
第 16 章 文件管理与IO流
程序经常需要访问文件和目录,读取文件信息或写入信息到文件,在Java语言中对文件的读写是通过I/O流技术实现的。本章先介绍文件管理,然后再介绍I/O流。
16.1 文件管理
Java语言使用File类对文件和目录进行操作,查找文件时需要实现FilenameFilter或FileFilter接口。另外,读写文件内容可以通过FileInputStream、FileOutputStream、FileReader和FileWriter类实现,它们属于I/O流,下一节会详细介绍I/O流。这些类和接口全部来源于java.io包。
16.1.1 File类
File类表示一个与平台无关的文件或目录。File类名很有欺骗性,初学者会误认为是File对象只是一个文件,但它也可能是一个目录。
File类中常用的方法如下。
构造方法
File(String path):如果path是实际存在的路径,则该File对象表示的是目录;如果path是文件名,则该File对象表示的是文件。
File(String path, String name):path是路径名,name是文件名。
File(File dir, String name):dir是路径对象,name是文件名。
获得文件名
String getName( ):获得文件的名称,不包括路径。
String getPath( ):获得文件的路径。
String getAbsolutePath( ):获得文件的绝对路径。
String getParent( ):获得文件的上一级目录名。
文件属性测试
boolean exists( ):测试当前File对象所表示的文件是否存在。
boolean canWrite( ):测试当前文件是否可写。
boolean canRead( ):测试当前文件是否可读。
boolean isFile( ):测试当前文件是否是文件。
boolean isDirectory( ):测试当前文件是否是目录。
文件操作
long lastModified( ):获得文件最近一次修改的时间。
long length( ):获得文件的长度,以字节为单位。
boolean delete( ):删除当前文件。成功返回 true,否则返回false。
boolean renameTo(File dest):将重新命名当前File对象所表示的文件。成功返回 true,否则返回false。
目录操作
boolean mkdir( ):创建当前File对象指定的目录。
String[] list():返回当前目录下的文件和目录,返回值是字符串数组。
String[] list(FilenameFilter filter):返回当前目录下满足指定过滤器的文件和目录,参数是实现FilenameFilter接口对象,返回值是字符串数组。
File[] listFiles():返回当前目录下的文件和目录,返回值是File数组。
File[] listFiles(FilenameFilter filter):返回当前目录下满足指定过滤器的文件和目录,参数是实现FilenameFilter接口对象,返回值是File数组。
File[] listFiles(FileFilter filter):返回当前目录下满足指定过滤器的文件和目录,参数是实现FileFilter接口对象,返回值是File数组。
对目录操作有两个过滤器接口:FilenameFilter和FileFilter。它们都只有一个抽象方法accept,FilenameFilter接口中的accept方法如下:
- boolean accept(File dir, String name):测试指定dir目录中是否包含文件名为name的文件。
FileFilter接口中的accept方法如下:
- boolean accept(File pathname):测试指定路径名是否应该包含在某个路径名列表中。
注意 路径中会用到路径分隔符,路径分隔符在不同平台上是有区别的,UNIX、Linux和macOS中使用正斜杠“/”,而Windows下使用反斜杠“”。Java是支持两种写法,但是反斜杠“”属于特殊字符,前面需要加转义符。例如C:Usersa.java在程序代码中应该使用C:\Users\a.java表示,或表示为C:/Users/a.java也可以。
