
Big Whale 巨鲸任务调度平台为美柚大数据研发的分布式计算任务调度系统,提供 Spark、Flink 等批处理任务的 DAG 调度和流处理任务的运行管理和状态监控,并具有Yarn应用管理、重复应用检测、大内存应用检测等功能。 服务基于 Spring Boot 2.0 开发,打包后即可运行。
概述
1.架构图
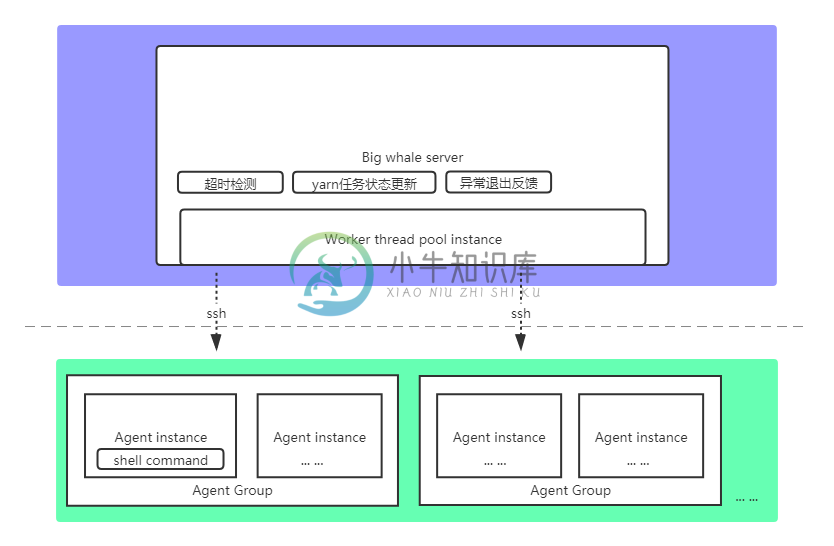
2.特性
- 基于SSH的脚本执行机制,部署简单快捷,仅需单个服务
- 基于Yarn Rest Api的任务状态同步机制,对Spark、Flink无版本限制
- 支持失败重试
- 支持任务依赖
- 支持复杂任务编排(DAG)
- 支持流处理任务运行管理和监控
- 支持Yarn应用管理
部署
1.准备
- Java 1.8+
- Mysql 5.1.0+
- 下载项目或git clone项目
- 为解决 github README.md 图片无法正常加载的问题,请在hosts文件中加入相关域名解析规则,参考:hosts
2.安装
- 创建数据库:big-whale
- 运行数据库脚本:big-whale.sql
- 根据Spring Boot环境,配置相关数据库账号密码,以及SMTP信息
- 配置:big-whale.properties
- 配置项说明
- ssh.user: 拥有脚本执行权限的ssh远程登录用户名(平台会将该用户作为统一的脚本执行用户)
- ssh.password: ssh远程登录用户密码
- dingding.enabled: 是否开启钉钉告警
- dingding.watcher-token: 钉钉公共群机器人Token
- yarn.app-memory-threshold: Yarn应用内存上限(单位:MB),-1禁用检测
- yarn.app-white-list: Yarn应用白名单列表(列表中的应用申请的内存超过上限,不会进行告警)
- 配置项说明
- 修改:$FLINK_HOME/bin/flink,参考:flink(因flink提交任务时只能读取本地jar包,故需要在执行提交命令时从hdfs上下载jar包并替换脚本中的jar包路径参数)
