
这是 A2O POWER 处理器核心 RTL 和相关的 FPGA 实现(使用 ADM-PCIE-9V3 FPGA)的发布。
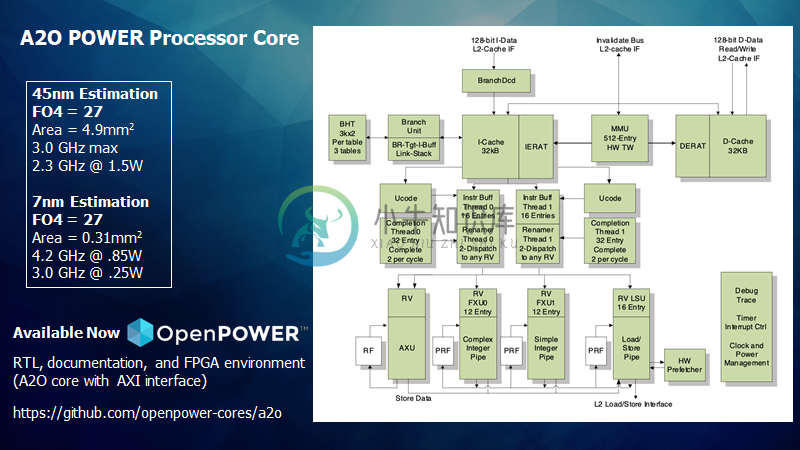
A2O 核心是为了优化单线程性能而诞生的,目标是 45nm 技术的 3+GHz。它是一个 27 FO4 的实现,有一个支持 1 或 2 个线程的外序管道。它完全支持使用 Book III-E 的 Power ISA 2.07。该内核还被设计成支持 MMU 和 AXU 逻辑宏的可插拔实现。这包括取消 MMU 和使用 ERAT-only 模式进行翻译/保护。
A2O设计是A2I的后续设计,用Verilog编写,支持的线程数比A2I少,但每个线程的性能更高,使用了无序执行(寄存器重命名、保留站、完成缓冲区)和存储队列。两个核心的A2L2外部接口基本相同。

FPGA Implementation Notes
- 有许多旋钮可用于调整生成参数。很少做实验来测试它们是否有效,或者对面积的影响等等。
- 到目前为止,仅完成了单线程生成。使用中的FPGA,一个线程的利用率非常高。
- A2I使用clk_1x和clk_2x(对于某些特殊数组),但是A2O也使用clk_4x。这(可能还伴随着区域拥塞)导致将clk_1x更改为50MHz,以减轻时序压力(建立和保持未命中)。
-
【问题描述】 设带头结点的单链表表示的线性表L=(a1,a2,a3,a4,……,an),试用复杂度为O(n)的算法,原地将L改造为L=(a1,a3, ……,a2,a4, ……)。 【输入形式】 第一行输入单链表元素个数n; 第二行输入n个整数。 【输出形式】 输出改造后的单链表。 【样例输入】 9 1 2 3 4 5 6 7 8 9 【样例输出】 1 3 5 7 9 2 4 6 8 【测试代码】
-
首先你得有一个模板,通过python脚本打开编译后的.map文件自动填写到A2L文件对应位置,目前只实现了填写Mesurement 区域,但是这个填写主要是更新变量名和对应的ECU ADRRESS,因为.map文件不包含更多的信息。 首先你得对你得MCU(我的是基于MPC5744)内存进行分区,修改S32DS中的链接脚本(该脚本为GCC格式,与Keil不同),在.sdata后添加这样一个段 .s
-
[求助]Texlive镜像安装失败【latex吧】_百度贴吧 手贱起中文名,眼泪都要掉下来了
-
《台达A2与B2伺服的区别》由会员分享,可在线阅读,更多相关《台达A2与B2伺服的区别(2页珍藏版)》请在人人文库网上搜索。 1、A2和B2的电机型号都以ASD开头 A2和B2的电机的安装尺寸是一样的 A2和B2的CN接头是不一样的。A2系列的型号如下:1.5KW伺服电机(2000r/min ,不带刹车,带M6螺纹孔,带键槽)ECMA-E11315RS1.5KW伺服驱动器ASD-A2-1521-M
-
将头指针赋给指针变量 q=L; 将头指针下一个变量赋给另一个指针变量 p=L->next; 开始单链表头插法过程 p->next=q->next; q->next=p; p=k->next; void Reverser(LinkList *L){ LinkList *p,*q; p=L->next; q=L; L->next=null; if(p==null) exit(1); while(p!
