
Java 分布式作业流调度框架 Hydra-Io
Hydra 是由 Java 实现的作业流调度框架,它可以支持复杂作业流的调度。
主要有以下特点:
1. 支持分布式作业分片
2. 支持本地并发执行
3. 支持复杂作业树(作业流)
4. 实现业务代码和框架代码的解耦
5. 内部实现分布式调度,无需zookeeper等第三方分布式组件
6. 抛弃传统的cron表达,采用简单易懂的作业配置
note: 目前Hydra-Io 处于测试版本,暂没有在生产环境下运行的先例
计划:
在1.0 版本中 将支持一下特性
1. 同步支持zookeeper 、Redis 作为分布式组件
2. 实现基于XML的作业配置
3. 支持spring
测试版体验:
1.定义作业 testInvokeTask
@Task("testInvokeTask")
public class TestInvokeTask {
@Executor("executorA")
@Expression(strategy = ExpressionStrategyEnum.TIMING, measure = ExpressionMeasureEnum.MINUTE,factor = "15")
@Distributed(strategy = DistributedStrategyEnum.SHARDING,number = 2)
public String executorA(EnvironmentParams context){
String jobName = context.getJobName();
int invokeIndex = context.getInvokeIndex();
String str = jobName + " - " + invokeIndex + " running at " + new Date();
System.out.println(str);
return str;
}
@Join("testInvokeTask@executorA")
@Executor("executorB")
public String executorB(EnvironmentParams context, String values){
String jobName = context.getJobName();
int invokeIndex = context.getInvokeIndex();
String str = jobName + " - " + invokeIndex + " running at " + new Date() + " param is:[" + values + " ]" ;
System.out.println(str);
return jobName;
}
@Join("testInvokeTask@executorB")
@Executor("executorC")
public String executorC(EnvironmentParams context, String values){
String jobName = context.getJobName();
int invokeIndex = context.getInvokeIndex();
String str = jobName + " - " + invokeIndex + " running at " + new Date() + " param is:[" + values + " ]" ;
System.out.println(str);
return jobName;
}
}
注解说明:
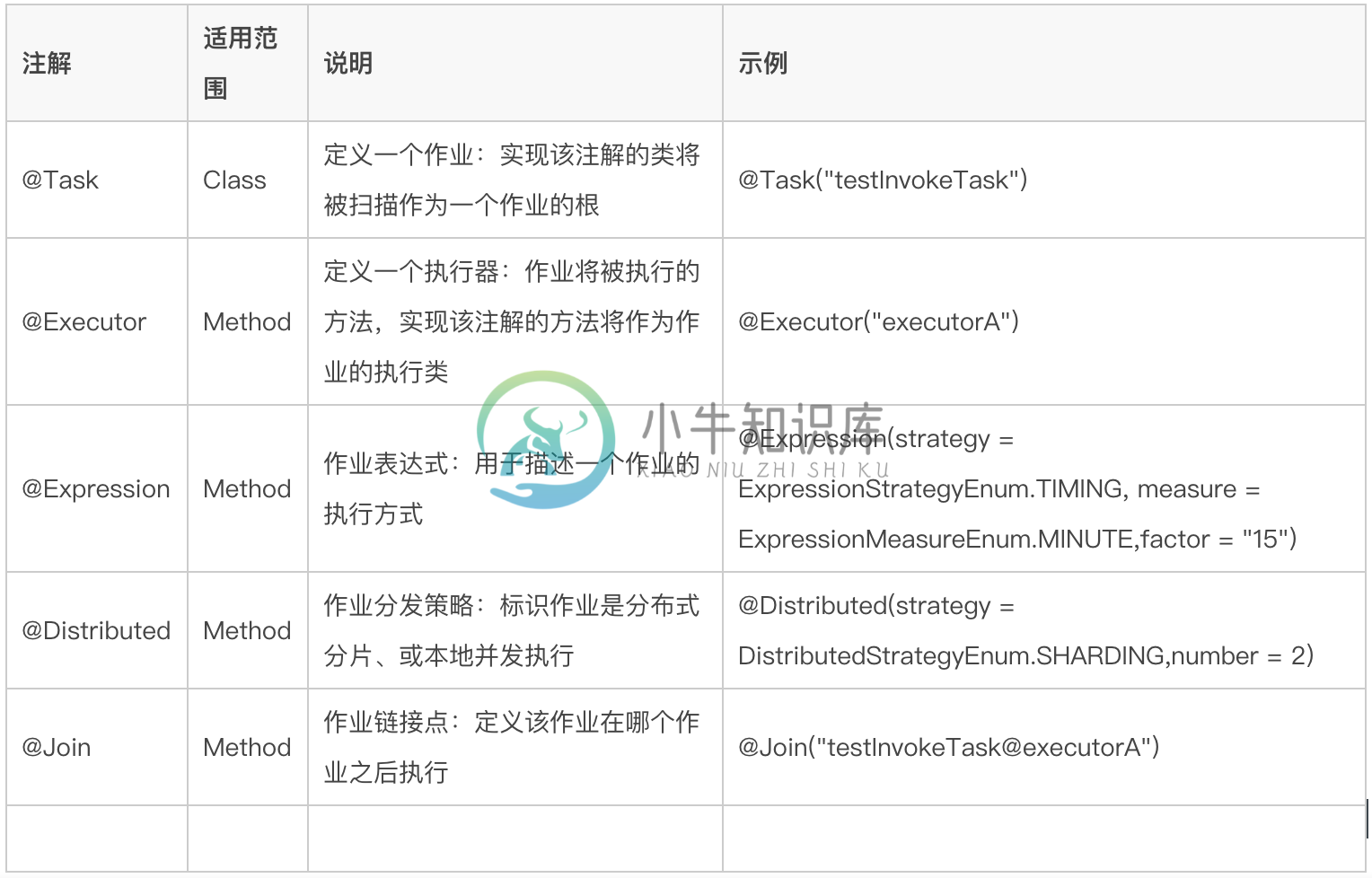
执行作业:
public class Main {
public static void main(String[] strings){
BatchSystem system = AnnotationBatchSystem.getInstance().setScanPackage("com.xxxx.xxxx.test");
system.start();
}
}-
Java 分布式作业流调度框架Hydra-Io Hydra 是由Java实现的作业流调度框架,它可以支持复杂作业流的调度。 主要有以下特点: 支持分布式作业分片 支持本地并发执行 支持复杂作业树(作业流) 实现业务代码和框架代码的解耦 内部实现分布式调度,无需zookeeper等第三方分布式组件 抛弃传统的cron表达,采用简单易懂的作业配置 note: 目前Hydra-Io 处于测试版本,暂没有
-
/* mysql 3.2x.x to 4.x support - by mcbethh (at) u-n-f (dot) com */ /* david (dot) maciejak (at) gmail (dot) com for using libmysqlclient-dev, adding support for mysql version 5.x */ #include "hydra-m