- 打包:mvn clean package
3.启动
- 检查端口17070是否被占用,被占用的话,关闭占用的进程或修改项目端口号配置重新打包
- 拷贝target目录下的big-whale.jar,执行命令:java -jar big-whale.jar
4.初始配置
- 打开:http://localhost:17070
- 输入账号admin,密码admin
- 点击:权限管理->用户管理,修改当前账号的邮箱为合法且存在的邮箱地址,否则会导致邮件发送失败
- 添加集群
- 集群管理->集群管理->新增
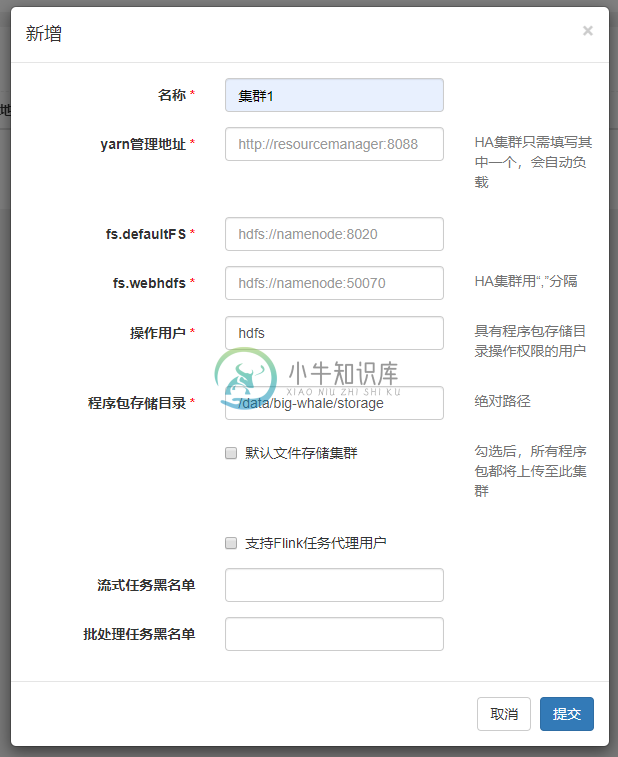
- “yarn管理地址”为Yarn ResourceManager的WEB UI地址
- “程序包存储目录”为程序包上传至hdfs集群时的存储路径,如:/data/big-whale/storage
- “支持Flink任务代理用户”“流处理任务黑名单”和“批处理任务黑名单”为内部定制的任务分配规则,勿填
- 集群管理->集群管理->新增
- 添加集群用户
- 集群管理->集群用户->新增
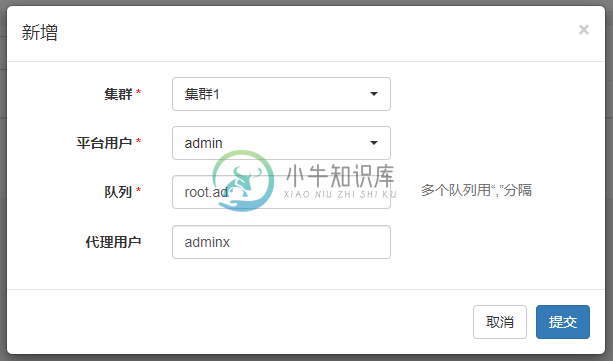
- 该配置的语义为:平台用户在所选集群下可以使用的Yarn资源队列(--queue)和代理用户(--proxy-user)
- 集群管理->集群用户->新增
- 添加代理
- 集群管理->代理管理->新增
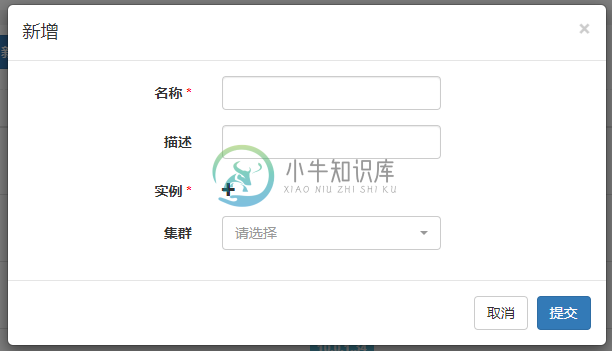
- 可添加多个实例(仅支持IP地址,可指定端口号,默认为22),执行脚本的时候会随机选择一个实例执行,在实例不可达的情况下,会继续随机选择下一个实例,在实例均不可达时执行失败
- 选择集群后,会作为该集群下提交Spark或Flink任务的代理之一
- 集群管理->代理管理->新增
- 添加计算框架版本
- 集群管理->版本管理->新增
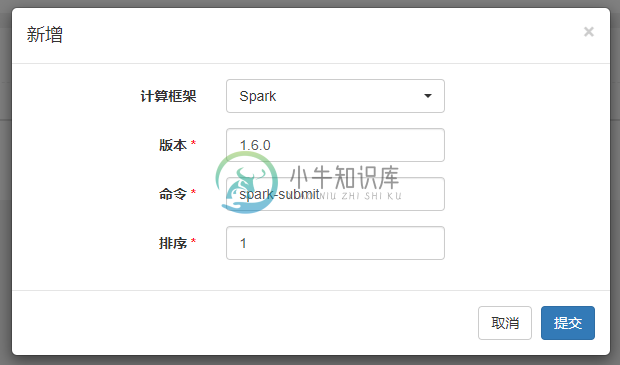
