
binary_log 是一个用于 C++ 的快速二进制记录器。
Highlights
- 以紧凑的二进制格式记录消息
- 快速地
- 每秒数亿条日志
- 基本数据类型的平均延迟为2-7 ns
- 查看基准
- 提供解包器来压缩日志消息
- 使用 fmtlib 格式化日志
- 同步日志记录 - 不是线程安全的
- Header-only library
- 此处提供单个头文件版本
- 需要 C++20
Usage and Performance
以下代码将 10 亿个整数记录到文件中。
#include <binary_log/binary_log.hpp> int main() { binary_log::binary_log log("log.out"); for (int i = 0; i < 1E9; ++i) BINARY_LOG(log, "Hello logger, msg number: {}", i); }
在一个现代工作站桌面上,上述代码的执行时间为~3.5秒。
| Type | Value |
|---|---|
| Time Taken | 3.5 s |
| Throughput | 1.4 Gb/s |
| Performance | 286 million logs/s |
| Average Latency | 3.5 ns |
| File Size | ~5 GB |
foo@bar:~/dev/binary_log$ time ./build/examples/billion_integers/billion_integers real 0m3.561s user 0m2.422s sys 0m1.141s foo@bar:~/dev/binary_log$ ls -lart log.out* -rw-r--r-- 1 pranav pranav 6 Dec 6 07:52 log.out.runlength -rw-r--r-- 1 pranav pranav 32 Dec 6 07:52 log.out.index -rw-r--r-- 1 pranav pranav 4999934337 Dec 6 07:52 log.out
设计目标和决策
- 实现单线程同步记录器 - 不提供线程安全
- 如果用户想要多线程行为,用户可以选择并实现自己的排队解决方案
- 有许多众所周知的无锁队列可用于此目的(moody::concurrentqueue、atomic_queue等)——让用户选择他们想要使用的技术。
- 进入无锁队列的延迟足够大
- 不关心多线程场景的用户不应该为此付出代价
- 查看atomic_queue benchmarks,在许多最先进的多生产者、多消费者队列中发送和接收 4 字节整数(在 2 个线程之间,使用 2 个队列)的平均往返延迟约为150-250 纳秒。
- 避免多次写入静态信息
- 静态信息示例:格式字符串、格式参数的数量以及每个格式参数的类型
- 将静态信息存储在“索引”文件中
- 将动态信息存储在日志文件中(尽可能参考索引文件)
- 在运行时 hot path 中做尽可能少的工作
- 没有任何形式的格式
- 所有格式化都将使用解压缩二进制日志的解包器脱机进行
运作方式
binary_log 将日志拆分为三个文件:
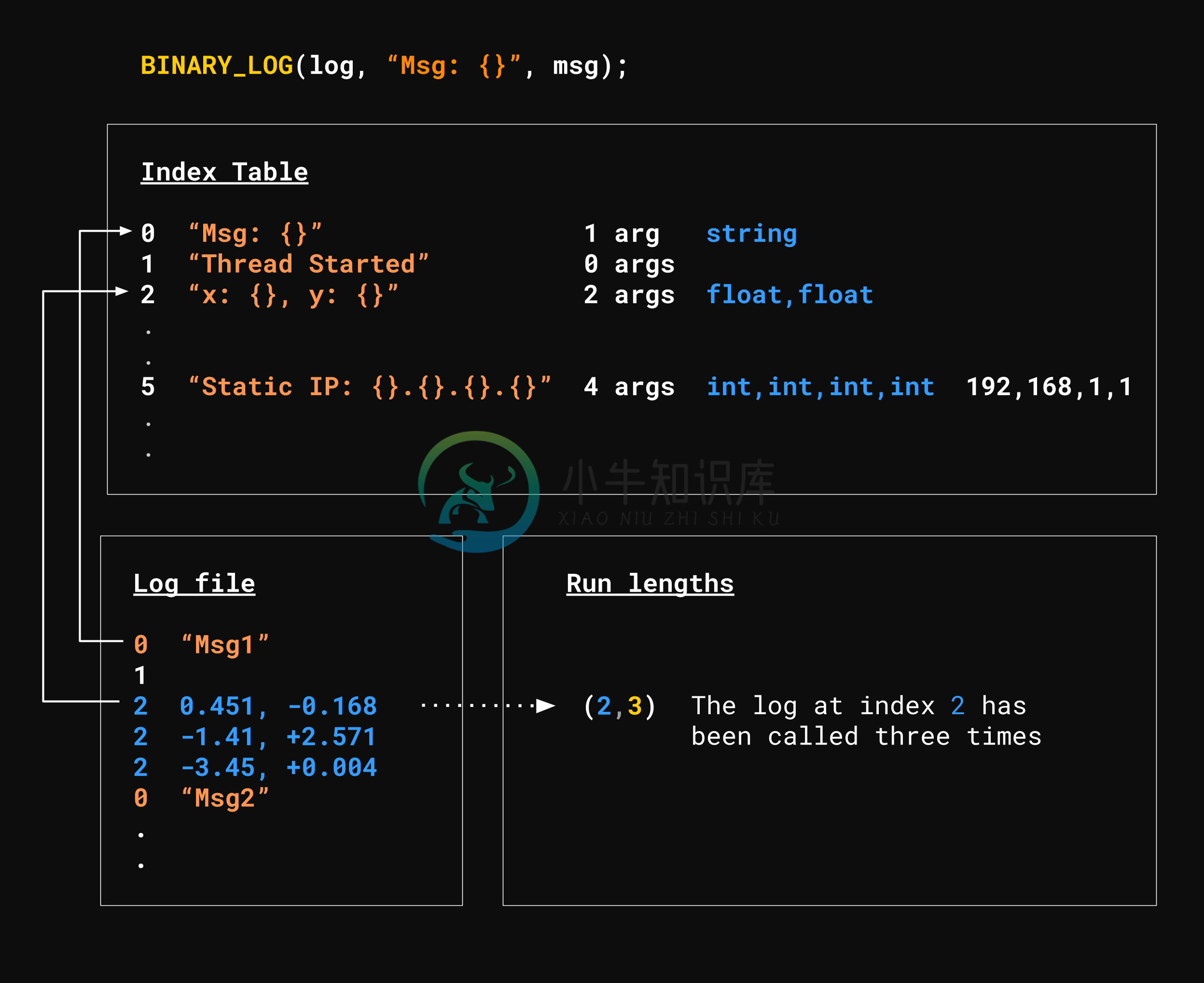
-
