
{% endfor -%}
backend cluster:chronos
option forwardfor
option httpchk GET /ping
balance roundrobin
{%- for host, ip in master_nodes.iteritems() %}
server {{ host }} {{ ip }}:4400 check inter 10s
{% endfor -%}haproxy-external-frontend.ctmpl.jinja用于描述HTTP与HTTPS前端。其中包含多套Jinja宏,用于为域名匹配定义ACL规则并将后端与这些规则相绑定:
{% macro hosts(environment, domain_prefix='') -%}
# {{ environment }} hosts
acl host_{{ environment }}:test-server hdr_dom(host) -i -m str {{ domain_prefix }}mesos-test.domain.com
{%- endmacro %}
{% macro bind(service, environment) -%}
use_backend cluster_{{ environment }}:{{ service }} if host_{{ environment }}:{{ service }}
{%- endmacro %}
frontend external_https_in
bind :443 ssl crt domain_com.pem
http-response set-header Strict-Transport-Security max-age=31536000;\ preload
http-response set-header X-Frame-Options DENY
http-response set-header X-Content-Type-Options nosniff
{{ hosts('staging', 'staging-') }}
{{ hosts('production') }}
# Staging bindings
{{ bind('test-server', 'staging') }}
# Production bindings
{{ bind('test-server', 'production') }}
frontend external_http_in
bind :80
{{ hosts('staging', 'staging-') }}
{{ hosts('production') }}
# Staging bindings
{{ bind('test-server', 'staging') }}
# Production bindings
{{ bind('test-server', 'production') }}
最后,还有haproxy-backends.ctmpl.jinja文件。它会列出之前章节中提到的全部可用服务。所有后端都可以进行手动调整,因为用户可能需要满足运行状态检查或者负载均衡方面的特殊要求:
{% macro backends(environment) -%}
##
# {{ environment }} backends
##
{{ '{{' }}$environment := "{{ environment }}"{{ '}}' }}
backend cluster_{{ environment }}:test-server
option forwardfor
option httpchk GET /healthcheck
balance roundrobin{% raw %}{{range $i, $s := service (print $environment ".test-server")}}
server {{$s.Node}}-{{$i}} {{$s.Address}}:{{$s.Port}} check inter 10s fall 1 rise 1{{end}}{% endraw %}
{%- endmacro %}
{{ backends('production') }}
{{ backends('staging') }}
内部负载均衡配置文件要稍稍简单一点,其只需要将连接路由至内部可访问服务:
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
user haproxy
group haproxy
daemon
maxconn {{key "service/haproxy/maxconn"}}
{% include 'mesos/files/haproxy-defaults.ctmpl.jinja' %}
{% include 'mesos/files/haproxy-internal-frontend.ctmpl.jinja' %}
{% include 'mesos/files/haproxy-wellknown-services.ctmpl.jinja' %}
{% include 'mesos/files/haproxy-backends.ctmpl.jinja' %}
零停机时间部署
动态运行时系统的一大共通优势在于,其能够以零停机时间为前提的实现服务部署。在实际部署过程中,我们往往希望确保服务的可用性不受影响。下面来看如何在自己的系统中实现这一效果。
其基本思路在于运行多个服务实例以支撑输入请求,并在部署期间一一替换这些实例:只有新实例顶替上之后,我们才会关停旧实例。Marathon能够完全搞定这样的滚动重启方式,但为了保证恒定的正常运行时间,我们还需要确保负载均衡器停止向已经被关停的实例路由流量。
下面要讨论Mesos如何停止基于Docker的服务实例。与其它Unix进程控制系统一样,它会尝试以正常方式停止服务。首先,SIGTERM会被发送至目标进程,而后该进程预计将在挂起请求并清空后自行退出。如果其在指定时间内仍未退出,SIGKILL会强制将其关闭。Mesos的具体执行方式如下:
