
关于关系数据库如何快速查询表的记录数详解

前言
在数据库中,很多人员习惯使用SELECT COUNT(*) 、SELECT COUNT(1) 、SELECT COUNT(COL)来查询一个表有多少记录,对于小表,这种SQL的开销倒不是很大,但是对于大表,这种查询表记录数的做法就是一个非常消耗资源了,而且效率很差。下面介绍一下SQL Server、 Oracle、MySQL中如何快速获取表的记录数。
SQL SERVER 数据库
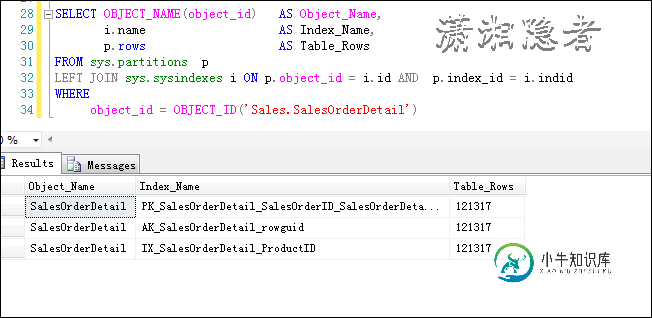
在SQL Server数据库中, 对象目录视图sys.partitions中有一个字段rows会记录表的记录数。我们以AdventureWorks2014为测试数据库。

SELECT OBJECT_NAME(object_id) AS Object_Name,
i.name AS Index_Name,
p.rows AS Table_Rows
FROM sys.partitions p
LEFT JOIN sys.sysindexes i ON p.object_id = i.id AND p.index_id = i.indid
WHERE
object_id = OBJECT_ID('TableName')
那么我们还有一些疑问,我们先来看看这些问题吧!
1:没有索引的表是否也可以使用上面脚本?
2:只有非聚集索引的堆表是否可以使用上面脚本?
3:有多个索引的表,是否记录数会存在不一致的情况?
4:统计信息不准确的表,是否rows也会不准确
5: 分区表的情况又是怎么样?
6:对象目录视图sys.partitions与sp_spaceused获取的表记录函数是否准确。
如下所示,我们先构造测试案例:
IF EXISTS(SELECT 1 FROM sys.objects WHERE type='U' AND name='TEST_TAB_ROW') BEGIN DROP TABLE TEST_TAB_ROW; END IF NOT EXISTS(SELECT 1 FROM sys.objects WHERE type='U' AND name='TEST_TAB_ROW') BEGIN CREATE TABLE TEST_TAB_ROW ( ID INT, NAME CHAR(200) ) END GO SET NOCOUNT ON; BEGIN TRAN DECLARE @Index INT =1; WHILE @Index <= 100000 BEGIN INSERT INTO TEST_TAB_ROW VALUES(@Index, NEWID()); SET @Index+=1; IF (@Index % 5000) = 0 BEGIN IF @@TRANCOUNT > 0 BEGIN COMMIT; BEGIN TRAN END END END IF @@TRANCOUNT > 0 BEGIN COMMIT; END GO
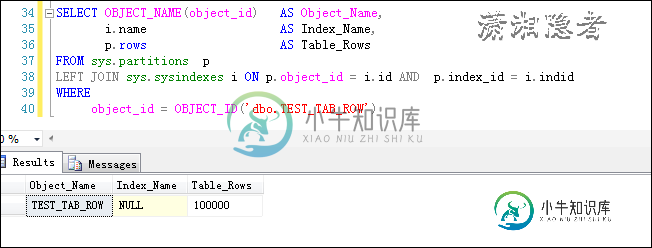
关于问题1、问题2,都可以使用上面脚本, 如下测试所示:
SELECT OBJECT_NAME(object_id) AS Object_Name,
i.name AS Index_Name,
p.rows AS Table_Rows
FROM sys.partitions p
LEFT JOIN sys.sysindexes i ON p.object_id = i.id AND p.index_id = i.indid
WHERE
object_id = OBJECT_ID('dbo.TEST_TAB_ROW')
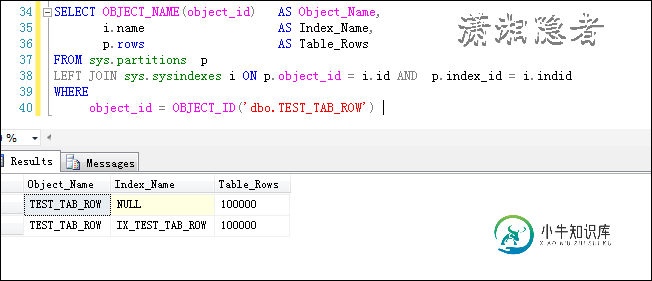
在表dbo.TEST_TAB_ROW 上创建非聚集索引后,查询结果如下所示:
CREATE INDEX IX_TEST_TAB_ROW ON TEST_TAB_ROW(ID);
我们插入500条记录,此时,这个数据量不足以触发统计信息更新,如下所示, Rows Sampled还是1000000
