
Cerebras GPT 是由 Cerebras 公司开源的自然语言处理领域的预训练大模型,其模型参数规模最小 1.11 亿,最大 130 亿,共 7 个模型。
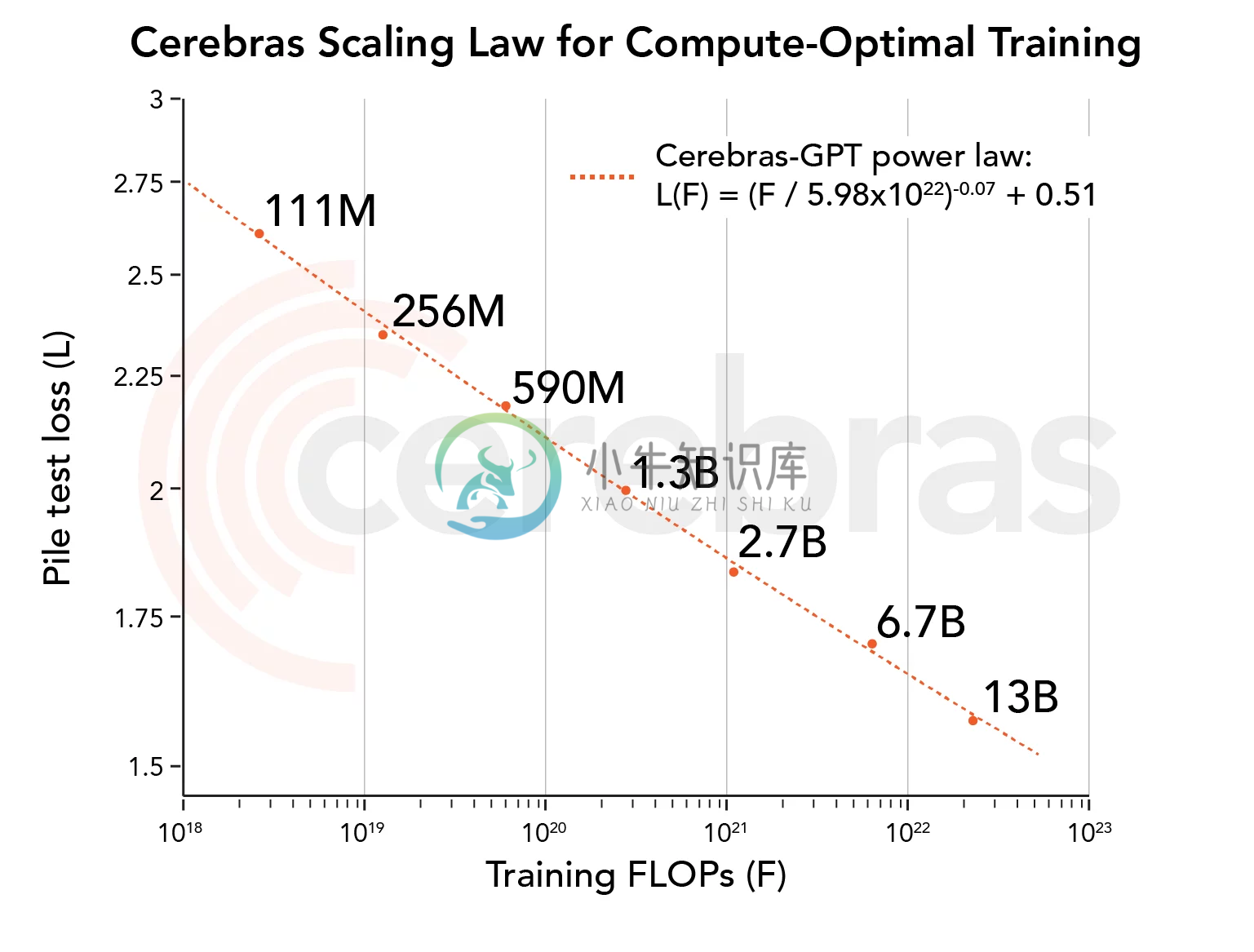
与业界的模型相比,Cerebras-GPT几乎是各个方面完全公开,没有任何限制。不管是模型架构,还是预训练结果都是公开的。目前开源的模型结构和具体训练细节如下:

-
主要内容 前言 课程列表 推荐学习路线 数学基础初级 程序语言能力 机器学习简介 自然语言学习初级 数学和机器学习知识补充 自然语言处理中级 自然语言处理专项领域学习 前言 我们要求把这些课程的所有Notes,Slides以及作者强烈推荐的论文看懂看明白,并完成所有的老师布置的习题,而推荐的书籍是不做要求的,如果有些书籍是需要看完的,我们会进行额外的说明。 课程列表 课程 机构 参考书 Notes
-
知识图谱 接口: nlp_ownthink 目标地址: https://ownthink.com/ 描述: 获取思知-知识图谱的接口, 以此来查询知识图谱数据 限量: 单次返回查询的数据结果 输入参数 名称 类型 必选 描述 word str Y word="人工智能" indicator str Y indicator="entity"; Please refer Indicator Info
-
PyTorch 自然语言处理(Natural Language Processing with PyTorch 中文版)
-
这是一本关于自然语言处理的书。所谓“自然语言”,是指人们日常交流使用的语言,如英语,印地语,葡萄牙语等。
-
自然语言处理怎么学? 先学会倒着学,倒回去看上面那句话:不管三七二十一先用起来,然后再系统地学习 nltk是最经典的自然语言处理的python库,不知道怎么用的看前几篇文章吧,先把它用起来,最起码做出来一个词性标注的小工具 自然语言处理学什么? 这门学科的知识可是相当的广泛,广泛到你不需要掌握任何知识就可以直接学,因为你不可能掌握它依赖的全部知识,所以就直接冲过去吧。。。 话说回来,它到底包括哪些
-
自然语言处理之序列模型 - 小象学院 解决 NLP 问题的一般思路 这个问题人类可以做好么? - 可以 -> 记录自己的思路 -> 设计流程让机器完成你的思路 - 很难 -> 尝试从计算机的角度来思考问题 NLP 的历史进程 规则系统 正则表达式/自动机 规则是固定的 搜索引擎 “豆瓣酱用英语怎么说?” 规则:“xx用英语怎么说?” => translate(XX, English)