
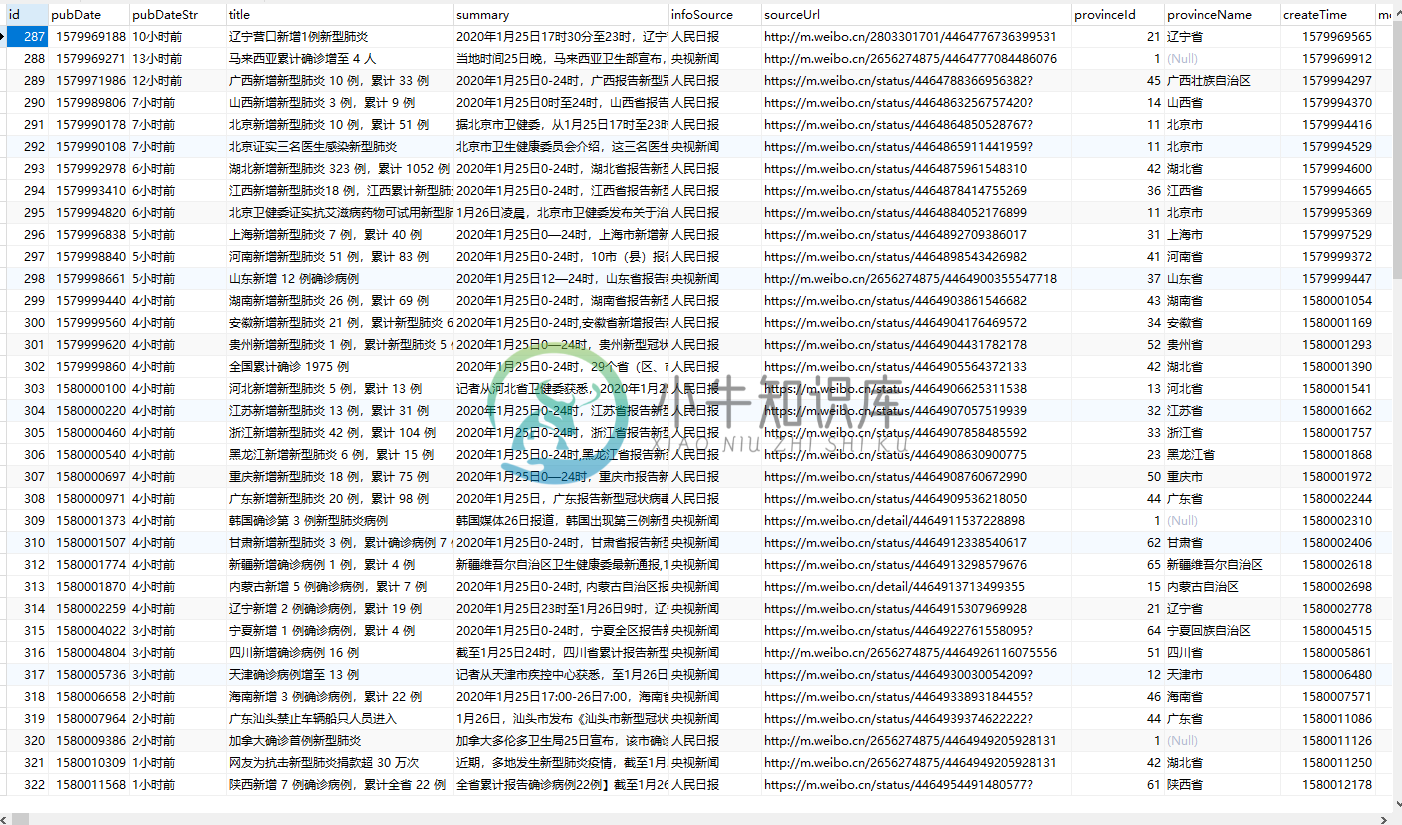
爬冠状病毒新型肺炎疫情实时数据+数据持久化+邮件通知。
数据源来自“丁香园” :https://3g.dxy.cn/newh5/view/pneumonia_peopleapp?from=timeline&isappinstalled=0
- 共三部分数据: 实时新闻 + 全局信息(全国 确诊 2055 例 疑似 2692 例 死亡 56 例 治愈 49 例) + 各省份疫情
- 数据库用MYSQL,建表语句在SQL目录下
- 功能:
- jsoup获取数据,正则匹配筛选数据
- 用mybatis+mysql做数据持久化
- 数据发生变化时,发邮件通知
-
爬虫跟静态服务器搭建 爬取之前要做的事: 首先下载npm的一个模块 命令:npm i crawler 下载完你会得到一个名字是node_modules文件夹跟一个package-lock.json文件 注意: 使用第三方模块: 新建一个文件夹,文件夹名字非中文,名字也不能跟模块名字一样 进到文件夹里,命令运行:npm init -y 初始化一个文件 下载模块 使用模块 一、爬取网站的内容 var
-
最近的一些疫情信息很让人揪心,为了方便大家掌握疫情信息,在空闲之余做了一个关于 nCoV 的疫情监控小助手。主要的功能是通过企业微信的 WebHook 来推送疫情信息。这里将使用 Serverless 的整体代码思路和架构方式分享给大家。本文作者:tabor 实现效果 我们想要实现的大致的效果是这样的: 首先,我们需要解决的是数据来源问题,这里我们可以使用 python 爬虫来做这件事情,但是由于
-
本文向大家介绍Python3实现监控新型冠状病毒肺炎疫情的示例代码,包括了Python3实现监控新型冠状病毒肺炎疫情的示例代码的使用技巧和注意事项,需要的朋友参考一下 代码如下所示: 运行效果图如下所示: 总结 以上所述是小编给大家介绍的Python3实现监控新型冠状病毒肺炎疫情的示例代码,希望对大家有所帮助!
-