DECLARE @Index INT =1; WHILE @Index <= 500 BEGIN INSERT INTO TEST_TAB_ROW VALUES(100000 +@Index, NEWID()); SET @Index+=1; END
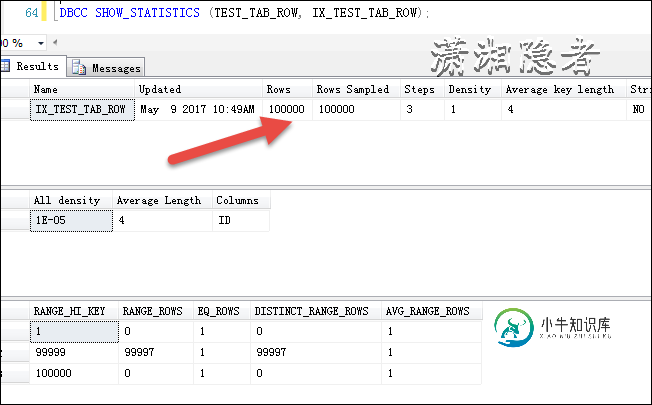
如下所示,发现sys.partitions中的记录变成了100500了,可见rows这个值的计算不依赖统计信息。
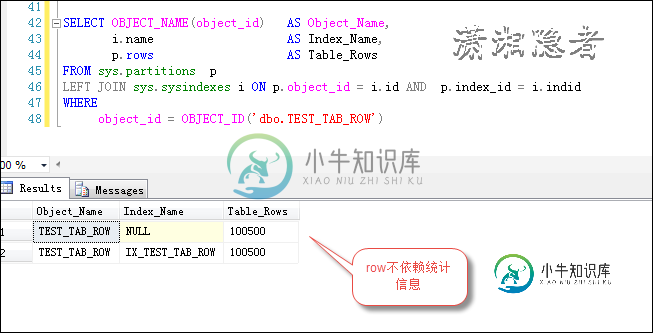
当然,如果你用sp_spaceused,发现这里面的记录也是100500
sp_spaceused 'dbo.TEST_TAB_ROW'

关于问题3:有多个索引的表,是否记录数会存在不一致的情况?
答案:个人测试以及统计来看,暂时发现多个索引的情况下,sys.partitions中的rows记录数都是一致的。暂时没有发现不一致的情况,当然也不排除有特殊情况。
关于问题5: 分区表的情况又是怎么样?
答案:分区表和普通表没有任何区别。
关于问题6:对象目录视图sys.partitions与sp_spaceused获取的表记录函数是否准确?
答案:对象目录视图sys.partitions与sp_spaceused获取的表记录数是准确的。
ORACLE 数据库
在ORACLE数据库中,可以通过DBA_TABLES、ALL_TABLES、USER_TABLES视图查看表的记录数,不过这个值(NUM_ROWS)跟统计信息有很大的关系,有时候统计信息没有更新或采样比例会导致这个值不是很准确。
SELECT OWNER , TABLE_NAME, NUM_ROWS , LAST_ANALYZED FROM DBA_TABLES WHERE OWNER = '&OWNER' AND TABLE_NAME = '&TABLE_NAME'; SELECT OWNER, TABLE_NAME, NUM_ROWS , LAST_ANALYZED FROM ALL_TABLES WHERE OWNER ='&OWNER' AND TABLE_NAME='&TABLE_NAME'; SELECT TABLE_NAME, NUM_ROWS , LAST_ANALYZED FROM USER_TABLES WHERE TABLE_NAME='&TABLE_NAME'
更新统计信息后,就能得到准确的行数。所以如果需要得到正确的数据,最好更新目标表的统计信息,进行100%采样分析。对于分区表,那么就需要从dba_tab_partitions里面查询相关数据了。
SQL>execute dbms_stats.gather_table_stats(ownname => 'username', tabname =>'tablename', estimate_percent =>100, cascade=>true);
MySQL数据库
在MySQL中比较特殊,虽然INFORMATION_SCHEMA.TABLES也可以查到表的记录数,但是非常不准确。如下所示,即使使用ANALYZE TABLE更新了统计信息,从INFORMATION_SCHEMA.TABLES中获取的记录依然不准确
SELECT TABLE_ROWS FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME='table_name'