16.1.2 案例:文件过滤
为熟悉文件操作,本节介绍一个案例,该案例从指定的目录中列出文件信息。代码如下:
//HelloWorld.java文件
package com.a51work6;
import java.io.File;
import java.io.FilenameFilter;
public class HelloWorld {
public static void main(String[] args) {
// 用File对象表示一个目录,.表示当前目录
File dir = new File("./TestDir"); ①
// 创建HTML文件过滤器
Filter filter = new Filter("html"); ②
System.out.println("HTML文件目录:" + dir);
// 列出目录TestDir下,文件后缀名为HTML的所有文件
String files[] = dir.list(filter); //dir.list();
// 遍历文件列表
for (String fileName : files) {
// 为目录TestDir下的文件或目录创建File对象
File f = new File(dir, fileName);
// 如果该f对象是文件,则打印文件名
if (f.isFile()) {
System.out.println("文件名:" + f.getName());
System.out.println("文件绝对路径:" + f.getAbsolutePath());
System.out.println("文件路径:" + f.getPath());
} else {
System.out.println("子目录:" + f);
}
}
}
}
// 自定义基于文件扩展名的文件过滤器
class Filter implements FilenameFilter { ③
// 文件扩展名
String extent;
// 构造方法
Filter(String extent) {
this.extent = extent;
}
@Override
public boolean accept(File dir, String name) { ④
// 测试文件扩展名是否为extent所指定的
return name.endsWith("." + extent);
}
}
上述代码第①行创建TestDir目录对象,"./TestDir"表示当前目录下的TestDir目录,还可以表示为".\TestDir"和"TestDir"。
提示 在编程时尽量使用相对路径,尽量不要使用绝对路径。"./TestDir"就是相对路径,相对路径中会用到点“.”,在目录中一个点“.”表示当前目录,两个点表示“..”表示父目录。
注意 在Eclipse工具中运行的Java程序,那么当前目录在哪里呢?例如"./TestDir"表示当前目录下的TestDir子目录,那么应该在哪里创建TestDir目录呢?在Eclipse中当前目录就是工程的根目录,如图16-1所示,当前目录是Eclipse工程根目录,子目录TestDir位于工程根目录下。
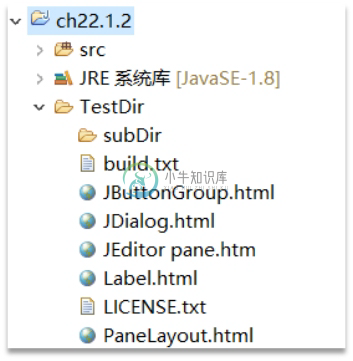
图16-1 Eclipse中的当前目录
上述代码第②行创建针对HTML文件过滤器Filter,Filter类要求实现FilenameFilter接口,见代码第⑤行。FilenameFilter接口要求实现抽象方法accept,见代码第④行,在该方法中通过判断文件名是否指定的扩展名结尾则返回true,否则返回false。
16.2 I/O流概述
Java将数据的输入输出(I/O)操作当作“流”来处理,“流”是一组有序的数据序列。“流”分为两种形式:输入流和输出流,从数据源中读取数据是输入流,将数据写入到目的地是输出流。
