
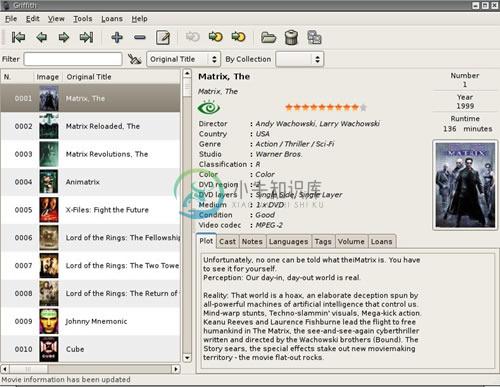
Griffith 是一个电影数据收集和管理软件,你可简单的通过输入电影的名称来添加该电影,Griffith 会尝试从网络中获取该电影的详细信息。
-
我的Ionic 5应用程序中有以下Firestore数据库结构。 书(集合) {bookID}(带有book字段的文档) 赞(子集合) {userID}(文档名称作为带有字段的用户ID) 集合中有文档,每个文档都有一个子集合。Like collection的文档名是喜欢这本书的用户ID。 我正在尝试进行查询以获取最新的,同时尝试从子集合中获取文档以检查我是否喜欢它。 我在这里做的是用每个图书ID调
-
Scrapy提供了方便的收集数据的机制。数据以key/value方式存储,值大多是计数值。 该机制叫做数据收集器(Stats Collector),可以通过 Crawler API 的属性 stats 来使用。在下面的章节 常见数据收集器使用方法 将给出例子来说明。 无论数据收集(stats collection)开启或者关闭,数据收集器永远都是可用的。 因此您可以import进自己的模块并使用其
-
从Chromium的内容模块收集跟踪数据,以发现性能瓶颈和缓慢的操作 进程: 主进程 这个模块不具备web接口,需要我们在chrome浏览器中添加 chrome://tracing/ 来加载生成结果文件. 注意该模块应当在 ready事件之后使用. 1 const {contentTracing} = require('electron') 2 const options = { 3 categ
-
主要内容:Google Analytics / Mix面板(分析工具),鼠标流/疯狂蛋(重播工具),WebEngage(测量工具),其他工具 - 聊天,电子邮件来自Google Analytics的数据可以帮助您找到访问者的行为。 总是建议从网站收集足够的数据。 尝试找到转化率较低或可以提高的高丢弃率的网页。 在本章中,我们将讨论一些可用于收集A/B测试数据的工具。 Google Analytics / Mix面板(分析工具) 大多数网站都安装了Google Analytics,以了解访问者与网
-
我在处理post数据时遇到问题。 例如,如果我有一个简单的小表格: 然后收集数据并尝试回显: 我得到一个错误:MethodNotAllowedHttpException在RouteCollection中。php第218行: 如果我用GET做同样的事情,效果会很好。 我试图编辑VerifyCsrfToken并添加: 仍然不起作用。
-
我正在尝试将表单序列化值发布到控制器(WebAPI自宿主)。我无法理解为什么没有正确绑定NameValueCollection。使用jQuery的客户端: 使用Web API自主机的服务器端: 非常感谢。
-
我是DynamoDB的新手,阅读了开发者指南[1],创建了这个电影数据库[2],我能够轻松地查询数据库中的特定年份和标题,因为它们是主键的一部分。 但我想检索以下两件事,我想知道为什么这些例子似乎没有涉及到: 从整个表中检索所有类型的列表 通过提供特定类型检索电影标题 我发现的例子是关于为一个简单字段(比如评级或字符串字段)添加一个GSI,但我不知道当我的字段本身是一个列表(比如类型)时,我该怎么
-
在我目前正在开发的Firebase Android应用程序中,我想提供一个导出特性。这个特性应该允许用户导出一组存储在Firebase中的数据。 我的计划是将所有需要的数据收集到一个中间对象(datastructure)中,该对象可以(重新)用于多种导出类型。 谁有应对这一问题的最佳做法?