- 同一集群下不同版本的Spark或Flink任务的提交命令可能有所不同,如Spark 1.6.0版本的提交命令为spark-submit,Spark 2.1.0版本的提交命令为spark2-submit
- 集群管理->版本管理->新增
使用
1.离线调度
1.1 新增
- 目前支持“Shell”、“Spark Batch”和“Flink Batch”三种类型的批处理任务
- 通过拖拽左侧工具栏相应的批处理任务图标,可添加相应的DAG节点
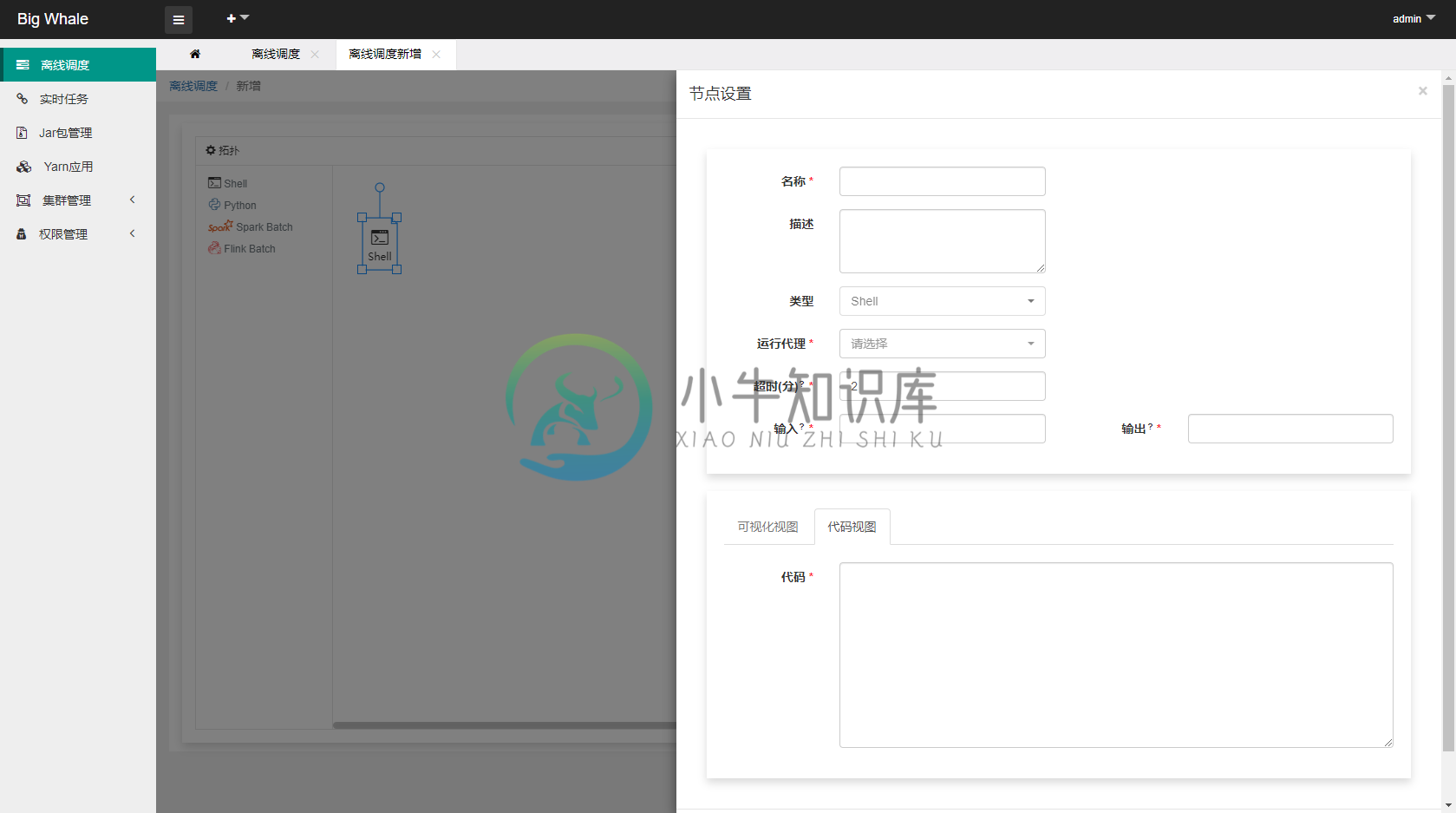
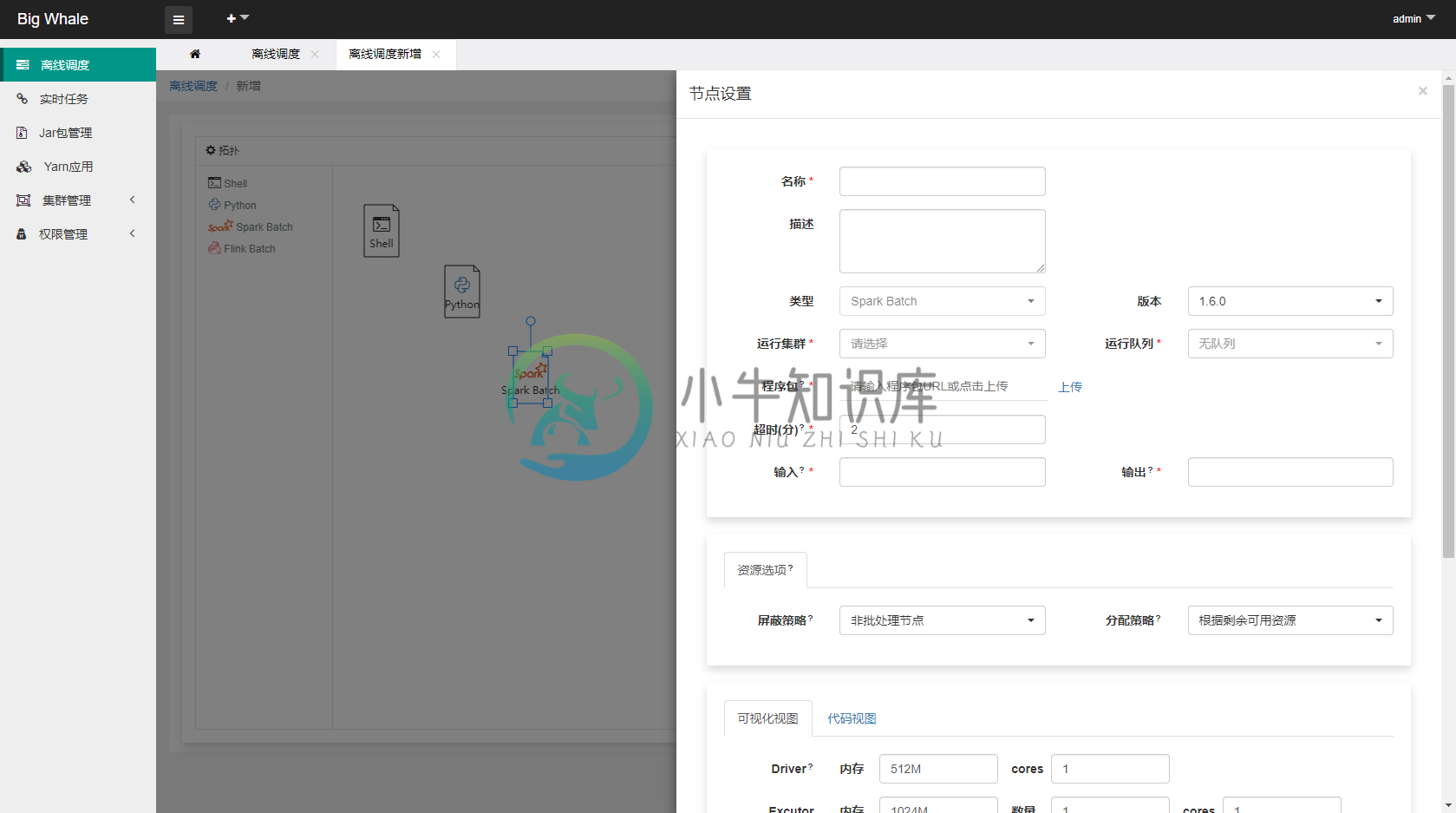
- 支持时间参数
${now} ${now - 1d} ${now - 1h@yyyyMMddHHmmss}等(d天、h时、m分、s秒、@yyyyMMddHHmmss为格式化参数) - 非“Shell”类型的批处理任务应上传与之处理类型相对应的程序包,此处为Spark批处理任务打成的jar包
- “资源选项”可不填
- 代码有两种编辑模式,“可视化视图”和“代码视图”,可互相切换
- 点击“测试”可测试当前节点是否正确配置并可以正常运行
- 为防止平台线程被大量占用,平台提交Saprk或Flink任务的时候都会强制以“后台”的方式执行,对应spark配置:--conf spark.yarn.submit.waitAppCompletion=false,flink配置:-d,但是基于后台“作业状态更新任务”的回调,在实现DAG执行引擎时可以确保当前节点所提交的任务运行完成后再执行下一个节点的任务
- 支持时间参数
- DAG节点支持失败重试
- 将节点按照一定的顺序连接起来可以构建一个完整的DAG
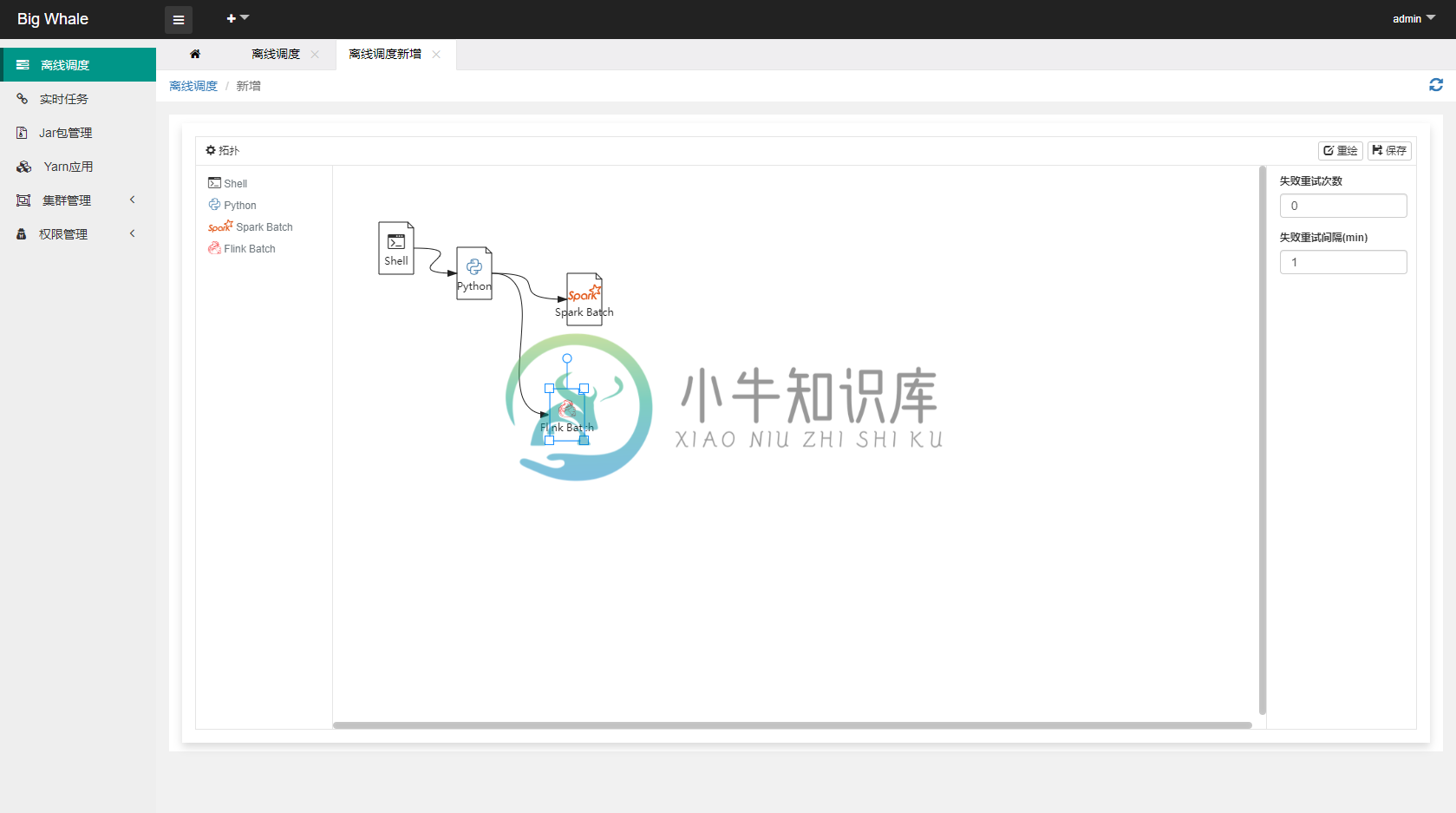
- DAG构建完成后,点击“保存”,完成调度设置
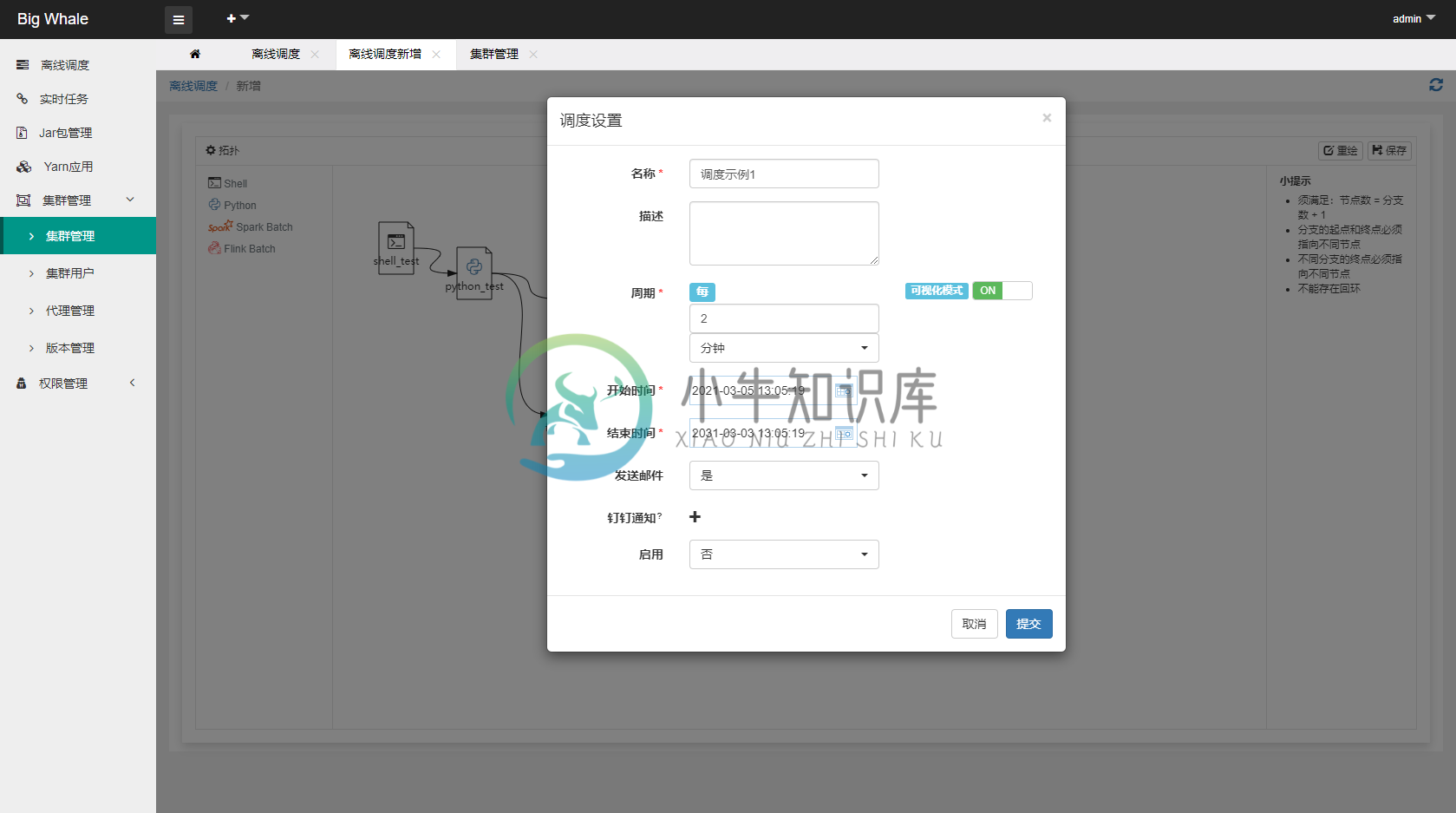
1.2 操作
- 打开离线调度列表
-
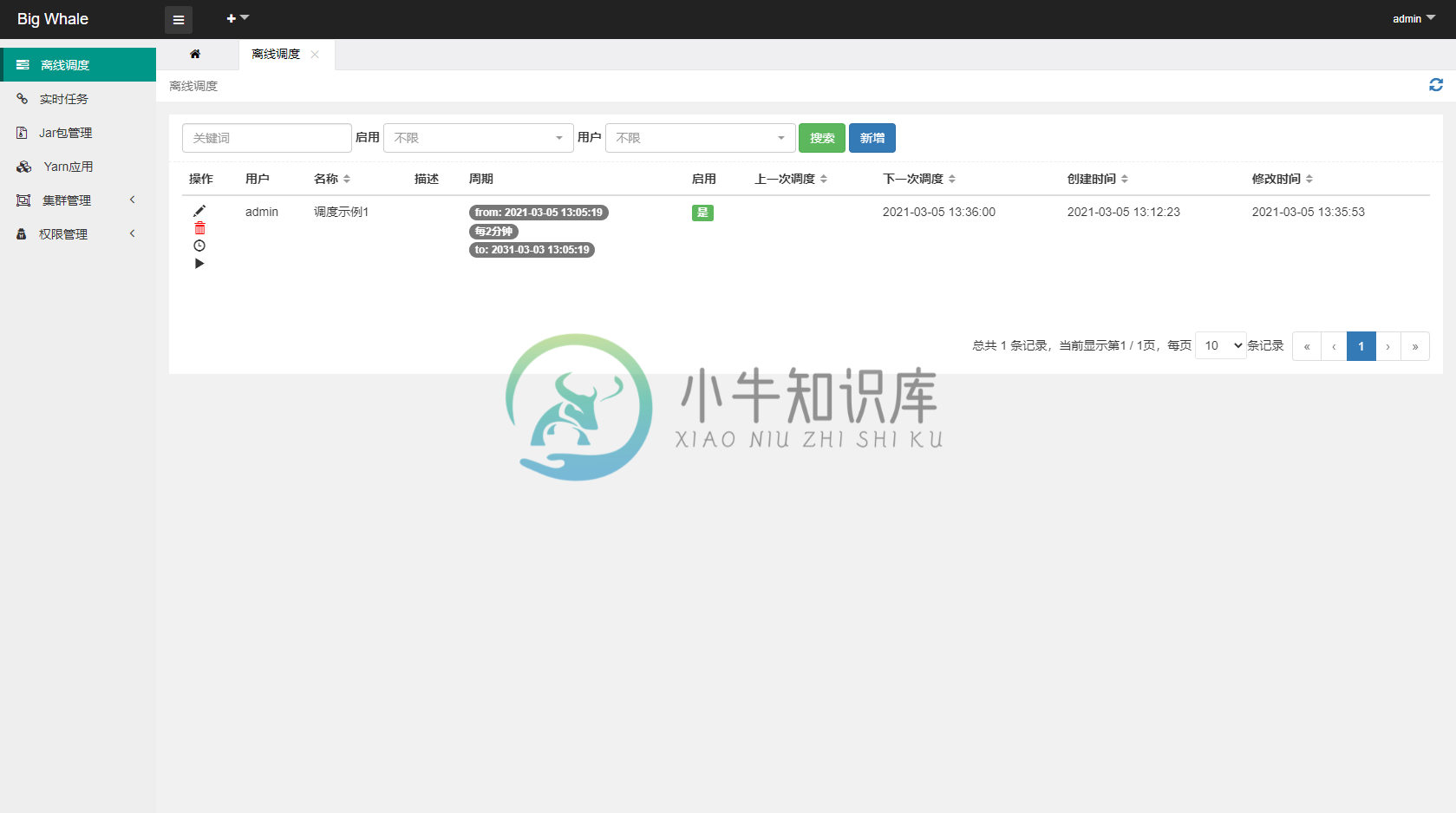
- 点击左侧操作栏“调度实例”可查看调度实例列表、运行状态和节点启动日志
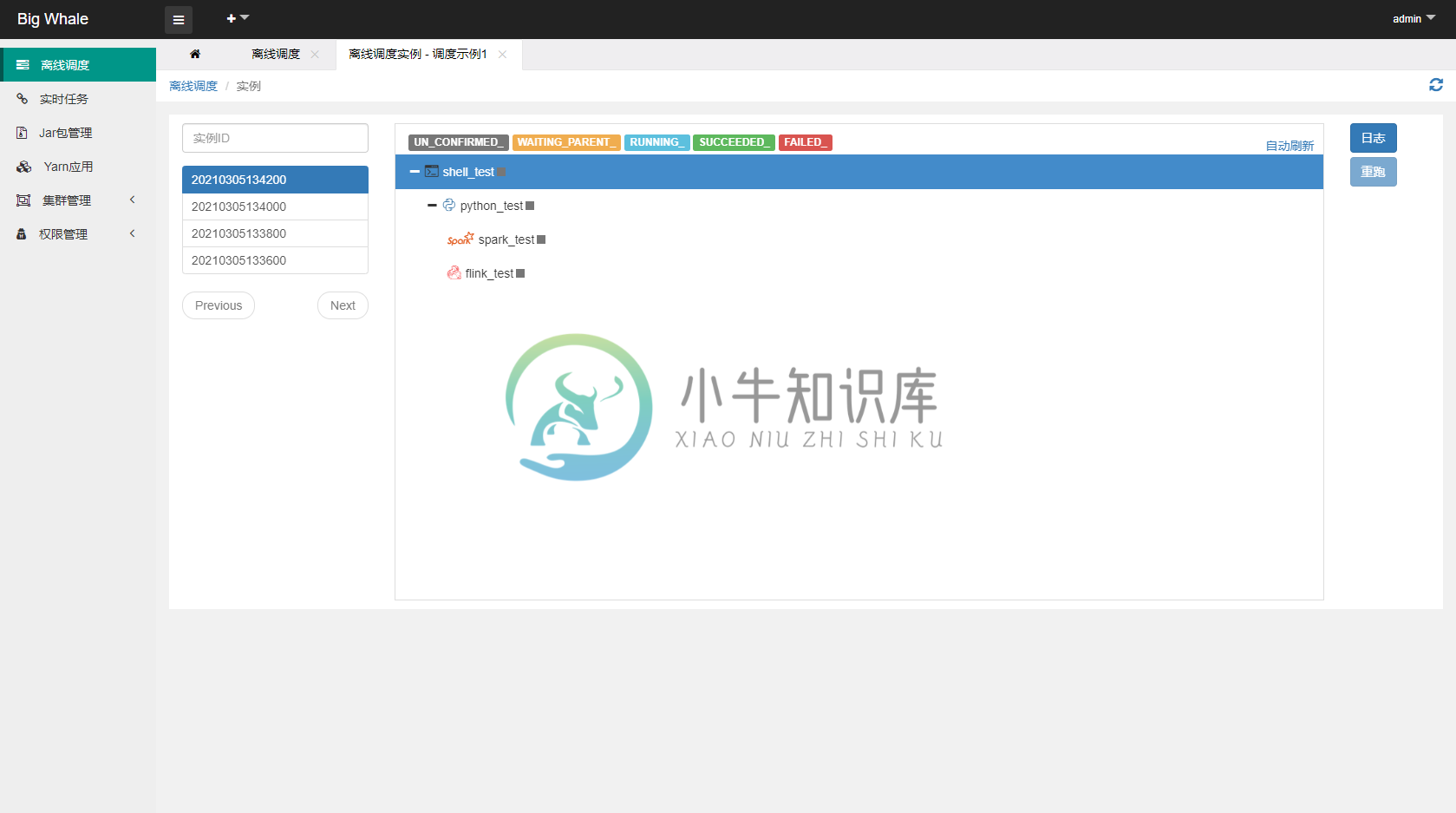