提示 以CPU为中心,从外部设备读取数据到内存,进而再读入到CPU,这是输入(Input,缩写I)过程;将内存中的数据写入到外部设备,这是输出(Output,缩写O)过程。所以输入输出简称为I/O。
16.2.1 Java流设计理念
如图16-2所示,数据输入的数据源有多种形式,如文件、网络和键盘等,键盘是默认的标准输入设备。而数据输出的目的地也有多种形式,如文件、网络和控制台,控制台是默认的标准输出设备。

图16-2 I/O流
所有的输入形式都抽象为输入流,所有的输出形式都抽象为输出流,它们与设备无关。
16.2.2 流类继承层次
以字节为单位的流称为字节流,以字符为单位的流称为字符流。Java SE提供4个顶级抽象类,两个字节流抽象类:InputStream和OutputStream;两个字符流抽象类:Reader和Writer。
字节输入流
字节输入流根类是InputStream,如图16-3所示它有很多子类,这些类的说明如表16-1所示。
表 16-1 主要的字节输入流

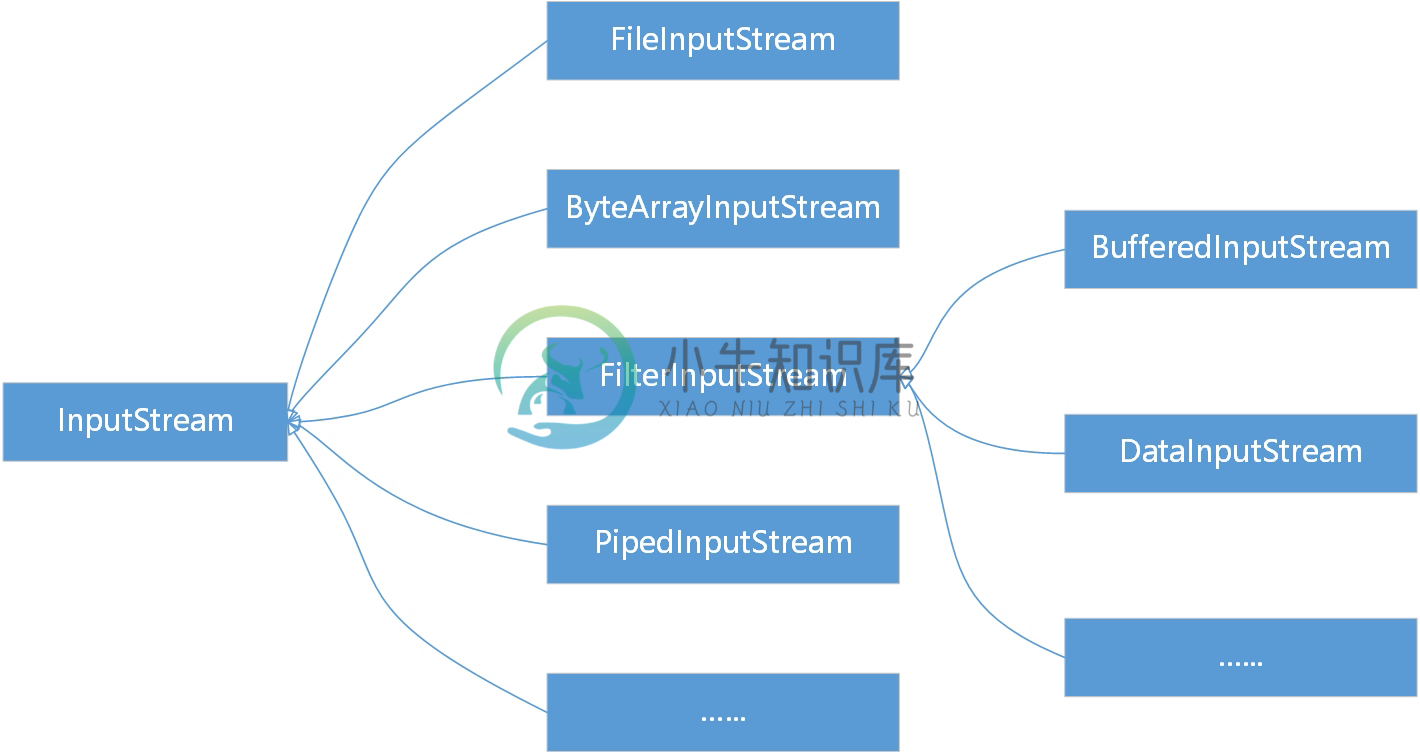
图16-3 字节输入流类继承层次
字节输出流
字节输出流根类是OutputStream,如图16-4所示它有很多子类,这些类的说明如表16-2所示。
表 16-2 主要的字节输出流

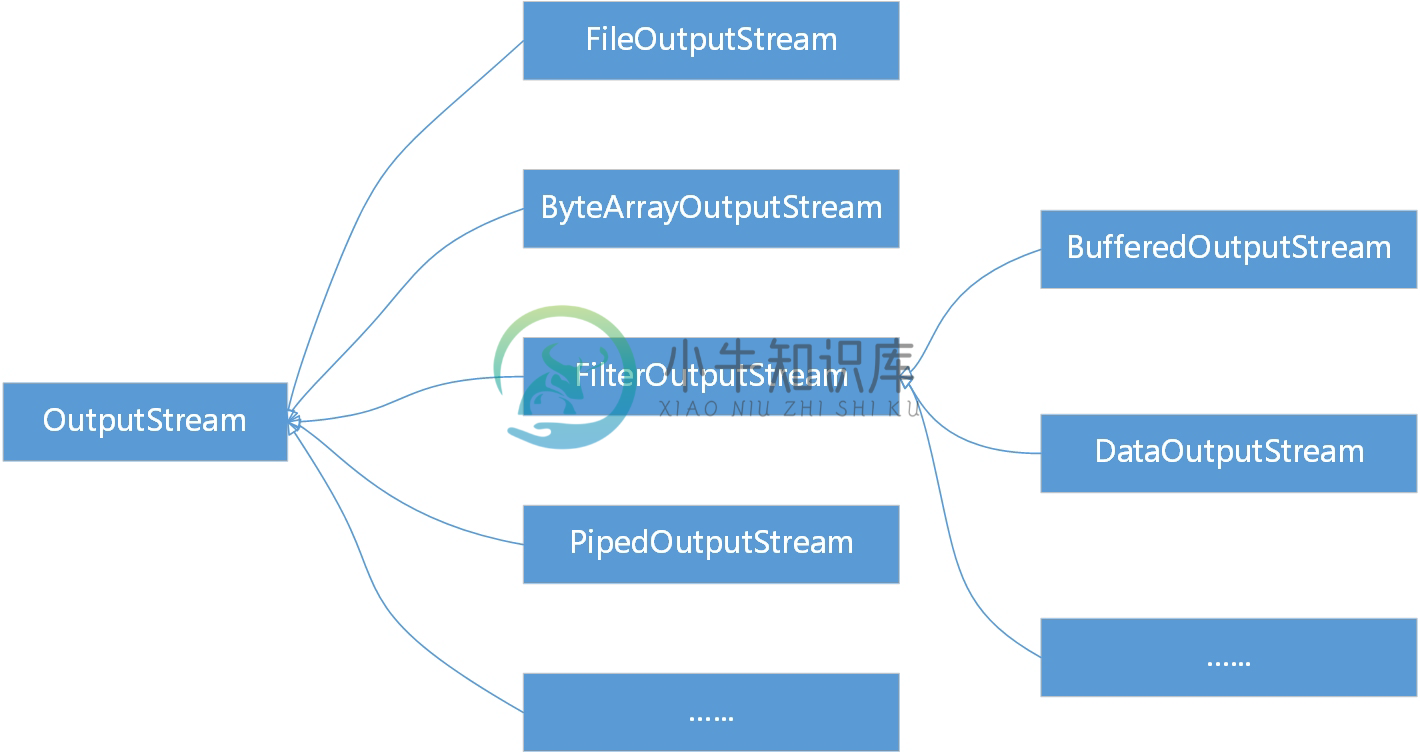
图16-4 字节输出流类继承层次
字符输入流
字符输入流根类是Reader,这类流以16位的Unicode编码表示的字符为基本处理单位。如图16-5所示它有很多子类,这些类的说明如表16-3所示。
表 16-3 主要的字符输入流

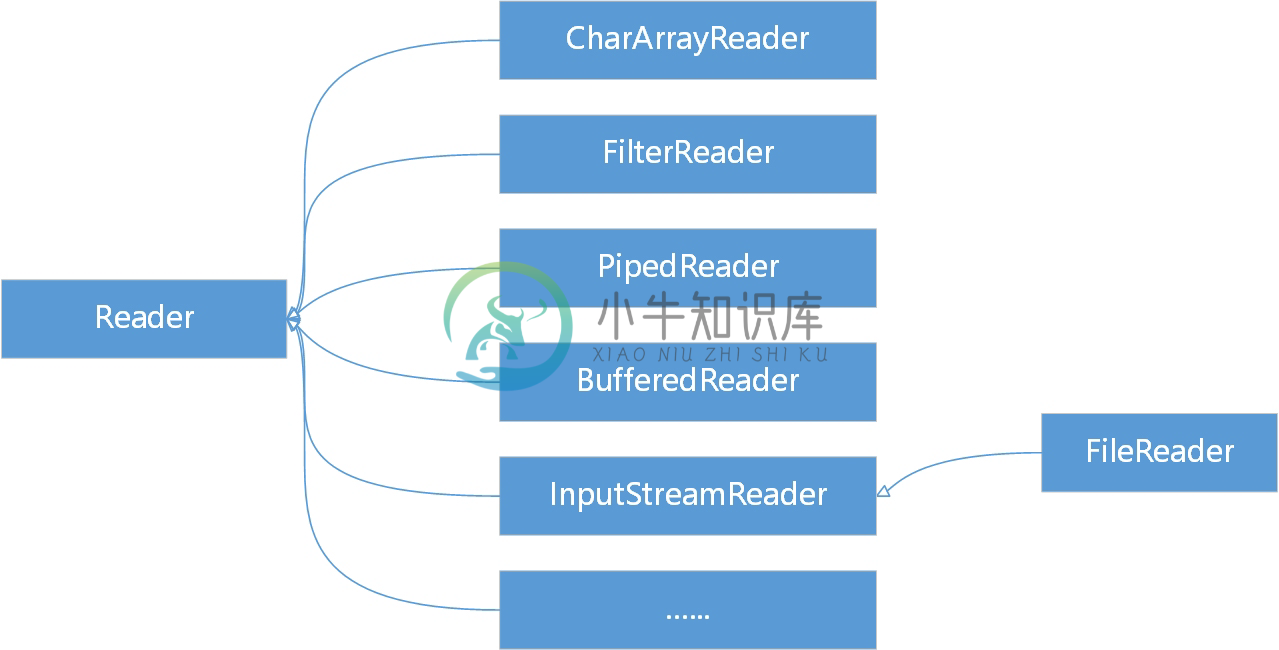
图16-5 字符输入流类继承层次
字符输出流
字符输出流根类是Writer,这类流以16位的Unicode编码表示的字符为基本处理单位。如图16-6所示它有很多子类,这些类的说明如表16-4所示。
表 16-4 主要的字符输出流

图16-6 字符输出流类继承层次
16.3 字节流
上一节总体概述了Java中I/O流层次结构技术,本节详细介绍一下字节流的API。掌握字节流的API先要熟悉它的两个抽象类:InputStream 和OutputStream,了解它们有哪些主要的方法。
16.3.1 InputStream抽象类
InputStream是字节输入流的根类,它定义了很多方法,影响着字节输入流的行为。下面详细介绍一下。
InputStream主要方法如下:
int read():读取一个字节,返回0到255范围内的int字节值。如果因为已经到达流末尾,而且没有可用的字节,则返回值-1。
int read(byte b[] ):读取多个字节,数据放到字节数组b中,返回值为实际读取的字节的数量,如果已经到达流末尾,而且没有可用的字节,则返回值-1。
int read(byte b[ ], int off, int len):最多读取len个字节,数据放到以下标off开始字节数组b中,将读取的第一个字节存储在元素b[off]中,下一个存储在b[off+1]中,依次类推。返回值为实际读取的字节的数量,如果已经到达流末尾,而且没有可用的字节,则返回值-1。
void close():流操作完毕后必须关闭。
上述所有方法都可能会抛出IOException,因此使用时要注意处理异常。
16.3.2 OutputStream抽象类
OutputStream是字节输出流的根类,它定义了很多方法,影响着字节输出流的行为。下面详细介绍一下。
OutputStream主要方法如下:
void write(int b):将b写入到输出流,b是int类型占有32位,写入过程是写入b 的8个低位,b的24个高位将被忽略。
void write(byte b[ ]):将b.length个字节从指定字节数组b写入到输出流。
void write(byte b[ ], int off, int len):把字节数组b中从下标off开始,长度为len的字节写入到输出流。
void flush():刷空输出流,并输出所有被缓存的字节。由于某些流支持缓存功能,该方法将把缓存中所有内容强制输出到流中。
