
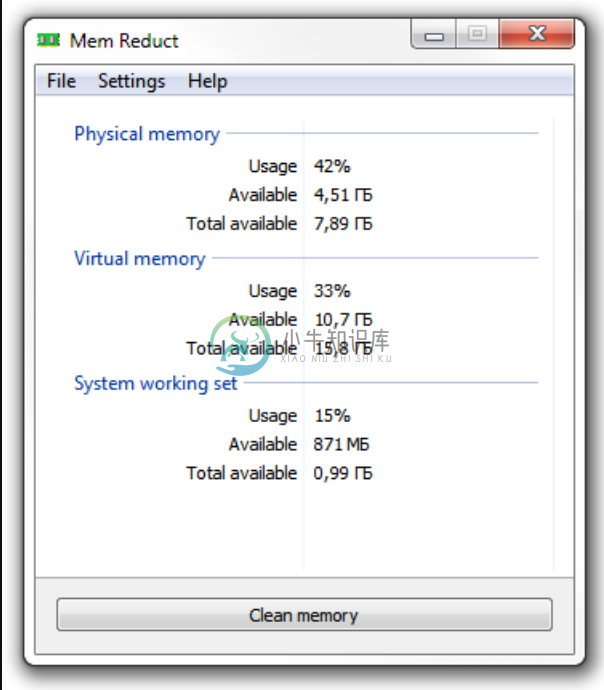
Mem Reduct是一款内存、系统缓存清理工具!
-
体积小巧,大小仅302kb。
-
效率高!不像市面上其他优化内存软件,软件表面上释放很多了内存,其实只是表面数据,实则没一点效果。
-
完全免费,持续升级,界面简洁、无广告。
-
写在前面的话 对于程序猿来说,我们会追求性能,效率。不例外地,记录下,用pandas读取csv,减少读取内存的一个常见方法。 import pandas as pd def reduce_mem_usage(df, verbose=True): numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
-
最近在做kaggle比赛的时候看到有一个函数reduce_mem_usage,可以对数据进行压缩,从而减少内存消耗,因此记录一下: def reduce_mem_usage(df, verbose=True): numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64'] start_mem = df
-
我们知道,GPU擅长做并行计算,像element-wise操作。GEMM, Conv这种不仅结果张量中元素的计算相互不依赖,而且输入数据还会被反复利用的更能体现GPU的优势。但AI模型计算或者HPC中还有一类操作由于元素间有数据依赖,会给并行化带来挑战,那就是reduce操作。它代表一类操作,即将多个元素通过某种特定的运算进行归约。其应用很广泛,很多其它算法也以它为基础,如scan, histog
-
""" load data(reduce memory usage) https://www.kaggle.com/gemartin/load-data-reduce-memory-usage """ import pandas as pd import numpy as np def reduce_mem_usage(df): """ iterate through all the
-
def reduce_mem_usage(df): start_mem = df.memory_usage().sum() print('Memory usage of dataframe is {:.2f} MB'.format(start_mem)) for col in df.columns: col_type = df[col].dtyp
-
BWA MEM算法 现在BWA大家基本上只用其mem算法了,无论是二代还是三代比对到参考基因组上,BWA应用得最多的就是在重测序方面。 Aligning sequence reads, clone sequences and assembly contigs with BWA-MEM - arXiv:1303.3997v2 摘要 BWA-MEM is a new alignment algorit
-
...f struct ngx_queue_s ngx_queue_t; struct ngx_queue_s { ngx_queue_t *prev; ngx_queue_t *next; }; #define ngx_queue_init(q) 这次给大家带来jQuery的prev()使用详解,jQuery的prev()使用注意事项有哪些,下面就是实战案例,一起来看一下。prev() 函数被用
-
在阿里天池,今天看到的有位大佬,关于减少DataFrame的占用内存的这个函数。放在这记录一下,后面再回头过来看看 import pandas as pd import numpy as np import warnings warnings.filterwarnings('ignore') def reduce_mem_usage(df): """ iterate through all
-
reduce的用法以及用该方法对对象进行分类 reduce() 方法接收一个函数作为累加器(accumulator),该方法可以接受两个参数。 当reduce方法里面只有一个参数,该参数是一个回调函数callback的时候,回调函数有四个参数,分别是: prev上一次调用回调返回的值,第一次遍历时该prev是数组的第一项; curr是数组中当前被处理的每一项元素,从数组的第二项开始; index当
