
SnappyData将ApacheSpark和内存数据库融合起来,提供一种在单一集群中能够处理数据流、事务和交互分析的数据引擎。
Spark和远程数据源面临的挑战
Apache Spark是一种通用型并行计算引擎,用于大规模分析。究其核心,它有一个批处理设计中心,能够处理不同的数据源。虽然这提供了丰富、统一的数据访问,但是同时效率相当低下、成本相当高昂。分析处理需要重复拷贝庞大的数据集,需要对数据重新格式化,以适合Spark。在许多情况下,它最终未能兑现交互分析性能的承诺。比如说,每当聚合操作在庞大的Cassandra表上运行时,势必需要将整个表流式传输到Spark,以便执行聚合操作。Spark里面的缓存是不可改变的,导致了过时的洞察力。
SnappyData采用的方法
SnappyData采用了一种截然不同的方法。SnappyData将低延迟、高可用性的内存事务数据库(GemFireXD)以及共享内存管理和优化机制融入到了Spark。高可用性内存中存储区里面的数据使用与Spark(Tungsten)同样的列格式来排列。由于更好的向量化和代码生成,所有查询引擎操作符都大大经过了优化。最终结果是,性能相比原生的Spark缓存高出了一个数量级,处理外部数据源时比Spark性能更是高出了两个数量级。
实际上,我们将Spark变成了一种内存操作型数据库,具有事务、点读取和点写入等功能,可以处理Streams(Spark),并运行分析SQL查询。或者,它可以变成内存中横向扩展型混合数据库,可以执行Spark代码、SQL或者甚至对象。
如果你已经在使用Spark,不妨体验一下查询性能快20倍的感觉。不妨试试这个测试(https://github.com/SnappyDataInc/snappydata/blob/master/examples/quickstart/scripts/Quickstart.scala)。
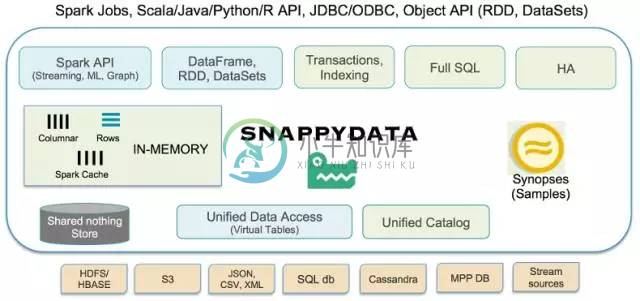
SnappyData的架构
-
做数据仓库的同学会面临三大问题:性能、稳定性、准确性,归根结底还是性能问题;框架的天花板以及sql复杂度、计算资源的紧张都会导致数据仓库的性能受到挑战,随着业务的积累,性能的问题变的越来越明显,性能差直接导致整个数仓集群的稳定性差,经常出问题的数仓自然也就会数据不准,所以解决上述3个问题,应优先解决性能问题。 介绍 SnappyData是一个基于内存的数据库,和redis不同的是SnappyDat
-
使用spark job导数之后,job显示执行成功,去dbeaver查询表但是显示Syntax error or analysis exception: Union can only be performed on tables with the compatible column types. Query execution failed 原因: SQL 错误 [20000] [42000
-
《SnappyData在美团酒店实时数据分析中的应用》 演讲/ 焦向 This talk is ‘opinionated’ • How so? o特定业务问题出发找方案 o基于自己总结的方法论 • Why? • 分布式存储及业务出身 业务 交互式报表、实时情报分析 • 交互式报表(InteractiveReporting) o实时数仓 • 实时情报分析(Intelligenceanalysis)
-
分享一个实时OLAP系统–SnappyData的博客与中文社区 SnappyData中文博客 SnappyData中文社区
-
第一种方法,官方说明 http://snappydatainc.github.io/snappydata/howto/use_snappy_shell/ 参考如下: /usr/local/snappydata/bin/snappy-sql connect client '192.168.86.110:1527'; 后面可以直接输入SQL了: use mydb1; select * from te
-
如果我只有一个内存为25 GB的执行器,并且如果它一次只能运行一个任务,那么是否可以处理(转换和操作)1 TB的数据?如果可以,那么将如何读取它以及中间数据将存储在哪里? 同样对于相同的场景,如果hadoop文件有300个输入拆分,那么RDD中会有300个分区,那么在这种情况下这些分区会在哪里?它会只保留在hadoop磁盘上并且我的单个任务会运行300次吗?
-
使用kafka processor API(不是DSL)读取源主题并写入目标主题,对于单个kafka集群设置(也就是说,如果源主题和目标主题都驻留在同一集群上)来说工作很好,但是当源主题和目标主题驻留在不同的kafka集群上时,我将获得目标处理器上下文的NullPointerException 我们如何使用kafka streams处理器API从一个集群中的一个主题写到另一个集群中的另一个主题?
-
目录 集群流控介绍 集群流控规则配置 集群流控示例 集群流控管理(控制台) Envoy RLS token server 介绍 为什么要使用集群流控呢?假设我们希望给某个用户限制调用某个 API 的总 QPS 为 50,但机器数可能很多(比如有 100 台)。这时候我们很自然地就想到,找一个 server 来专门来统计总的调用量,其它的实例都与这台 server 通信来判断是否可以调用。这就是最基
-
我有一个特定的要求,其中,我需要检查空的数据文件。如果为空,则填充默认值。这是我尝试过但没有得到我想要的东西。 这个想法是,如果df不是空的,就得到它。如果为空,则填写默认值为零。这似乎不起作用。以下是我得到的。 请帮忙。
-
下面是我的流处理的伪代码。 上面的代码流程正在创建多个文件,我猜每个文件都有不同窗口的记录。例如,每个文件中的记录都有时间戳,范围在30-40秒之间,而窗口时间只有10秒。我预期的输出模式是将每个窗口数据写入单独的文件。对此的任何引用或输入都会有很大帮助。
-
我试图在Spark中创建成批的行。为了保持发送到服务的记录数量,我想对项目进行批处理,这样我就可以保持数据发送的速率。对于, 对于给定的我想创建 例如,如果输入有100条记录,那么输出应该像一样,其中每个应该是记录(Person)的列表。 我试过了,但没用。 我想在Hadoop集群上运行此作业。有人能帮我吗?