1、二进制日志(binary log)介绍 二进制日志(binary log):记录数据库里的数据被修改。 (insert,update,delete,create,drop,alter)的相关语句; 作用:增量数据恢复和主从复制; 2、二进制日志(binary log)调整 1 2 3 4 5 6 7 8 9 10 11 [root@db01-51 ~]# mysql -S /dat
-
mysql5.7缺少的两个库文件 github binary_log_funcs.h /* Copyright (c) 2014, Oracle and/or its affiliates. All rights reserved. This program is free software; you can redistribute it and/or modify it un
-
二分类时AUC和binary_logloss的不一致问题 今天在用LGBM算法对一个二分类的数据进行训练时: lgbm1 = lgbm.LGBMClassifier(num_leaves=10, learning_rate=0.05, n_estimators=2000, ) # n_estimators是循环次数,或者说是树的数目 lgbm1.fit(X_train1, y_train1, ev
-
名称 版本号 mysql-5.7.26-el7-x86_64.tar.gz mysql-5.7 1.在执行mysql初始化指令时抛出异常 [root@localhost bin]# ./mysqld --initialize --user=mysql --basedir=/usr/local/mysql-5.7 --datadir=/usr/local/mysql-5.7/data .mysqld
-
首先来看下binary_cross_entropy的函数形式: torch.nn.functional.binary_cross_entropy(input, target, weight=None, size_average=None, reduce=None, reduction='mean') Parameters input – Tensor of arbitrary shape tar
-
一句话: Softmax 后接 CrossEntropyLoss, LogSoftmax 后接 NLLLoss F.cross_entropy 内含 Softmax F.binary_cross_entropy 不含 Softmax 理由 Softmax 之后,得到预测概率分布 q i \red{q_i} qi,根据交叉熵公式可计算得到和真实分布 p i \blue{p_i} pi 之间的损失
-
参考链接 需要的包 import torch import torch.nn as nn import torch.nn.functional as F 模拟的输入x变量:4分类问题 batch_size, n_classes = 10, 4 x = torch.randn(batch_size, n_classes) x.shape x维度 torch.Size([10, 4]) 运行: x
-
I ran into the BINARY_DOUBLE to NUMBER problem myself. The correct solution is to ROUND() to the appropriate significant digits.Use LOG() to count how many digits you have, Then calculate which decima
-