void close( ):流操作完毕后必须关闭。
上述所有方法都声明抛出IOException,因此使用时要注意处理异常。
注意 流(包括输入流和输出流)所占用的资源,不能通过JVM的垃圾收集器回收,需要程序员自己释放。一种方法是可以在finally代码块调用close()方法关闭流,释放流所占用的资源。另一种方法通过自动资源管理技术管理这些流,流(包括输入流和输出流)都实现了AutoCloseable接口,可以使用自动资源管理技术,具体内容参考14.4.2节。
16.3.3 案例:文件复制
前面介绍了两种字节流常用的方法,下面通过一个案例熟悉一下它们的使用,该案例实现了文件复制,数据源是文件,所以会用到文件输入流FileInputStream,数据目的地也是文件,所以会用到文件输出流FileOutputStream。
FileInputStream和FileOutputStream中主要方法都是继承自InputStream和OutputStream前面两个节已经详细介绍了,这里不再赘述。下面介绍一下它们的构造方法,FileInputStream构造方法主要有:
FileInputStream(String name):创建FileInputStream对象,name是文件名。如果文件不存在则抛出FileNotFoundException异常。
FileInputStream(File file):通过File对象创建FileInputStream对象。如果文件不存在则抛出FileNotFoundException异常。
FileOutputStream构造方法主要有:
FileOutputStream(String name):通过指定name文件名创建FileOutputStream对象。如果name文件存在,但如果是一个目录或文件无法打开则抛出FileNotFoundException异常。
FileOutputStream(String name, boolean append):通过指定name文件名创建FileOutputStream对象,append参数如果为 true,则将字节写入文件末尾处,而不是写入文件开始处。如果name文件存在,但如果是一个目录或文件无法打开则抛出FileNotFoundException异常。
FileOutputStream(File file):通过File对象创建FileOutputStream对象。如果file文件存在,但如果是一个目录或文件无法打开则抛出FileNotFoundException异常。
FileOutputStream(File file, boolean append):通过File对象创建FileOutputStream对象,append参数如果为 true,则将字节写入文件末尾处,而不是写入文件开始处。如果file文件存在,但如果是一个目录或文件无法打开则抛出FileNotFoundException异常。
下面介绍如果将./TestDir/build.txt文件内容复制到./TestDir/subDir/build.txt。./TestDir/build.txt文件内容是AI-162.3764568,实现代码如下:
//FileCopy.java文件
package com.a51work6;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileCopy {
public static void main(String[] args) {
try (FileInputStream in = new FileInputStream("./TestDir/build.txt");
FileOutputStream out = new FileOutputStream("./TestDir/subDir/build.txt")) { ①
// 准备一个缓冲区
byte[] buffer = new byte[10]; ②
// 首先读取一次
int len = in.read(buffer); ③
while (len != -1) { ④