docker stop -t=<TIMEOUT> <CONTAINER>
(详见:https://docs.docker.com/engine/reference/commandline/stop/)
现在,我们的服务应该能够正确处理终止信号了(其同样也是十二因子应用原则之一)。在接收到SIGTERM后,其应该告知负载均衡器不再向其路由流量。要实现这一效果,最简单的方式就是拒绝全部后续运行状态检查,但仍然正常处理其它潜在请求。一旦负载均衡器发现该实例运行状态不正常,它将停止将流量路由至该处。为了确保这一流程正常实现,我们需要确保关停超时足够长,使得负载均衡器能够自行发现运行状态变化并停止对挂起请求的处理。默认情况下,Mesos的配置超时为5秒,不过大家也可以利用以下命令行参数变更该值:
--executor_shutdown_grace_period=60secs --docker_stop_timeout=30secs
感兴趣的朋友也可以参阅https://github.com/x-cray/test-server/blob/master/server.js 示例以了解如何处理SIGTERM。
需要强调的是,docker化服务的处理方式有所不同。为了允许信号传入Docker容器进程,我们应当在Dockerfile中使用ENTRYPOINT而非CMD以指定执行权限。在运行时,CMD执行会被打包至shell进程当中,而其不会转发任何信号(详见Docker说明文档)。
基本上,到这里我们已经实现了零停机时间部署。不过对于HAProxy而言,这样的配置只适用于BSD系统。在Linux系统当中还存在一个小问题:当其进行配置重载时,服务器会在一小段时间内(约20到50毫秒)无法监听输入连接。此时段内的全部输入请求自然也将失败。其根本原因在于Linux内核处理SO_REUSEPORT套接选项的方式身上(详情可参阅http://lwn.net/Articles/542629/ )。要解决这个问题,大家不妨阅读由Yelp发布的一篇文章。我们最终选择了简单的SYN数据包丢弃方案。这种作法对于我们目前的使用场景来讲已经足够了。以下为我们的consul-template如何重载HAProxy实例:
#!/bin/bash
iptables -I INPUT -p tcp --dport 80 --syn -j DROP
sleep 0.2
systemctl reload haproxy
iptables -D INPUT -p tcp --dport 80 --syn -j DROP
服务配置管理
我们运行的每项服务都需要拥有自己的配置,包括连接字符串以及API密钥等等。一般来讲,这些信息不应被硬编码,也应该从构建来提供(调试/发布/其它),因为大家可能希望在不同环境(生产/分段/分组测试)下通过不同的配置实现同样的执行效果。
服务配置通常有着不同的来源(各来源亦拥有自己的优先级排序):默认、文件、环境变量、argv等。如果该服务可通过环境变更进行配置,那么我们就能通过多种途径以集中方式对其进行管理——我们要做的就是在服务正式启动前为其准备正确的环境。好消息是,现在我们已经拥有了免费的集中化配置存储方案。Consul提供内置键-值存储(Consul KV)机制,可用于保存配置值——但我们还需要另一种手段将这些值转发至服务环境。
专门用于解决这类需求的工具为envconsul,它会读取Consul KV数据并将其传递至服务环境。而在KV数据更新时,它会重启对应服务实例。不过,它在服务滚动重启以实现服务可用性方面的表现并不好——它会一次性重启全部实例,并因此造成请求失败。作为后备选项,我们可以要求Marathon在KV数据更新时,确保一切已经部署到位并由调度器完成相关重启工作。正因为如此,我们选择了一套小型Shell脚本service-wrapper来代替envconsul,其能够从Consul KV处读取数据,设置服务环境并在KV变更发生时通过Marathon进行重启。另外,它还能够将接收到的SIGTERM转发至底层进程以实现正常关闭。大家应该将这套脚本内置于Docker镜像当中。它需要使用curl与jq,因此请确保二者同样存在于Docker镜像内。以下为具体使用方法:
`service-wrapper.sh <marathon-host:port> <consul-host:port> <prefix> <command>`
其中marathon-host:port 与consul-host:port 拥有自描述特性,prefix值按照惯例应为Marathon应用ID,而command则为包含相关参数的实际服务可执行文件。为了设定各服务环境变量,我们需要将值添加至Consul KV存储内的prefix路径下。以下为service-wrapper运行示例:
`service-wrapper.sh dockerhost:18080 dockerhost:18500 app/staging/test-server node /app/server.js`
请注意dockerhost:18080 与dockerhost:18500 ——二者为之前提到的服务器端内部服务发现示例。
现在如果我们添加/移除/修改prefix之下的任意值,该服务都将根据新配置进行正常重启。
总结
基于Mesos的架构能够帮助我们将多种不同组件加以混合与匹配,从而拥有一套符合实际需要的完整工作系统。举例来说,要实现负载均衡,我们可以使用HAProxy或者Nginx并配合由consul-template生成的动态配置,甚至可以利用其它一些既能够与Consul通信、又能够配置IPVS负载均衡的其它方案替代consul-template。我们还可以利用Netflix Eureka替换整个服务发现/负载均衡层,或者基于Etcd乃至ZooKeeper编写自己的定制化解决方案。构建这样一套系统能够帮助大家更好地了解分布式运行时平台背后的各个进程及其核心组件。
这套平台还具备良好的可移植性,其不仅可被托管至特定云/IaaS之上,也可以通过内部甚至是混合(云加内部)环境实现。目前甚至有一些项目能够 将 Mesos 移植至 Windows 平台。