
时间序列及其可视化

我有25万个这样的事件:
Slot Anzahl Nutzung TimeSlotNr WochenSlots Tag
1 2011-01-01 00:00:00 2 Firma 1 242 1
2 2011-01-01 00:00:00 50 Privat 1 242 1
3 2011-01-01 00:30:00 1 Firma 2 243 1
4 2011-01-01 00:30:00 49 Privat 2 243 1
5 2011-01-01 01:00:00 1 Firma 3 244 1
6 2011-01-01 01:00:00 48 Privat 3 244 1
一个时间段代表半个30分钟,“Anzahl”是一个时间段中的事件数,第一个时间段从2011-01-01 00:00:00开始,“WochenSlots”是时间段%%336,从周六00:00:00开始。所以我想在一周内看到分布情况。
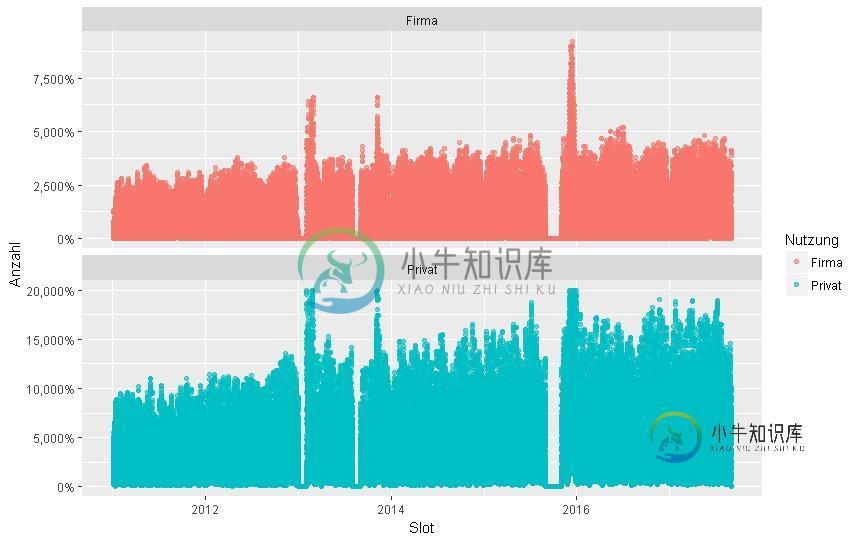

我现在想做的是:
- 以x标度显示日期(星期一00:00-星期日24:00)
- 显示显示x%事件分布的行(信封)。
我不知道该怎么做。
ggplot(data=PB2) +
geom_point(mapping = aes(x = WochenSlots, y = Anzahl, colour = Nutzung), alpha=0.6) +
scale_y_continuous(labels = scales::percent) +
facet_wrap(~Nutzung,
shrink = TRUE,
nrow = 2,
scales = "free_y")
dput(PB2[1:100,])结构(列表(槽=结构(c(1293840000, 1293840000, 1293841800, 1293841800, 1293843600, 1293843600, 1293845400, 1293845400, 1293847200, 1293847200, 1293849000, 1293849000, 1293850800, 1293850800, 1293852600, 1293852600, 1293854400, 1293854400, 1293856200, 1293856200, 1293858000, 1293858000, 1293859800, 1293859800, 1293861600, 1293861600, 1293863400, 1293863400, 1293865200, 1293865200, 1293867000, 1293867000, 1293868800, 1293868800, 1293870600, 1293870600, 1293872400, 1293872400, 1293874200, 1293874200, 1293876000, 1293876000, 1293877800, 1293877800, 1293879600, 1293879600, 1293881400, 1293881400, 1293883200, 1293883200, 1293885000, 1293885000, 1293886800, 1293886800, 1293888600, 1293888600, 1293890400, 1293890400, 1293892200, 1293892200, 1293894000, 1293894000, 1293895800, 1293895800, 1293897600, 1293897600, 1293899400, 1293899400, 1293901200, 1293901200, 1293903000, 1293903000, 1293904800, 1293904800, 1293906600, 1293906600, 1293908400, 1293908400, 1293910200, 1293910200, 1293912000, 1293912000, 1293913800, 1293913800, 1293915600, 1293915600, 1293917400, 1293917400, 1293919200, 1293919200, 1293921000, 1293921000, 1293922800, 1293922800, 1293924600, 1293924600, 1293926400, 1293926400, 1293928200, 1293928200),类=c(POSIXct,POSIXt),tzone=UTC),Anzahl=c(2L,50L,1L,49L,1L,48L,1L,43L,1L,43L,1L,30L,1L,27L,0L,22L,0L,19L,0L,20L,0L,18L,0L,17L,0L,17L,0L,0L,17L,0L,18L,0L,19L,2L,19L,2L,2L,2L,2L,21L,2L,2L,20L,2L,2L,18L,2L,22L,2L,24L,3L,25L,1L,28L,1L,30L,1L,33L,1L,32L,1L,28L,2L名称=c(插槽,Anzahl,Nutzung,TimeSlotNr,WoxenSlot,Tag),row.names=c(NA,100L),类=data.frame)
共有1个答案