- 点击左侧操作栏“手动执行”可触发调度执行
2.实时任务
2.1 新增
- 目前支持“Spark Stream”和“Flink Stream”两种类型的流处理任务
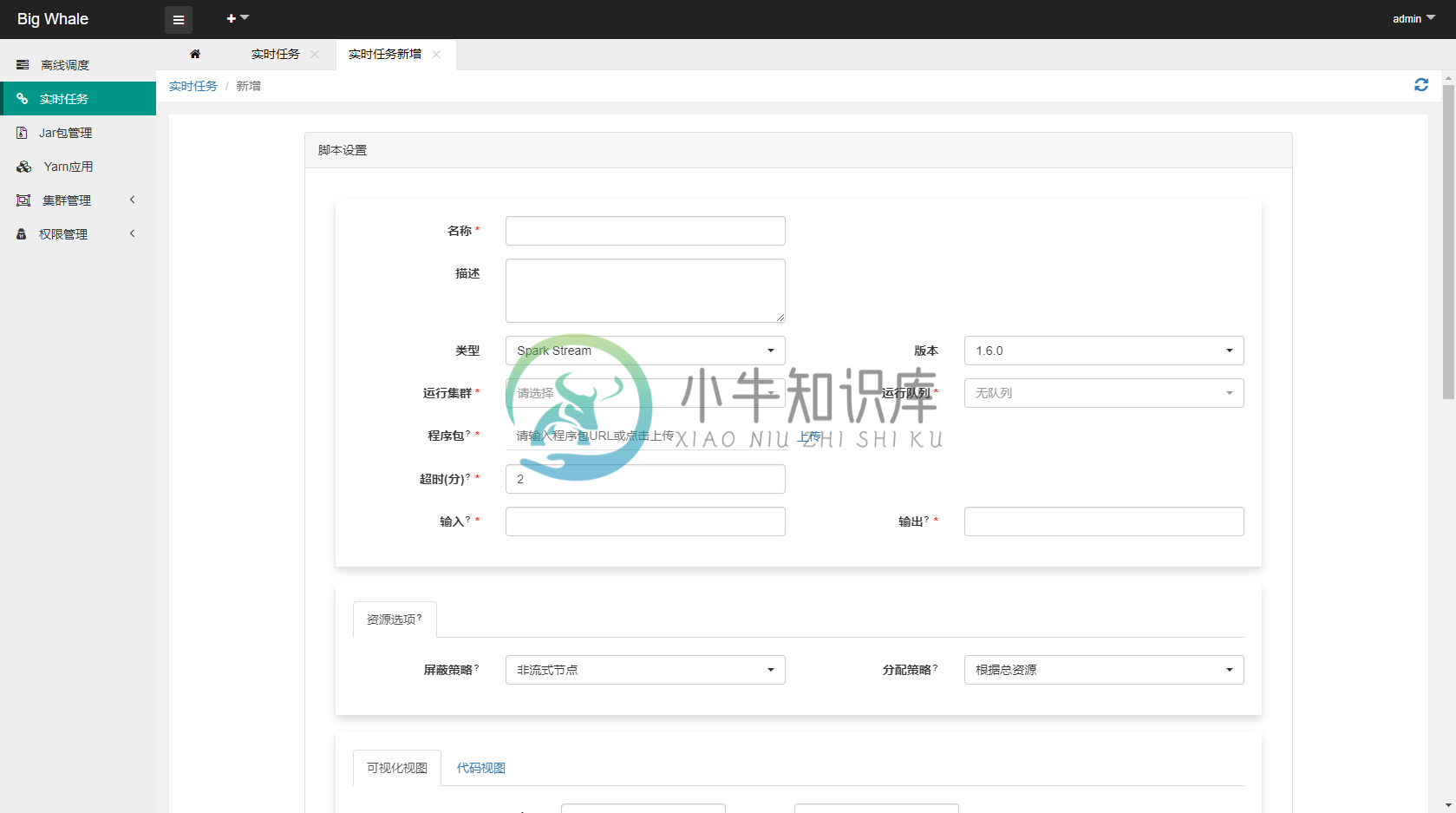
- 启用监控可以对任务进行状态监控,包括异常重启、批次积压告警等
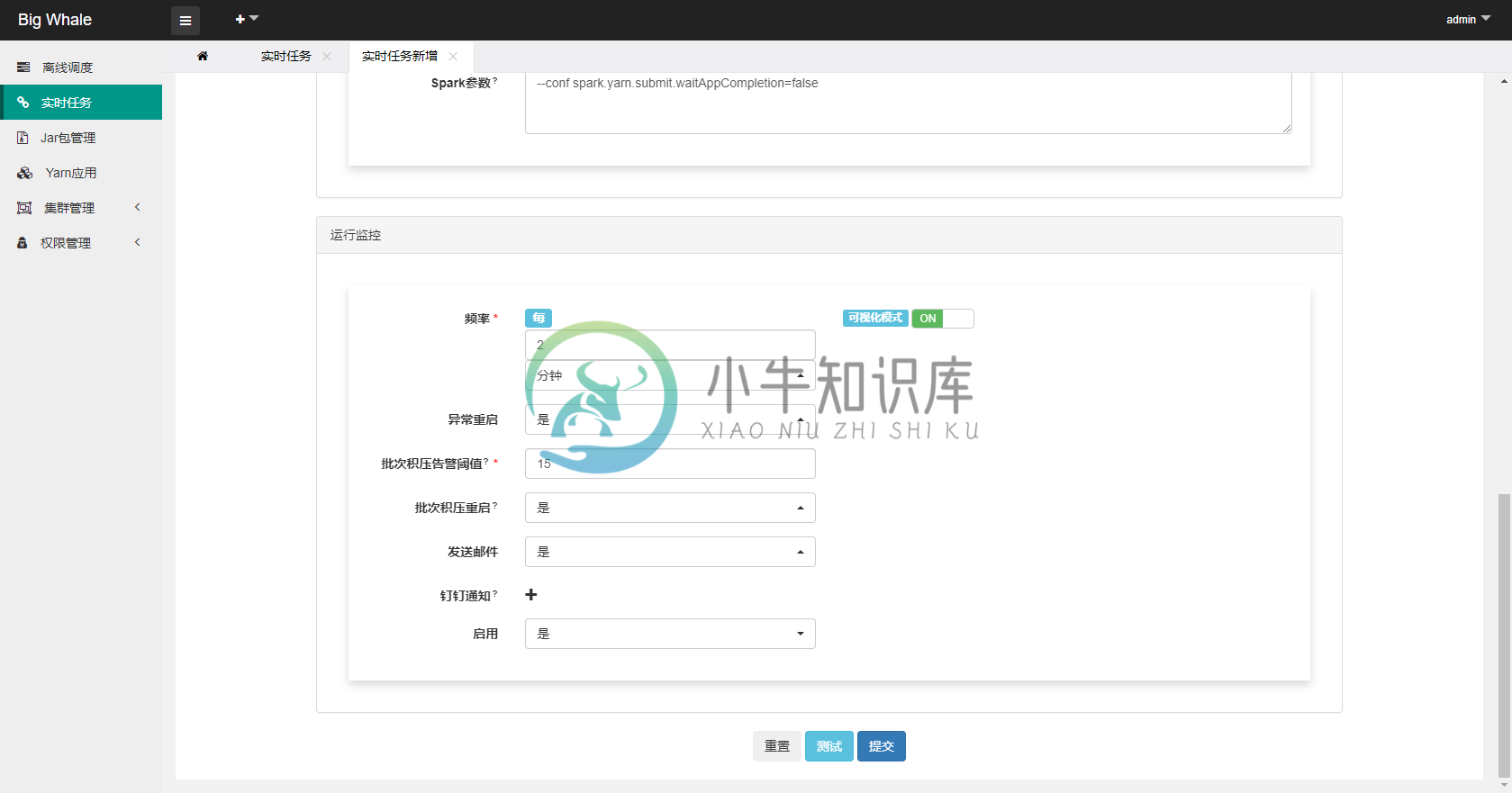
2.2 操作
- 打开实时任务列表
-
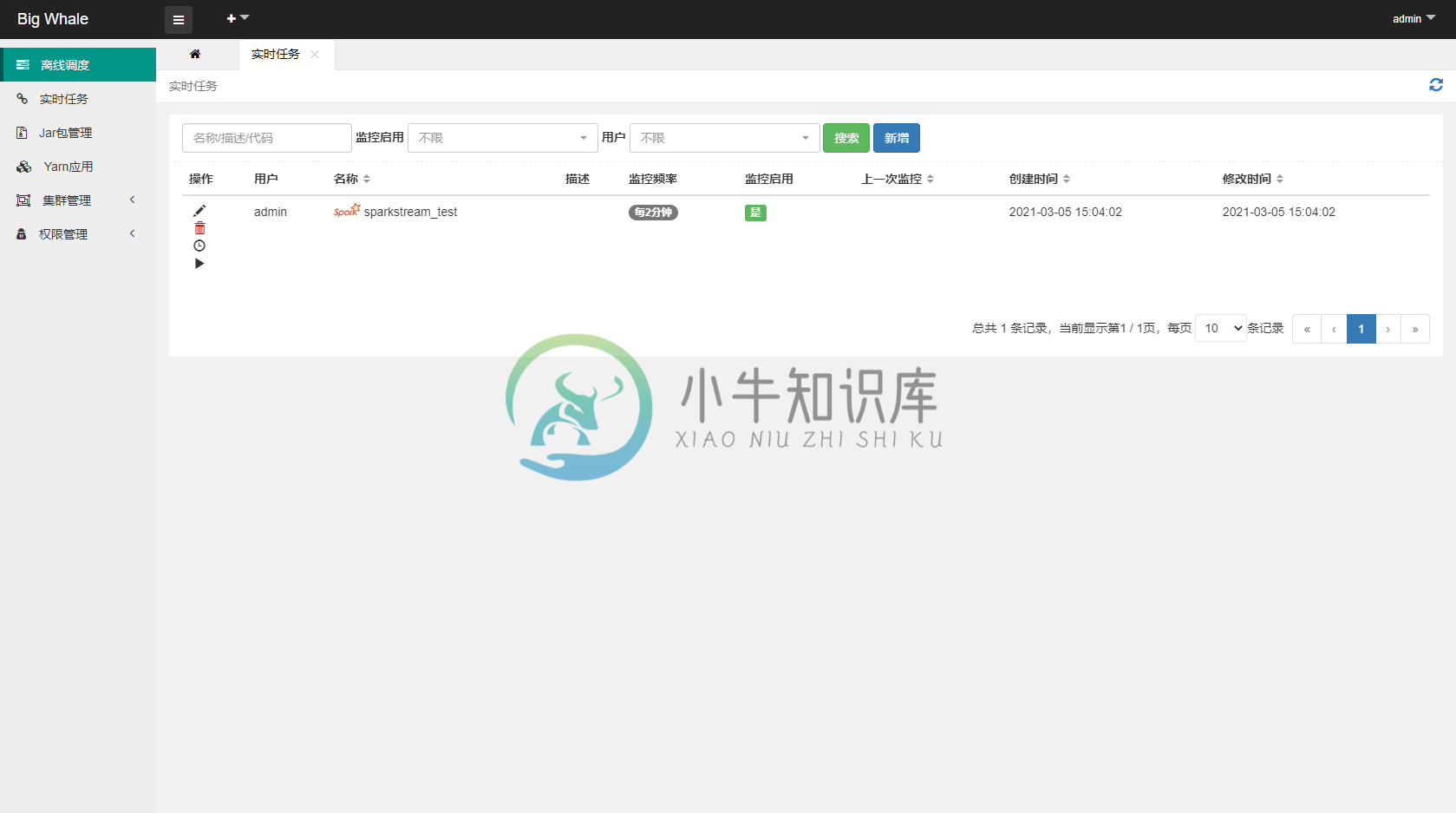
- 点击左侧操作栏“日志”可查看任务启动日志
- 点击左侧操作栏“执行”可触发任务启动
3.任务告警
- 正确配置邮件或钉钉告警后在任务运行异常时会发送相应的告警邮件或通知,以便及时进行相应的处理
<巨鲸任务告警> 代理: agent1 类型: 脚本执行失败 用户: admin 任务: 调度示例1 - shell_test 时间: 2021-03-05 15:18:23
<巨鲸任务告警> 集群: 集群1 类型: spark离线任务异常(FAILED) 用户: admin 任务: 调度示例1 - spark_test 时间: 2021-03-05 15:28:33
<巨鲸任务告警> 集群: 集群1 类型: spark实时任务批次积压,已重启 用户: admin 任务: sparkstream_test 时间: 2021-03-05 15:30:41
- 除上述告警信息外还有其他告警信息此处不一一列举
Change log
- v1.1开始支持DAG
- v1.2开始支持DAG节点失败重试
- v1.3调度引擎进行重构升级,不支持从旧版本升级上来,原有旧版本的任务请手动进行迁移,离线调度移除“Python”类型脚本支持
-
whale 帷幄是面向未来的营销运营平台,全域数字化撬动品牌持续增长,让品牌更懂客户 whale 帷幄为品牌创造真实价值 数字品牌运营力 规模线下数字化,加速全域商业空间智能化转型 One-ID 技术为消费者打造线上线下无缝衔接的购物体验 数字化营销内容集中管理与在线协作 基于品牌业务逻辑的全域数据分析,最大化释放空间数据价值 集成 AIoT 技术与数据能力助力门店运营分析,提升业绩增长 私域用户