String copyStr = new String(buffer); ⑤
// 打印复制的字符串
System.out.println(copyStr);
// 开始写入数据
out.write(buffer, 0, len); ⑥
// 再读取一次
len = in.read(buffer); ⑦
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
控制台输出结果:
AI-162.376
456862.376
上述代码第①行创建FileInputStream和FileOutputStream对象,这是自动资源管理的写法,不需要自己关闭流。
第②行代码是准备一个缓冲区,它是字节数组,读取输入流的数据保存到缓冲区中,然后将缓冲区中的数据再写入到输出流中。
提示 缓冲区大小(字节数组长度)多少合适?缓冲区大小决定了一次读写操作的最多字节数,缓冲区设置的很小,会进行多次读写操作才能完成。所以如果当前计算机内存足够大,而不影响其它应用运行情况下,当然缓冲区是越大越好。本例中缓冲区大小设置的10,源文件中内容是AI-162.3764568,共有14个字符,由于这些字符都属于ASCII字符,因此14个字符需要14字节描述,需要读写两次才能完成复制。
代码第③行是第一次从输入流中读取数据,数据保存到buffer中,len是实际读取的字节数。代码第⑦行也从输入流中读取数据。由于本例中缓冲区大小设置为10,因此这两次读取数据会把数据读完,第一次读了10个字节,第二次读了4个字节。
代码第④行是判断读取的字节数len是否等于-1,代码第⑦行的len = in.read(buffer)事实上执行了两次,第一次执行时len为4,第二次执行时len为-1。
代码第⑤行是使用字节数组构造字符串,然后通过System.out.println(copyStr)语句将字符串输出到控制台。从输出的结果看输出了两次,每次10个字节,第一次输出结果AI-162.376容易理解,它是AI-162.3764568的前10个字符;那么第二次输出的结果456862.376令人匪夷所思,事实上前4个字符(4568)是第二次读取的,后面的6个字符(62.376)是上一次读取的。两次读取内容如图16-7所示。
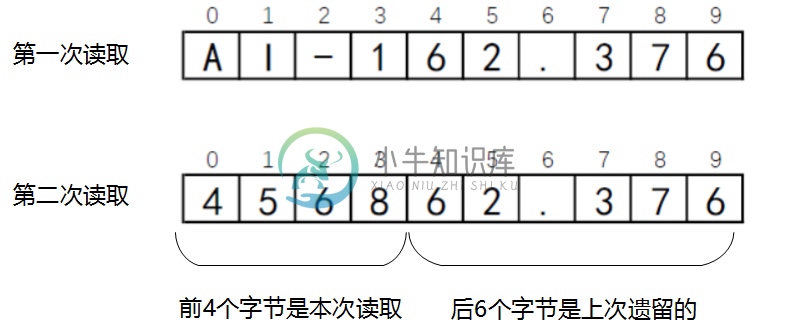
图16-7 文件读取示意图
代码第⑥行out.write(buffer, 0, len)是向输出流写入数据,与读取数据对应,数据写入也调用了两次,第一次len为10,将缓冲区buffer所有元素全部写入输出流;第二次len为4,将缓冲区buffer所有前4个元素写入输出流。注意这里不要使用void write(byte b[ ])方法,因为它没法控制第二次写入的字节数。
上面的案例由于使用了字节输入输出流,所以不仅可以复制文本文件,还可以复制二进制文件。
16.3.4 使用字节缓冲流
BufferedInputStream和BufferedOutputStream称为字节缓冲流,使用字节缓冲流内置了一个缓冲区,第一次调用read方法时尽可能多地从数据源读取数据到缓冲区,后续再到用read方法时先看看缓冲区中是否有数据,如果有则读缓冲区中的数据,如果没有再将数据源中的数据读入到缓冲区,这样可以减少直接读数据源的次数。通过输出流调用write方法写入数据时,也先将数据写入到缓冲区,缓冲区满了之后再写入数据目的地,这样可以减少直接对数据目的地写入次数。使用了缓冲字节流可以减少I/O操作次数,提高效率。
从图16-3和图16-4可见,BufferedInputStream的父类是FilterInputStream,BufferedOutputStream的父类是FilterOutputStream,FilterInputStream和FilterOutputStream称为过滤流。过滤流的作用是扩展其他流,增强其功能。那么BufferedInputStream和BufferedOutputStream增强了缓冲能力。
提示 过滤流实现了装饰器(Decorator)设计模式,这种设计模式能够在运行时扩充一个类的功能。而继承在编译时扩充一个类的功能。
