
分布式爬虫框架XXL-CRAWLER
XXL-CRAWLER 是一个分布式爬虫框架。一行代码开发一个分布式爬虫,拥有"多线程、异步、IP动态代理、分布式、JS渲染"等特性;
特性
1、简洁:API直观简洁,可快速上手;
2、轻量级:底层实现仅强依赖jsoup,简洁高效;
3、模块化:模块化的结构设计,可轻松扩展
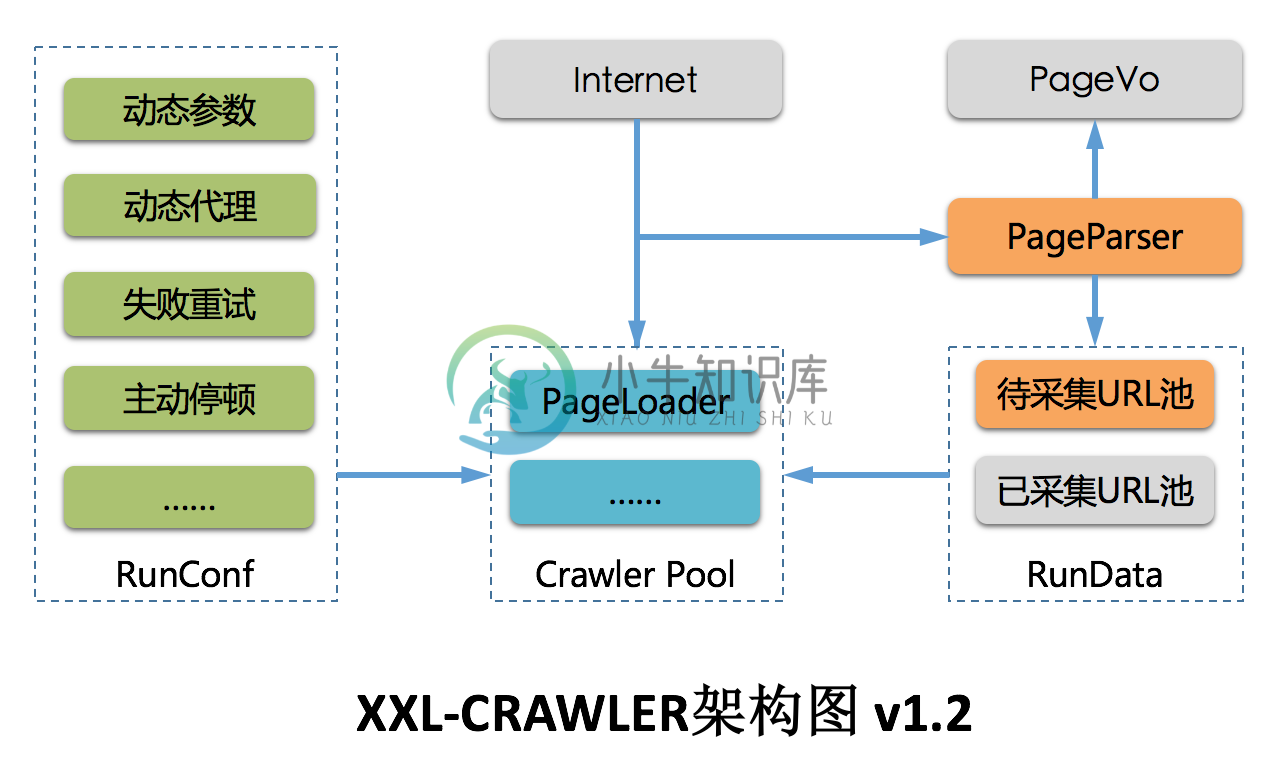
4、面向对象:支持通过注解,方便的映射页面数据到PageVO对象,底层自动完成PageVO对象的数据抽取和封装返回;单个页面支持抽取一个或多个PageVO
5、多线程:线程池方式运行,提高采集效率;
6、分布式支持:通过扩展 "RunData" 模块,并结合Redis或DB共享运行数据可实现分布式。默认提供LocalRunData单机版爬虫。
7、JS渲染:通过扩展 "PageLoader" 模块,支持采集JS动态渲染数据。原生提供Jsoup(快速、推荐)和HtmlUnit(较慢、JS渲染)两种实现,支持自由扩展其他实现。
8、失败重试:请求失败后重试,并支持设置重试次数;
9、代理IP:对抗反采集策略规则WAF;
10、动态代理:支持运行时动态调整代理池,以及自定义代理池路由策略;
11、异步:支持同步、异步两种方式运行;
12、扩散全站:支持以现有URL为起点扩散爬取整站;
13、去重:防止重复爬取;
14、URL白名单:支持设置页面白名单正则,过滤URL;
15、自定义请求信息,如:请求参数、Cookie、Header、UserAgent轮询、Referrer等;
16、动态参数:支持运行时动态调整请求参数;
17、超时控制:支持设置爬虫请求的超时时间;
18、主动停顿:爬虫线程处理完页面之后进行主动停顿,避免过于频繁被拦截;
文档地址
技术交流
-
版本 V1.1.0,新特性[2017-18-06] 1、页面默认cssQuery调整为html标签; 2、升级Jsoup至1.11.1版本; 3、修复PageVO注解失效的问题; 4、属性注解参数attributeKey调整为selectVal; 5、代理IP:对抗反采集策略规则WAF; 6、动态代理:支持运行时动态调整代理池,以及自定义代理池路由策略; 简介 XXL-CRAWLER 是一个灵活高
-
版本新特性 1、JS渲染:支持JS渲染方式采集数据,可参考 "爬虫示例6"; 2、抽象并设计PageLoader,方便自定义和扩展页面加载逻辑,如JS渲染等。底层提供 "JsoupPageLoader(默认/推荐)","HtmlUnitPageLoader"两种实现,可自定义其他类型PageLoader如 "Selenium" 等; 3、修复Jsoup默认加载1M的限制; 4、爬虫线程中断处理优化