-
Saas平台是运营saas软件的平台。SaaS提供商为企业搭建信息化所需要的所有网络基础设施及软件、硬件运作平台,并负责所有前期的实施、后期的维护等一系列服务,企业无需购买软硬件、建设机房、招聘IT人员,即可通过互联网使用信息系统。 SaaS 是一种软件布局模型,其应用专为网络交付而设计,便于用户通过互联网托管、部署及接入。 营销云是一套面向营销的、基于SaaS的解决方案,其中包含多种营销技术能力
-
一、长宽表的变形 长表和宽表是对于某一个特征而言的,例如一个表中把性别存储在某一个列中,那么它就是关于性别的长表;如果把性别作为列名,列中的元素是某一其他的相关特征数值,那么这个表是关于性别的宽表。 import pandas as pd import numpy as np df=pd.DataFrame({'Gender':['F','F','M','M','F','F'],
-
一、索引 Python和NumPy索引运算符"[]“和属性运算符”."可以快速轻松地访问Pandas数据结构。由于要访问的数据类型不是预先知道的,直接使用标准运算符具有一些限制。 序号 索引 描述 1 .loc() 基于标签 2 .iloc() 基于整数 1.1、.loc() .loc()主要基于标签(label)的,包括行标签(index)和列标签(colums),即行名称和列名称,可以使用de
-
Whale 帷幄是国内专业的全域数字化营销运营平台。自 2017 年成立至今,Whale 帷幄深耕新零售、新消费、DTC 及新锐品牌领域,以“让品牌更懂客户”为使命,致力于通过人工智能 (AI), 大规模物联网络 (IoT) 和数据模型 (Data) 的关键技术创新,为面向未来的零售品牌提供数据驱动、协作优先、简单易部署的品牌全域营销运营平台及数字化转型解决方案。 凭借多年来沉淀的大量行业最佳实践
-