BufferedInputStream和BufferedOutputStream中主要方法都是继承自InputStream和OutputStream前面两个节已经详细介绍了,这里不再赘述。下面介绍一下它们的构造方法,BufferedInputStream构造方法主要有:
BufferedInputStream(InputStream in):通过一个底层输入流in对象创建缓冲流对象,缓冲区大小是默认的,默认值8192。
BufferedInputStream(InputStream in, int size):通过一个底层输入流in对象创建缓冲流对象,size指定的缓冲区大小,缓冲区大小应该是2的n次幂,这样可提供缓冲区的利用率。
BufferedOutputStream构造方法主要有:
BufferedOutputStream(OutputStream out):通过一个底层输出流out 对象创建缓冲流对象,缓冲区大小是默认的,默认值8192。
BufferedOutputStream(OutputStream out, int size):通过一个底层输出流out对象创建缓冲流对象,size指定的缓冲区大小,缓冲区大小应该是2的n次幂,这样可提高缓冲区的利用率。
下面将16.3.3节的文件复制的案例改造成缓冲流实现,代码如下:
//FileCopyWithBuffer.java文件
package com.a51work6;
import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class FileCopyWithBuffer {
public static void main(String[] args) {
try (FileInputStream fis = new FileInputStream("./TestDir/src.zip"); ①
BufferedInputStream bis = new BufferedInputStream(fis); ②
FileOutputStream fos = new FileOutputStream("./TestDir/subDir/src.zip");③
BufferedOutputStream bos = new BufferedOutputStream(fos)) { ④
//开始时间
long startTime = System.nanoTime(); ⑤
// 准备一个缓冲区
byte[] buffer = new byte[1024]; ⑥
// 首先读取一次
int len = bis.read(buffer);
while (len != -1) {
// 开始写入数据
bos.write(buffer, 0, len);
// 再读取一次
len = bis.read(buffer);
}
//结束时间
long elapsedTime = System.nanoTime() - startTime; ⑦
System.out.println("耗时:" + (elapsedTime / 1000000.0) + " 毫秒");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
上述代码第①行是创建文件输入流,它是一个底层流,通过它构造缓冲输入流,见代码第②行。同理,代码第④行是构造缓冲输出流。
为了记录复制过程所耗费的时间,在复制之前获取当前系统时间,见代码第⑤行,System.nanoTime()是获得当前系统时间,单位是纳秒。在复制结束之后同样获取系统时间,代码第⑦行用结束时的系统时间减去复制之前的系统时间,elapsedTime就是耗时了,但是它的单位是纳秒,需要除以106才是毫秒。
提示 在程序代码第⑥行也指定了缓冲区buffer,这个缓冲区与缓冲流内置缓冲区不同,决定是否进行I/O操作次数的是缓冲流内置缓冲区,不是这个缓冲区。
为了比较,可以将16.3.3节的案例也添加耗时输出功能,代码如下:
//FileCopy.java文件
package com.a51work6;
...