mysql> SELECT TABLE_ROWS -> FROM INFORMATION_SCHEMA.TABLES -> WHERE TABLE_NAME='jiraissue' -> ; +------------+ | TABLE_ROWS | +------------+ | 36487 | +------------+ 1 row in set (0.01 sec) mysql> select count(*) from jiraissue; +----------+ | count(*) | +----------+ | 36973 | +----------+ 1 row in set (0.05 sec) mysql> analyze table jiraissue; +----------------+---------+----------+----------+ | Table | Op | Msg_type | Msg_text | +----------------+---------+----------+----------+ | jira.jiraissue | analyze | status | OK | +----------------+---------+----------+----------+ 1 row in set (1.41 sec) mysql> SELECT TABLE_ROWS -> FROM INFORMATION_SCHEMA.TABLES -> WHERE TABLE_NAME='jiraissue'; +------------+ | TABLE_ROWS | +------------+ | 34193 | +------------+ 1 row in set (0.00 sec) mysql>
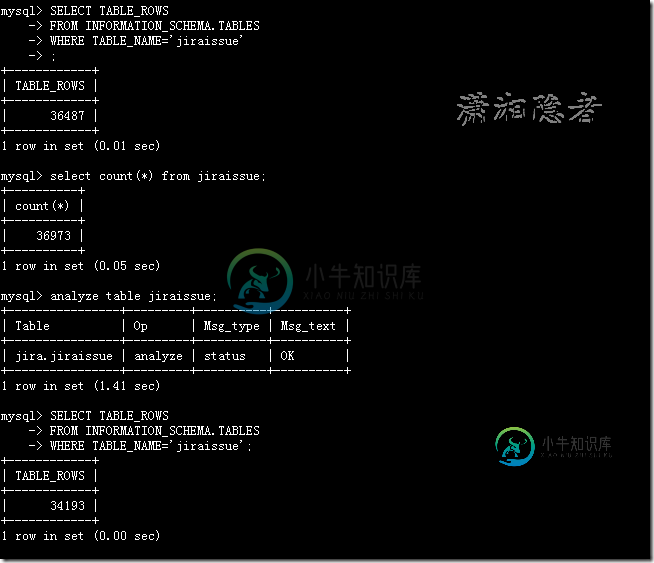
如上所示,MySQL这种查询表记录数的方法看来还是有缺陷的。当然如果不是要求非常精确的值,这个方法也是不错的。
当然,上面介绍的SQL Server、Oracle、MySQL数据库中的方法,还是有一些局限性的。例如,只能查询整张表的记录数,对于那些查询记录数带有查询条件(WHERE)这类SQL。还是必须使用SELECT COUNT(*)这种方法。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对小牛知识库的支持。
-
我有一个Oracle表,它有10列-col1、col2、COL3...COL10。我的要求是-对于col1、col2、col3的唯一值集,即(col1、col2、col3)只允许col4的唯一值,即使它是多次。例如:如果有10行COL1=3,COL2='A005',COL3=10,则所有10行的col4值应相同。 我如何在Oracle中放置此限制?
-
本文向大家介绍MySQL多表数据记录查询详解,包括了MySQL多表数据记录查询详解的使用技巧和注意事项,需要的朋友参考一下 在实际应用中,经常需要实现在一个查询语句中显示多张表的数据,这就是所谓的多表数据记录连接查询,简称来年将诶查询。 在具体实现连接查询操作时,首先将两个或两个以上的表按照某个条件连接起来,然后再查询到所要求的数据记录。连接查询分为内连接查询和外连接查询。 在具体应用中
-
3.移除值事件侦听器和脱机的区别。
-
我有一个密码查询,它应该返回节点和边,这样我就可以在web应用程序中呈现我的图形的表示。我使用Neo4joOperations中的方法运行它。 之前,我使用的是spring数据neo4j 3.3。1使用嵌入式数据库,此查询在返回具有开始节点和结束节点的关系代理方面做得很好。我已经升级到SpringDataNeo4J4.0。0并切换到使用远程服务器,现在它返回的LinkedHashMaps非常空。
-
问题内容: 在数据库中建立适当的关系对数据完整性以外的其他功能没有帮助吗? 它们会改善还是阻碍性能? 问题答案: 我不得不说,适当的关系将比省略它们更好地帮助人们理解数据(或数据的意图),特别是因为维护它们的总成本非常低。 它们的存在不会影响性能,除非是在体系结构方面(正如其他人指出的那样,数据完整性有时会导致外键冲突,这可能会产生某些影响),但是IMHO的许多好处(如果正确使用,则不胜枚举)。
-
本文向大家介绍Hive与关系型数据库的关系?相关面试题,主要包含被问及Hive与关系型数据库的关系?时的应答技巧和注意事项,需要的朋友参考一下 没有关系,hive是数据仓库,不能和数据库一样进行实时的CURD操作。 是一次写入多次读取的操作,可以看成是ETL工具。