车企 x Whale 帷幄|经销商管理体系的数字化转型升级 对于汽车行业来说,实现经销商管理体系的数字化转型升级,提升经销商门店全流程数字化管理效率已是大势所趋。 但如何获取各大经销商门店的实时数据并监控,通过数据平台实现品牌与经销商门店之间的信息共享是整个系统开发的挑战,同时对设计者的车辆识别算法开发能力也是一项考验。 在这样的市场背景下,具有非常强大的数据算法开发团队和开发能力的 Whale
-
某国货美妆 x Whale 帷幄|同解锁抖音赛道的品牌「流量密码」 随着颜值经济、颜值社交的爆发,以抖音为代表的短视频领域,已经成为面向千禧一代种草的品牌营销及转化销售的重要战场。抖音短视频自然成为各大美容博主用户的关注焦点,也因此抖音成为不少化妆品品牌的必争之地。 B 美妆品牌非常注重抖音品牌直播间这个销售渠道。B 美妆品牌希望通过科学方法来对主播以及直播间可运营的变量因素与实际销售数据之间的相
-
什么是数据中台 数据中台是全新的架构变革。过去三十年,企业数据管理都以传统的IT架构为基础。每当技术部门为业务部门解决问题时,需要从业务需求的探查、技术壁垒的打通等从上到下各个方面来建设新系统。每个系统的建成都自成一体,各自满足业务部门的需求。这种情况不仅耗费各部门大量的精力也使得各个系统难以打通管理,无法形成更强大的数据能力。 如果以通俗化的生活案例来解说的话,数据中台的工作原理如同五星级饭店为
-
车企 x Whale 帷幄|经销商管理体系的数字化转型升级 对于汽车行业来说,实现经销商管理体系的数字化转型升级,提升经销商门店全流程数字化管理效率已是大势所趋。 但如何获取各大经销商门店的实时数据并监控,通过数据平台实现品牌与经销商门店之间的信息共享是整个系统开发的挑战,同时对设计者的车辆识别算法开发能力也是一项考验。 在这样的市场背景下,具有非常强大的数据算法开发团队和开发能力的 Whale
-
W 大健康品牌 x 帷幄 | 强化门店数据管控,有力降本增效 随着中国经济的快速增长,新兴消费力量开始对中国的整体商业格局产生重大影响,庞大的年轻消费者为健康消费带来了新的增长点。在数字化如火如荼的时候,线下门店作为与消费者接触最为直观、有温度的渠道从未被品牌放弃。 以科技创新促进大健康产业高质量发展的 W 品牌,在国内拥有 1 个全球体验中心、全国 30 家服务/体验中心、7000 多家专卖店/
-