-
名词解释: 云霄飞车:hive本身对MR Job的 reduce数估算不合理,导致reduce分配过少,任务运行很慢,云霄飞车项目主要对hive本身reduce数的估算进行优化。 map_input_bytes:map输入文件大小,单位:bytes map_output_bytes:map输出文件大小,单位:bytes 优化背景: 云霄飞车一期存在如下问题:只能优化reduce数>1的MR J
-
在python3.0.0之后reduce函数已经不是一个内置函数了,需要调用。 解决方法: from functools import reduce
-
因为自己的手机比较卡,所以就想写个小工具改善一下手机卡顿的情况,既然写了就又顺手写点自定义的View,最后又顺手把它上线了,其实基本没什么人下载,现在把原来项目的友盟数据统计和有米广告去掉了开源出来给大家看看。 apk下载:http://zhushou.360.cn/detail/index/soft_id/2366842 开源地址:http://git.oschina.net/cocobaby/
-
问题内容: 题 我正在寻找Java内存对象缓存API。有什么建议吗?您过去使用过什么解决方案? 当前 现在,我只是在使用地图: 要求 我需要扩展缓存以包括以下基本功能: 最大尺寸 生存时间 但是,我不需要更复杂的功能,例如: 来自多个进程的访问(缓存服务器) 持久性(到磁盘) 意见建议 内存中缓存: Guava CacheBuilder-活动开发。请参阅此演示文稿。 LRUMap-通过API配置。
-
问题内容: 编写新的工作流引擎还是使用现有的BPM引擎更好吗:jBPM 5,Activiti 5? 我的应用程序是基于Web的应用程序,性能非常重要。我的疑问是,与编写简单的工作流引擎相比,使用jBPM / Activiti是否会增加性能开销。 如果我采用自我实现,我会错过工作流程的可视化。为了性能,可以进行交易。 问题答案: 这确实取决于您的要求。首先,查看您是否真的需要工作流引擎(此资源或其他
-
本文向大家介绍详解Spring Batch 轻量级批处理框架实践,包括了详解Spring Batch 轻量级批处理框架实践的使用技巧和注意事项,需要的朋友参考一下 实践内容 从 MariaDB 一张表内读 10 万条记录,经处理后写到 MongoDB 。 具体实现 1、新建 Spring Boot 应用,依赖如下: 2、创建一张表,并生成 10 万条数据 3、创建 Person 类 4、创建一个中
-
主要内容:一、简介,二、Java对象头中的Mark Word,三、偏向锁,四、轻量级锁,五、重量级锁,六、自旋锁,七、锁升级过程一、简介 在讲解这些锁概念之前,我们要明确的是这些锁不等同于Java API中的ReentratLock这种锁,这些锁是概念上的,是JDK1.6中为了对synchronized同步关键字进行优化而产生的的锁机制。这些锁的启动和关闭策略可以通过设定JVM启动参数来设置,当然在一般情况下,使用JVM默认的策略就可以了。 二、Java对象头中的Mark Word HotSpo
-
本文向大家介绍SpringBoot2 整合Ehcache组件,轻量级缓存管理的原理解析,包括了SpringBoot2 整合Ehcache组件,轻量级缓存管理的原理解析的使用技巧和注意事项,需要的朋友参考一下 本文源码:GitHub·点这里 || GitEE·点这里 一、Ehcache缓存简介 1、基础简介 EhCache是一个纯Java的进程内缓存框架,具有快速、上手简单等特点,是Hibernat
-
本文向大家介绍Android EasyBarrage实现轻量级弹幕效果,包括了Android EasyBarrage实现轻量级弹幕效果的使用技巧和注意事项,需要的朋友参考一下 本文介绍了Android EasyBarrage实现轻量级弹幕效果,分享给大家,具体如下: 概述 EasyBarrage是Android平台的一种轻量级弹幕效果目前支持以下设置: 自定义字体颜色,支持随机颜色; 自定义字体大
-
有没有办法轻松重置所有sino间谍的模拟和存根,这些模拟和存根将在每个块之前干净利落地与摩卡一起工作。 我知道沙箱是一个选项,但我不知道如何使用沙箱进行此操作