-
互联网时代的信息爆炸是很多人倍感头痛的问题,应接不暇的新闻、信息、视频,无孔不入地侵占着我们的碎片时间。但另一方面,在我们真正需要数据的时候,却感觉数据并不是那么容易获取的。比如我们想要分析现在人在讨论些什么,关心些什么。甚至有时候,可能我们只是暂时没有时间去一一阅览心仪的小说,但又想能用技术手段把它们存在自己的资料库里。哪怕是几个月或一年后再来回顾。再或者我们想要把互联网上这些稍纵即逝的有用信息
-
在前面我们已经掌握了Scrapy框架爬虫,虽然爬虫是异步多线程的,但是我们只能在一台主机上运行,爬取效率还是有限。 分布式爬虫则是将多台主机组合起来,共同完成一个爬取任务,将大大提高爬取的效率。 16.1 分布式爬虫架构 回顾Scrapy的架构: Scrapy单机爬虫中有一个本地爬取队列Queue,这个队列是利用deque模块实现的。 如果有新的Request产生,就会放到队列里面,随后Reque
-
宇润爬虫框架 Yurun Crawler 是一个低代码、高性能、分布式爬虫采集框架,基于 imi 框架开发,运行在 Swoole 常驻内存的协程环境。
-
主要内容:Scrapy下载安装,创建Scrapy爬虫项目,Scrapy爬虫工作流程,settings配置文件Scrapy 是一个基于 Twisted 实现的异步处理爬虫框架,该框架使用纯 Python 语言编写。Scrapy 框架应用广泛,常用于数据采集、网络监测,以及自动化测试等。 提示:Twisted 是一个基于事件驱动的网络引擎框架,同样采用 Python 实现。 Scrapy下载安装 Scrapy 支持常见的主流平台,比如 Linux、Mac、Windows 等,因此你可以很方便的安装它
-
本文向大家介绍Java多线程及分布式爬虫架构原理解析,包括了Java多线程及分布式爬虫架构原理解析的使用技巧和注意事项,需要的朋友参考一下 这是 Java 爬虫系列博文的第五篇,在上一篇Java 爬虫服务器被屏蔽的解决方案中,我们简单的聊反爬虫策略和反反爬虫方法,主要针对的是 IP 被封及其对应办法。前面几篇文章我们把爬虫相关的基本知识都讲的差不多啦。这一篇我们来聊一聊爬虫架构相关的内容。 前面几
-
本文向大家介绍简单好用的nodejs 爬虫框架分享,包括了简单好用的nodejs 爬虫框架分享的使用技巧和注意事项,需要的朋友参考一下 这个就是一篇介绍爬虫框架的文章,开头就不说什么剧情了。什么最近一个项目了,什么分享新知了,剧情是挺好,但介绍的很初级,根本就没有办法应用,不支持队列的爬虫,都是耍流氓。 所以我就先来举一个例子,看一下这个爬虫框架是多么简单并可用。 第一步:安装 Crawl-pet