随着今天从欧洲到美国的旅行限制生效,以及为了减缓新冠病毒的传播更加劝导群众留在家中,我们很好奇这些措施何影响全旅行。显而易见,我们使用Cesium进行探索。 我们开始收集过去几个月每隔一天的航班数据。下列是进出北京主要国际机场的所有航班: [随着时间的推移,北京首都国际机场(PEK)的预定航班数量已可视化出来。起飞显示为红色,到达显示为绿色。] 一月底,航班数量急剧下降,从大约900架次迅速下降到
-
不知道大伙有没有看到过这一句话:“中国(疫苗研发)非常困难,因为在中国我们没有办法做第三期临床试验,因为没有病人了。”这句话是中国工程院院士钟南山在上海科技大学2021届毕业典礼上提出的。这句话在全网流传,被广大网友称之为“凡尔赛”发言。今天让我们用数据来看看这句话是不是“凡尔赛”本赛。在开始之前我们先来说说今天要用到的python库吧!1.数据获取部分requests lxml json openpyxl2.数据可视化部分pandas pyecharts(可视化库)
-
宇润爬虫框架 Yurun Crawler 是一个低代码、高性能、分布式爬虫采集框架,基于 imi 框架开发,运行在 Swoole 常驻内存的协程环境。
-
本文向大家介绍python爬取淘宝商品详情页数据,包括了python爬取淘宝商品详情页数据的使用技巧和注意事项,需要的朋友参考一下 在讲爬取淘宝详情页数据之前,先来介绍一款 Chrome 插件:Toggle JavaScript (它可以选择让网页是否显示 js 动态加载的内容),如下图所示: 当这个插件处于关闭状态时,待爬取的页面显示的数据如下: 当这个插件处于打开状态时,待爬取的页面显示的数据
-
本文向大家介绍python爬虫爬取网页数据并解析数据,包括了python爬虫爬取网页数据并解析数据的使用技巧和注意事项,需要的朋友参考一下 1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。 只要浏览器能够做的事情,原则上,爬虫都能够做到。 2.网络爬虫的功能 网络爬虫可以代替手工做很多事情,比如可以