L 品牌 x Whale 帷幄|门店数据管控 随着中国经济的发展,休闲零食已从可选消费品,变为大众、高频的必需消费品,市场规模过万亿。作为休闲零食行业的全能选手,L 品牌是一家线上线上均衡发展的企业。伴随 L 品牌加大对其线下门店的布局,线下门店的数字化转型升级,提升门店数字化管理效率已是大势所趋。 但如何获取线下门店的实时客流数据并进行分析,通过数据平台实现顾客门店行为数据分析和门店运营数据相关
-
说起营销云是什么,首先感觉它的定义一直都在随着应用发展与时俱进的朝着更细致的方向变化着,而立足当下,我们来说说此刻对它的定义。 营销云,在我们的理解就是基于云计算和Martech技术的中台系统,是市场营销人员可以使用到的技术和产品的集合的中台系统,其特征表现为智能营销平台,其结合了营销自动化技术和智能化数据分析及营销策略推荐等功能。 具体来说,智能营销平台可以实现以下三个功能: 1、全渠道营销如今
-
主要内容:一、从一个新闻门户网站案例引入,二、推算一下你需要分析多少条数据?,三、黄金搭档:分布式存储+分布式计算这篇文章聊一个话题:什么是分布式计算系统? 一、从一个新闻门户网站案例引入 现在很多同学经常会看到一些名词,比如分布式服务框架,分布式系统,分布式存储系统,分布式消息系统。 但是有些经验尚浅的同学,可能都很容易被这些名词给搞晕。所以这篇文章就对“分布式计算系统”这个概念做一个科普类的分析。 如果你要理解啥是分布式计算,就必须先得理解啥是分布式存储,现在我们从一个小例子来引入。 比如说
-
本章将重点介绍如何开始使用分布式TensorFlow。目的是帮助开发人员了解重复出现的基本分布式TF概念,例如TF服务器。我们将使用Jupyter Notebook来评估分布式TensorFlow。使用TensorFlow实现分布式计算如下所述 - 第1步 - 为分布式计算导入必需的模块 - 第2步 - 使用一个节点创建TensorFlow集群。让这个节点负责一个名称为“worker”的作业,并在
-
在介绍GraphX之前,我们需要先了解分布式图计算框架。简言之,分布式图框架就是将大型图的各种操作封装成接口,让分布式存储、并行计算等复杂问题对上层透明,从而使工程师将焦点放在图相关的模型设计和使用上,而不用关心底层的实现细节。 分布式图框架的实现需要考虑两个问题,第一是怎样切分图以更好的计算和保存;第二是采用什么图计算模型。下面分别介绍这两个问题。 1 图切分方式 图的切分总体上说有点切分和边切