-
求和 问题描述 给定 n 个整数 a1, a2, · · · , an ,求它们两两相乘再相加的和,即: S=a1·a2+a1·a3+···+a1·an+a2·a3+···+an-2·an+an-1·an 输入格式 输入的第一行包含一个整数 n。 第二行包含 n 个整数a1, a2, · · · , an 输出格式 输出一个整数 S,表示所求的和。请使用合适的数据类型进行运算。 样例输入 4 1
-
#include<stdio.h> typedef int ElemType; typedef struct DuLNode{ ElemType data; struct DuLNode *prior; struct DuLNode *next; } DuLNode, *DuLinkList; DuLinkList InitDuLinkList();//初始化双向循环链表(头节点) voi
-
void DoubleLink::op() { cout << "进行操作……" << endl; Node *p1, *p2, *p4; p1 = phead->pre;//初始化为an,指向当前最后一个元素 if (count % 2 == 0) p2 = p1->pre->pre; else p2 = p1->pre; do { //建立待处理偶数am和当前最后一个
-
问题内容: 我知道,现在大多数处理器都有两个或多个内核,因此多核编程非常流行。有在Java中利用此功能的功能吗?我知道Java有一个Thread类,但是我也知道这是在多核流行之前的很长时间了。如果我可以使用Java中的多个内核,我将使用什么类/技术? 问题答案: Java是否支持多核处理器/并行处理? 是。它还是其他编程语言的平台,在该平台上,实现增加了“真正的多线程”或“真正的线程”卖点。在较新
-
问题内容: 我一直在阅读有关Python的多处理模块的信息。我仍然认为我对它可以做什么没有很好的了解。 假设我有一个四核处理器,并且我有一个包含1000000个整数的列表,我想要所有整数的总和。我可以简单地做: 但这仅将其发送到一个内核。 是否有可能使用多处理模块将数组划分为多个,并让每个核获得其部分的总和并返回值,以便可以计算总和? 就像是: 任何帮助,将不胜感激。 问题答案: 是的,可以对多个
-
问题内容: 我正在运行以下命令来获取Linux中的处理器/内核数: 它可以工作,但看起来并不优雅。您如何建议改善它? 问题答案: 是您要寻找的。 此处更多信息:http : //www.cyberciti.biz/faq/linux-get-number-of-cpus-core- command/
-
但这无济于事,仍然令人崩溃。 我在考虑make try{}catch返回500,并在每个过滤器中进行某种日志记录,但这将导致大量的重复。 有什么办法可以在全球范围内处理吗? MVC服务的添加方式如下:
-
问题内容: 如果在多处理器或多处理器计算机上运行,而jvm可能绝对同时运行多个线程(不只是同时出现),那么api方法返回什么?…在上述情况下,它是否会返回当前线程之一是随机的吗? 问题答案: 它返回您当前正在其中运行的线程。如果你有两个核心和两个线程和完全并行运行,要求在同一时间这个方法,它将返回和适当的。 您的理解是正确的-此方法返回的线程始终处于运行状态-因为必须从某个线程调用该线程,
-
问题内容: 我使用具有八个核心的台式机(通过javac目标)使用Ant构建Java应用程序。有没有一种方法可以通过使用多个线程或进程来加快编译速度? 我知道我可以并行运行多个Ant任务,但是我认为这不能应用于单个编译目标,还是可以吗? 问题答案: 我不知道有什么方法可以告诉蚂蚁本身有效利用多个内核。但是您可以告诉ant使用Eclipse Compiler ,它支持内置的多线程编译。
-
数据解析为模型后,下面的任务就是交给处理器做处理。 当然你也可以不编写处理器,使用内置的处理器。 示例 实现Yurun\Crawler\Module\Processor\Contract\IProcessor接口 <?php namespace Yurun\CrawlerApp\Module\YurunBlog\Article; use Imi\App; use Imi\Log\Log; use
-
问题内容: 许多次我听说最好将线程池中的线程数保持在该系统中的内核数以下。具有比核心数多两倍或更多的线程不仅浪费,而且还可能导致性能下降。 那些是真的吗?如果不是,那么揭露这些主张的基本原则是什么(特别是与Java有关)? 问题答案: 许多次我听说最好将线程池中的线程数保持在该系统中的内核数以下。具有比核心数多两倍或更多的线程不仅浪费,而且还可能导致性能下降。 这些主张 作为一般性陈述 是不正确的