torch.nn.functional.binary_cross_entropy_with_logits(input, target, weight=None, size_average=None, reduce=None, reduction=‘mean’, pos_weight=None) 参数说明 input神经网络预测结果(未经过sigmoid),任意形状的tensor target标签值
-
import torch import torch.nn as nn import torch.nn.functional as F batchsize = 10 num_classes = 4 x = torch.randn((batchsize, num_classes)) # print(x) target = torch.randint(num_classes, size=(batchs
-
全程被拷打,稍微有一点没说清楚就直接说重新说一遍 直接说实习内容太简单了,工作量在哪里? http请求的长连接是怎么保持的,连接池是怎么样的,底层是怎么设计的?http报文是怎么构造出来的?现在用的是http那一款协议?1.1/1.2还是2? new一个对象的过程是怎么样的,怎么加载的?看过加载的源码吗? qps怎么算出来的?我说测出来的,他说从线程所需的资源出发考虑,还是不知道要怎么回答? 分布
-
问题内容: 我正在使用Swift,并且注意到Swift不允许创建CFFunctionPointers。它只能绕过并引用现有的。 例如,CoreAudio需要对某些回调使用CFunctionPointer,因此我不能使用纯Swift。 所以我需要在这里使用一些Objective- C蹦床或包装器,将Swift闭包作为参数以及原始的回调原型,然后可以将其分配为回调,但是实际动作发生在Swift中,而不
-
问题内容: 我有一张表: 如果为is ,则表示该用户当前具有该计划。 我想查询的是:(a)他当前正在使用的计划,或(b)他所参与的最新计划。对于每个给定的用户,我只需要返回一行。 现在,我设法通过使用联合和子查询做到了这一点,但是碰巧表很大,而且效率不高。你们中的每个人都可以有一种更快的查询方式吗? 谢谢, [编辑]多数答案在这里返回单个值。那是我的坏事。我的意思是为每个用户返回一个值,但一次返回
-
我正试图将大量数据写入我的SSD(固态驱动器)。我指的是80GB。 我浏览了网页寻找解决方案,但我想出的最好的办法是: 使用Visual Studio 2010编译并进行全面优化并在Windows7下运行,该程序的最大容量约为20MB/s。真正让我困扰的是,Windows可以以150MB/s到200MB/s之间的速度将文件从其他SSD复制到此SSD。所以至少快了7倍。这就是为什么我认为我应该能够走
-
标题应该是不言自明的。 出于调试目的,我希望express打印每个服务请求的响应代码和正文。打印响应代码很容易,但打印响应体更为复杂,因为响应体似乎不容易作为属性使用。 以下情况不起作用: 当然,我可以很容易地在发出请求的客户端打印响应,但我也更喜欢在服务器端打印。 PS:如果有帮助的话,我所有的响应都是json,但希望有一个解决方案可以处理一般的响应。
-
什么是快速收录? 快速收录工具可以向百度搜索主动推送资源,缩短爬虫发现网站链接的时间,对于高实效性内容推荐使用快速收录工具,实时向搜索推送资源。 开发者可通过快速收录工具,向百度搜索主动提交站点新增的高时效性资源,缩短爬虫发现网站链接的时间,一般情况下48小时内即可实现收录。 需要注意的是,快速收录仅限于提交移动端页面及移动端自适应页面。 如何优先获得快速收录权益? 开发者将站点与小程序相关联,提