public class FileCopy {
public static void main(String[] args) {
try (FileInputStream in = new FileInputStream("./TestDir/src.zip");
FileOutputStream out = new FileOutputStream("./TestDir/subDir/src.zip")) {
//开始时间,当前系统纳秒时间
long startTime = System.nanoTime();
// 准备一个缓冲区
byte[] buffer = new byte[1024];
// 首先读取一次
int len = in.read(buffer);
while (len != -1) {
// 开始写入数据
out.write(buffer, 0, len);
// 再读取一次
len = in.read(buffer);
}
//结束时间,当前系统纳秒时间
long elapsedTime = System.nanoTime() - startTime;
System.out.println("耗时:" + (elapsedTime / 1000000.0) + " 毫秒");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
FileCopy与FileCopyWithBuffer复制相同文件src.zip,缓冲区buffer都设置1024,那么运行的结果:
FileCopyWithBuffer耗时:94.927181 毫秒
FileCopy耗时:206.087523 毫秒
可能每次运行稍有不同,但是可以看出它们的差别了,使用缓冲流的FileCopyWithBuffer明显要比不使用缓冲流的FileCopy速度快。
16.4 字符流
上一节介绍了字节流,本节详细介绍一下字符流的API。掌握字符流的API先要熟悉它的两个抽象类:Reader和Writer,了解它们有哪些主要的方法。
16.4.1 Reader抽象类
Reader是字符输入流的根类,它定义了很多方法,影响着字符输入流的行为。下面详细介绍一下。
Reader主要方法如下:
int read():读取一个字符,返回值范围在0~65535(0x00~0xffff)之间。如果因为已经到达流末尾,则返回值-1。
int read(char[] cbuf):将字符读入到数组cbuf中,返回值为实际读取的字符的数量,如果因为已经到达流末尾,则返回值-1。
int read(char[] cbuf, int off, int len):最多读取len个字符,数据放到以下标off开始字符数组cbuf中,将读取的第一个字符存储在元素cbuf[off]中,下一个存储在cbuf[off+1]中,依次类推。返回值为实际读取的字符的数量,如果因为已经到达流末尾,则返回值-1。
void close():流操作完毕后必须关闭。
上述所有方法都声明了抛出IOException,因此使用时要注意处理异常。
16.4.2 Writer抽象类
Writer是字符输出流的根类,它定义了很多方法,影响着字符输出流的行为。下面详细介绍一下。
Writer主要方法如下:
void write(int c):将整数值为c的字符写入到输出流,c是int类型占有32位,写入过程是写入c的16个低位,c的16个高位将被忽略。
void write(char[] cbuf):将字符数组cbuf写入到输出流。
void write(char[] cbuf, int off, int len):把字符数组cbuf中从下标off开始,长度为len的字符写入到输出流。
void write(String str):将字符串str中的字符写入输出流。
void write(String str,int off,int len):将字符串str 中从索引off开始处的len个字符写入输出流。
void flush():刷空输出流,并输出所有被缓存的字符。由于某些流支持缓存功能,该方法将把缓存中所有内容强制输出到流中。
void close( ):流操作完毕后必须关闭。
上述所有方法都可以会抛出IOException,因此使用时要注意处理异常。
注意 Reader和Writer都实现了AutoCloseable接口,可以使用自动资源管理技术自动关闭它们。
16.4.3 案例:文件复制
前面两节介绍了字符流常用的方法,下面通过一个案例熟悉一下它们的使用,该案例实现了文件复制,数据源是文件,所以会用到文件输入流FileReader,数据目的地也是文件,所以会用到文件输出流FileWriter。
FileReader和FileWriter中主要方法都是继承自Reader和Writer前面两个节已经详细介绍了,这里不再赘述。下面介绍一下它们的构造方法,FileReader构造方法主要有:
FileReader(String fileName):创建FileReader对象,fileName是文件名。如果文件不存在则抛出FileNotFoundException异常。
FileReader(File file):通过File对象创建FileReader对象。如果文件不存在则抛出FileNotFoundException异常。
FileWriter构造方法主要有:
FileWriter(String fileName):通过指定fileName文件名创建FileWriter对象。如果fileName文件存在,但如果是一个目录或文件无法打开则抛出FileNotFoundException异常。
FileWriter(String fileName, boolean append):通过指定fileName文件名创建FileWriter对象,append参数如果为 true,则将字符写入文件末尾处,而不是写入文件开始处。如果fileName文件存在,但如果是一个目录或文件无法打开则抛出FileNotFoundException异常。
FileWriter(File file):通过File对象创建FileWriter对象。如果file文件存在,但如果是一个目录或文件无法打开则抛出FileNotFoundException异常。
FileWriter(File file, boolean append):通过File对象创建FileWriter对象,append参数如果为 true,则将字符写入文件末尾处,而不是写入文件开始处。如果file文件存在,但如果是一个目录或文件无法打开则抛出FileNotFoundException异常。
注意 字符文件流只能复制文本文件,不能是二进制文件。
下面采用文件字符流重新实现16.3.3节文件复制案例,代码如下:
//FileCopy.java文件
package com.a51work6;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class FileCopy {
public static void main(String[] args) {
try (FileReader in = new FileReader("./TestDir/build.txt");
FileWriter out = new FileWriter("./TestDir/subDir/build.txt")) {
// 准备一个缓冲区
char[] buffer = new char[10];
// 首先读取一次
int len = in.read(buffer);
while (len != -1) {
String copyStr = new String(buffer);
// 打印复制的字符串
System.out.println(copyStr);