看起来分位数回归可能就是你需要的。您发布的数据样本在每个时间点只有一个观察值,因此我创建了一些虚假数据以供说明。在下图中,我们使用一个灵活的样条函数作为回归函数,并在数据的第25和第75个百分位绘制回归线。让我知道这是否是你的想法。
library(ggplot2)
library(quantreg)
library(splines)
# Fake data
set.seed(2)
dat = data.frame(x=runif(1e4,0,20))
dat$y = cos(dat$x) + 10 + rnorm(1e4, 2)
ggplot(dat, aes(x,y)) +
geom_point(alpha=0.1, colour="blue", size=0.5) +
geom_quantile(formula=y ~ ns(x, 10), quantiles=c(0.25, 0.75),
colour="red", size=1) +
theme_classic()
-
时间序列可视化生成器 试验特性 时间序列可视化生成器是一个时间序列数据可视化工具,重点在于允许您使用 Elasticsearch 聚合框架的全部功能。时间序列可视化生成器允许您组合无限数量的聚合和管道聚合,以有意义的方式显示复杂的数据。 特色可视化编辑 时间序列可视化构建包含5种不同的可视化类型。您可以使用界面顶部的选项卡式选取器在每种可视化类型之间切换。 时间序列编辑 直方图可视化,支持具有多个
-
本文向大家介绍Python实现时间序列可视化的方法,包括了Python实现时间序列可视化的方法的使用技巧和注意事项,需要的朋友参考一下 时间序列数据在数据科学领域无处不在,在量化金融领域也十分常见,可以用于分析价格趋势,预测价格,探索价格行为等。 学会对时间序列数据进行可视化,能够帮助我们更加直观地探索时间序列数据,寻找其潜在的规律。 本文会利用Python中的matplotlib【1】库,并配合
-
我们已经在Highcharts Configuration Syntax一章中看到了用于绘制此图表的配置 。 现在让我们考虑以下示例来进一步理解时间序列,Zoomable Chart。 配置 (Configurations) 现在让我们讨论所采取的其他配置/步骤。 图表 配置图表以使其可缩放。 chart.zoomType通过拖动鼠标chart.zoomType决定用户可以缩放的尺寸。 可能的值是
-
以下是基于时间的数据图表的示例。 我们已经在Highcharts Configuration Syntax一章中看到了用于绘制图表的配置 。 现在,我们将讨论基于时间的数据图表的示例。 配置 (Configurations) 现在让我们讨论所采取的其他配置/步骤。 图表 配置图表以使其可缩放。 chart.zoomType通过拖动鼠标chart.zoomType决定用户可以缩放的尺寸。 可能的值是
-
免责声明:刚刚开始和斯巴克玩。 我很难理解著名的“任务不可序列化”异常,但我的问题与我在SO上看到的问题有点不同(或者我认为是这样)。 我有一个很小的自定义RDD()。它有一个字段,用于存储类不实现序列化的对象()。我已经设置了spark.serializer配置选项来使用Kryo。但是,当我在我的RDD上尝试时,我得到了以下结果: 当我往里面看的时候。submitMissingTasks我看到它
-
Highcharts 曲线图 以下实例演示了基于时间的曲线图表。 我们在前面的章节已经了解了 Highcharts 配置语法。接下来让我们来看个完整实例: 配置 图表 配置可缩放图表。 chart.zoomType 指定了用户可以拖放的尺寸,用户可以通过拖动鼠标来放大,可能值是x,y或xy: var chart = { zoomType: 'x' }; plotOptions 使用 pl