-
1977年,Apple 计算机公司使个人计算(personal computer)得以普及。最初拥有一台计算机只是爱好者的梦想,随着它的价格不断降低,人们可以购买供个人或办公使用的计算机。1981年,世界上最大的计算机广家IBM公司推出了IBM个人计算机(IBM Personal computer)。一夜之间,个人计算机遍布公司、企业和政府机关。 然而这些计算机只是“独立”的个体,各自做自己的工作
-
简介 在过去,开发者必须在服务器上为每个任务生成单独的 Cron 项目。而令人头疼的是任务调度不受源代码控制,而且必须通过 SSH 连接到服务器上来增加 Cron 项目。 Laravel 的命令调度程序允许你在 Laravel 中对命令调度进行清晰流畅的定义。并且在使用调度程序时,只需要在服务器上增加一条 Cron 项目即可。调度是在 app/Console/Kernel.php 文件的 sche
-
基本任务调度 方案1: 通过 @Cron 注解,这个需要依赖 cron4j 框架: //1分钟执行一次 @Cron("*/1 * * * *") public class MyTask implements Runnable { @Override public void run() { System.out.println("task running...");
-
一、MapReduce概述 Hadoop MapReduce 是一个分布式计算框架,用于编写批处理应用程序。编写好的程序可以提交到 Hadoop 集群上用于并行处理大规模的数据集。 MapReduce 作业通过将输入的数据集拆分为独立的块,这些块由 map 以并行的方式处理,框架对 map 的输出进行排序,然后输入到 reduce 中。MapReduce 框架专门用于 <key,value> 键值
-
类型 实现框架 应用场景 批处理 MapReduce 微批处理 Spark Streaming 实时流计算 Storm