-
hydra -L user.txt -P pass.txt -o savessh.log -f -vV -e ns 10.0.5.24 ssh hydra -L user.txt -P sup.txt -o savessh.log -f -vV -e ns 113.105.144.130 mysql hydra -l root -P pass.txt -t 6 -V mysql://v.v.io
-
hydra golang后端全栈式服务框架,提供接口服务器、web服务器、websocket服务器,RPC服务器、统一调度服务器、消息消费服务器。并具有如下特点: 统一开发模式 规范代码编写,采用统一方式编写服务 统一安装、启停、更新 采用相同的方式进行系统初始化,服务启动、停止、热更新等 统一配置管理 统一采用zookeeper 或 fs 保存配置,本地零配置。并采一方式进行配置安装 统一基础框
-
因实验需要,需要在现有机器上安装hydra、medusa、patator等爆破工具 一、安装hydra (参考:https://bugging.com.cn/2018/05/16/centos6-%E5%AE%89%E8%A3%85hydra/) 1.从GitHub下载安装包:https://github.com/vanhauser-thc/thc-hydra/releases 2.tar xvf
-
你现在拥有了一个远程 Git 版本库,能为所有开发者共享代码提供服务,在一个本地工作流程下,你也已经熟悉了基本 Git 命令。你现在可以学习如何利用 Git 提供的一些分布式工作流程了。 这一章中,你将会学习如何作为贡献者或整合者,在一个分布式协作的环境中使用 Git。 你会学习为一个项目成功地贡献代码,并接触一些最佳实践方式,让你和项目的维护者能轻松地完成这个过程。另外,你也会学到如何管理有很多
-
同传统的集中式版本控制系统(CVCS)不同,Git 的分布式特性使得开发者间的协作变得更加灵活多样。 在集中式系统中,每个开发者就像是连接在集线器上的节点,彼此的工作方式大体相像。 而在 Git 中,每个开发者同时扮演着节点和集线器的角色——也就是说,每个开发者既可以将自己的代码贡献到其他的仓库中,同时也能维护自己的公开仓库,让其他人可以在其基础上工作并贡献代码。 由此,Git 的分布式协作可以为
-
假设Alice现在开始了一个新项目,在/home/alice/project建了一个新的git 仓库(repository);另外Bob的工作目录也在同一台机器,他要提交代码。 Bob 执行了这样的命令: $ git clone /home/alice/project myrepo 这就建了一个新的叫"myrepo"的目录,这个目录里包含了一份Alice的仓库的 克隆(clone). 这份克隆和
-
本文向大家介绍Python使用multiprocessing实现一个最简单的分布式作业调度系统,包括了Python使用multiprocessing实现一个最简单的分布式作业调度系统的使用技巧和注意事项,需要的朋友参考一下 mutilprocess像线程一样管理进程,这个是mutilprocess的核心,他与threading很是相像,对多核CPU的利用率会比threading好的多。 介绍 P
-
嗨,伙计们。我们被分配了一个关于抢占优先调度的任务,我真的不知道如何做到这一点,因为两个或多个进程具有相同的优先级编号。 我必须做一个甘特图,计算周转时间和平均等待时间。 如果可能的话,你们能否发布一个关于如何做到这一点的分步解决方案,以便我可以研究它是如何完成的。 谢谢你们的帮助。
-
现在我需要实现作业队列,因为有些作业不能并行启动。问题是某些作业的状态()是从客户机传递的,为了排队的目的,应该保持这些状态。另一方面,我不能根据用户请求调度作业,因为我不知道什么时候应该执行它!(应该在上一个作业之后立即执行)
-
一、MapReduce概述 Hadoop MapReduce 是一个分布式计算框架,用于编写批处理应用程序。编写好的程序可以提交到 Hadoop 集群上用于并行处理大规模的数据集。 MapReduce 作业通过将输入的数据集拆分为独立的块,这些块由 map 以并行的方式处理,框架对 map 的输出进行排序,然后输入到 reduce 中。MapReduce 框架专门用于 <key,value> 键值
-
Dubbo 是阿里巴巴公司开源的一个Java高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和 Spring框架无缝集成。不过,略有遗憾的是,据说在淘宝内部,dubbo由于跟淘宝另一个类似的框架HSF(非开源)有竞争关系,导致dubbo团队已经解散(参见http://www.oschina.net/news/55059/druid-1-0-9 中的评论),反到是