
ODFDOM for Java 为希望创建、访问和保存 ODF 文档的开发人员提供一个轻量的 Java API,让他们可以不必详细了解完整的 ODF 标准规范。
ODFDOM 采用层次化的多层结构,其中每个层有特定的用途。由于采用松散耦合的设计,下面的层并不依赖于上面的层。图 1 给出 ODFDOM 分层模型的结构。
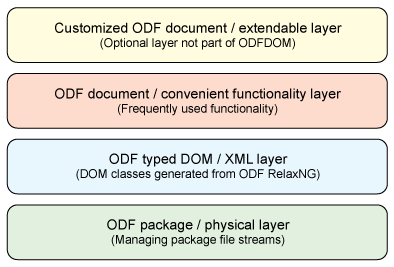
下面简要解释这些层:
- 定制的 ODF 文档 / 可扩展层。后面把这一层称为定制层。尽管它不是 ODFDOM 包的组成部分,但是它设计为 ODFDOM 之上的层,用户可以在这一层覆盖或定制现有的 ODFDOM API 以满足指定的需求。
- ODF 文档 / 便利功能层。后面把这一层称为便利层。这是开发人员关注的重点,因为它基于 DOM 层,为用户提供最丰富、易用的文档操作 API。
- ODF 类型的 DOM / XML 层。后面把这一层称为 DOM 层。ODFDOM 规范和文法(RelaxNG 模式)定义了可用的所有 ODF XML 元素和属性,以及它们在标准化 ODF XML 流中的关系;也就是 ODF 包中的所有 XML 文件(例如 content.xml、styles.xml)。
DOM 层提供用来构建 Document Object Model 的 XML 元素和属性的相关信息。这一层的所有类并不是手工编写的,而是按 ODF 规范自动生成的,因此当 ODF 规范改进或升级时很容易更新这一层。
- ODF 包 / 物理层。后面把这一层称为包层。它是 ODFDOM 层次化结构中最低的一层,它提供对 ODFDOM 包中的物理存储的直接访问,比如 XML 流、图像和嵌入的对象。
-
近期要考虑构建一个支持openDocument的文档结构,就像ms-office的07+,是为了能在linux服务器上可自动生成支持office07的文档简报。以前每次都是根本模板纯手工去制作基于两种xml格式的office,以至于对xml的规范跟schema被熟练,但java对xpath的不完美支持完美的体现在了这类xml中,所以只能手工去写工具函数予以支持,但读写起来还是很不爽! 大家都知道它
-
我设法通过jdom(odfdom-java)做到了这一点,毕竟一点都没有使用过。 绑定的xml本身存在于表示odt的xml中。 您只需要知道表单的ID或标签的名称,即可获得正确的节点。 之后,将构造一个字符串,其中包含带有表单数据的xml。 我的代码如下: import org.apache.xerces.dom.DeepNodeListImpl; import org.apache.xml.se
-
How do I access the XYZ file format in java ? Specifications for many file formats can be found at Wotsit. A large database of file extensions be found at www.file-extensions.org and dotwhat.net And i
-
枚举类 package EnumGetDescription; public enum SpreadSheetType { JXL( "Excel 97-2003 XLS (JXL)" ), POI( "Excel 2007 XLSX (Apache POI)" ), SAX_POI( "Excel 2007 XLSX (Apache POI Streaming)" ),
-
问题内容: 我正在考虑使用MongoDB来存储包含键/值对列表的文档。安全但丑陋且肿的存储方式如下 但是文档元素固有地在底层BSON数据结构中排序,因此原则上: 应该足够了。但是,我希望大多数语言绑定都将它们解释为关联数组,因此可能会扰乱顺序。所以我需要知道的是: MongoDB本身是否 承诺 保留第二种形式的项目顺序。 语言绑定是否具有一些可以提取有序形式的API -即使通常的“便捷” API返
-
我一直在努力获取firestore收藏中所有文档的列表。我想显示集合中所有文档的所有详细信息。我的文档树如下- '组'集合----- 现在,我想获取特定groupID的“任务”集合中的所有文档及其详细信息。 我尝试了这个方法,但它不起作用,因为“没有为“CollectionReference”类型定义“get”方法。”请问怎么绕过这个?
-
我们正在使用谷歌的Firestore获取嵌入式机器配置数据。因为这些数据控制着一个可配置的页面流和许多其他东西,所以它被分割成许多子集合。在这个系统中,每台机器都有自己的顶级文档。然而,当我们向机队中添加机器时,需要花费很长时间,因为我们必须手动复制多个文档中的所有数据。有人知道如何在Python中递归复制Firestore文档、所有的子集合、它们的文档、子集合等吗。您将有一个顶级文档的引用,以及
-
本文向大家介绍PHP的serialize序列化数据以及JSON格式化数据分析,包括了PHP的serialize序列化数据以及JSON格式化数据分析的使用技巧和注意事项,需要的朋友参考一下 PHP的serialize是将变量序列化,返回一个具有变量类型和结构的字符串表达式,而JSON则是一种更轻、更友好的用于接口(AJAX、REST等)数据交换的格式。 其实两者都是以一种字符串的方式来体现一种数据结
-
我有25万个这样的事件: 一个时间段代表半个30分钟,“Anzahl”是一个时间段中的事件数,第一个时间段从2011-01-01 00:00:00开始,“WochenSlots”是时间段%%336,从周六00:00:00开始。所以我想在一周内看到分布情况。 我现在想做的是: 以x标度显示日期(星期一00:00-星期日24:00) 显示显示x%事件分布的行(信封)。 我不知道该怎么做。 dput(P
-
免责声明:刚刚开始和斯巴克玩。 我很难理解著名的“任务不可序列化”异常,但我的问题与我在SO上看到的问题有点不同(或者我认为是这样)。 我有一个很小的自定义RDD()。它有一个字段,用于存储类不实现序列化的对象()。我已经设置了spark.serializer配置选项来使用Kryo。但是,当我在我的RDD上尝试时,我得到了以下结果: 当我往里面看的时候。submitMissingTasks我看到它
-
如何解释文件与其对应的控制器类之间的关系
-
我想把DStream发送到Kafka,但它仍然不起作用。 以下是一些错误信息: 16/10/31 14:44:15错误StreamingContext:错误启动上下文,将其标记为停止java.io.NotSerializableException:DStream检查点已启用,但DStreams及其功能不可序列化spider.app.job.MeetMonitor序列化堆栈:-对象不可序列化(类:s