// 开始写入数据
out.write(buffer, 0, len);
// 再读取一次
len = in.read(buffer);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
控制台输出结果:
AI-162.376
456862.376
上述代码与16.3.3节非常相似,只是将文件输入流改为FileReader,文件输出流改为FileWriter,缓冲区使用的是字符数组。
16.4.4 使用字符缓冲流
BufferedReader和BufferedWriter称为字符缓冲流。BufferedReader特有方法和构造方法有:
String readLine():读取一个文本行,如果因为已经到达流末尾,则返回值null。
BufferedReader(Reader in):构造方法,通过一个底层输入流in对象创建缓冲流对象,缓冲区大小是默认的,默认值8192。
BufferedReader(Reader in, int size):构造方法,通过一个底层输入流in对象创建缓冲流对象,size指定的缓冲区大小,缓冲区大小应该是2的n次幂,这样可提高缓冲区的利用率。
BufferedWriter特有方法和构造方法主要有:
void newLine():写入一个换行符。
BufferedWriter(Writerout):构造方法,通过一个底层输出流out 对象创建缓冲流对象,缓冲区大小是默认的,默认值8192。
BufferedWriter(Writerout, int size):构造方法,通过一个底层输出流out对象创建缓冲流对象,size指定的缓冲区大小,缓冲区大小应该是2的n次幂,这样可提高缓冲区的利用率。
下面将16.4.3节的文件复制的案例改造成缓冲流实现,代码如下:
//FileCopyWithBuffer.java文件
package com.a51work6;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
public class FileCopyWithBuffer {
public static void main(String[] args) {
try (FileReader fis = new FileReader("./TestDir/JButton.html");
BufferedReader bis = new BufferedReader(fis);
FileWriter fos = new FileWriter("./TestDir/subDir/JButton.html");
BufferedWriter bos = new BufferedWriter(fos)) {
// 首先读取一行文本
String line = bis.readLine(); ①
while (line != null) {
// 开始写入数据
bos.write(line); ②
//写一个换行符
bos.newLine(); ③
// 再读取一行文本
line = bis.readLine();
}
System.out.println("复制完成");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
上述代码第①行是通过字节缓冲流readLine方法读取一行文本,当读取是文本为null时说明流已经读完了。代码第②行是写入文本到输出流,由于在输入流的readLine方法会丢掉一个换行符或回车符,为了保持复制结果完全一样,因此需要在写完一个文本后,调用输出流的newLine方法写入一个换行符。
16.4.5 字节流转换字符流
有时需要将字节流转换为字符流,InputStreamReader和OutputStreamWriter是为实现这种转换而设计的。
InputStreamReader构造方法如下:
InputStreamReader(InputStream in):将字节流in转换为字符流对象,字符流使用默认字符集。
InputStreamReader(InputStream in, String charsetName):将字节流in转换为字符流对象,charsetName指定字符流的字符集,字符集主要有:US-ASCII、ISO-8859-1、UTF-8和UTF-16。如果指定的字符集不支持会抛出UnsupportedEncodingException异常。
OutputStreamWriter构造方法如下:
OutputStreamWriter(OutputStream out):将字节流out转换为字符流对象,字符流使用默认字符集。
OutputStreamWriter(OutputStream out,String charsetName):将字节流out转换为字符流对象,charsetName指定字符流的字符集,如果指定的字符集不支持会抛出UnsupportedEncodingException异常。
下面将16.4.3节的文件复制的案例改造成缓冲流实现,代码如下:
//FileCopyWithBuffer.java文件
package com.a51work6;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
public class FileCopyWithBuffer {
public static void main(String[] args) {
try ( // 创建字节文件输入流对象
FileInputStream fis = new FileInputStream("./TestDir/JButton.html"); ①
// 创建转换流对象
InputStreamReader isr = new InputStreamReader(fis);
// 创建字符缓冲输入流对象
BufferedReader bis = new BufferedReader(isr);
// 创建字节文件输出流对象
FileOutputStream fos = new FileOutputStream("./TestDir/subDir/JButton.html");
// 创建转换流对象
OutputStreamWriter osw = new OutputStreamWriter(fos);
// 创建字符缓冲输出流对象
BufferedWriter bos = new BufferedWriter(osw)) { ②
// 首先读取一行文本
String line = bis.readLine();
while (line != null) {
// 开始写入数据
bos.write(line);
// 写一个换行符
bos.newLine();
// 再读取一行文本
line = bis.readLine();
}
System.out.println("复制完成");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
上述代码第①行~第②行只是一条语句,将这6个流放到try (…),由JVM自动管理关闭。上述流从一个文件字节流,构建转换流,再构建缓冲流,这个过程比较麻烦,在I/O流开发过程中经常遇到这种流的“链条”。
本章小结
本章主要介绍了Java文件管理和I/O流技术。读者需要熟悉File类使用。读者还需要掌握字节流两个根类:InputStream和OutputStream,还有字符流的两个根类:Reader和Writer。了解一个常用的装饰器流,如:InputStreamReader、OutputStreamWriter、BufferedReader、BufferedWriter、BufferedInputStream和BufferedOutputStream等。