
Python爬虫爬取电影票房数据及图表展示操作示例

本文实例讲述了Python爬虫爬取电影票房数据及图表展示操作。分享给大家供大家参考,具体如下:
爬虫电影历史票房排行榜 http://www.cbooo.cn/BoxOffice/getInland?pIndex=1&t=0
- Python爬取历史电影票房纪录
- 解析Json数据
- 横向条形图展示
- 面向对象思想
导入相关库
import requests import re from matplotlib import pyplot as plt from matplotlib import font_manager import json
类代码部分
class DYOrder(object):
#初始化
def __init__(self,page=1):
self.url = 'http://www.cbooo.cn/BoxOffice/getInland?pIndex={}&t=0'.format(page)
self.headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'}
#请求
def __to_request(self):
response = requests.get(url=self.url,headers=self.headers)
return self.__to_parse(response.content.decode('utf-8'))
#解析
def __to_parse(self,html):
#返回为JSON字符串
#首先将字符串反序列化为JSON对象
my_json = json.loads(html)
return my_json
#图表展示
def __to_show(self,data,show_type):
x = []
y = []
for value in data:
x.append(value['MovieName'])
y.append(int(value['BoxOffice']))
my_font = font_manager.FontProperties(fname='/System/Library/Fonts/PingFang.ttc',size=18)
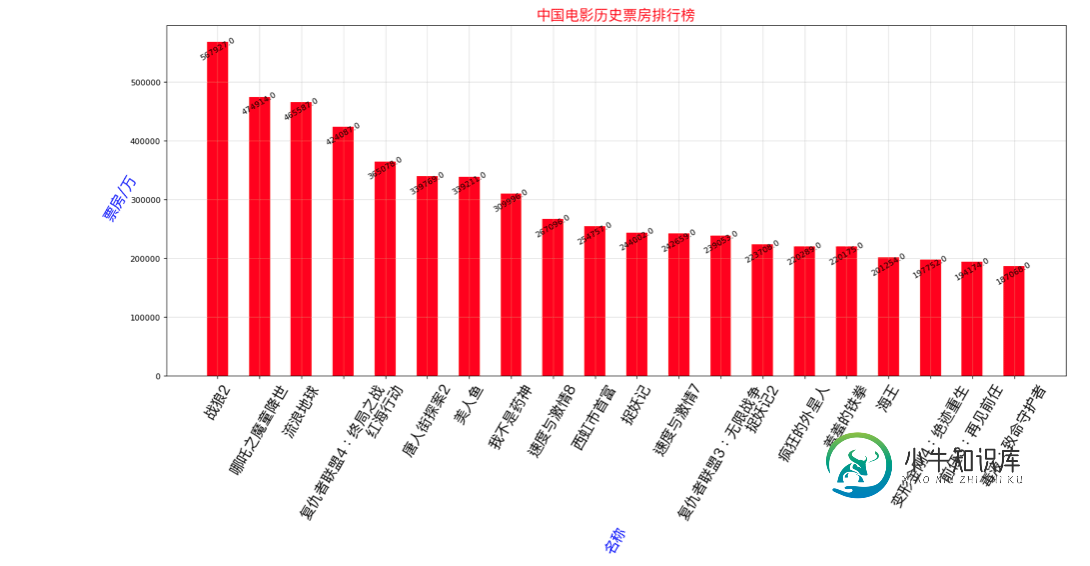
if show_type == 1:
plt.figure(figsize=(20,8),dpi=80)
rects = plt.bar(range(len(x)),[float(i) for i in y],width=0.5,color='red')
plt.xticks(range(len(x)),x,fontproperties=my_font,rotation=60)
plt.xlabel('名称',rotation=60,color='blue',fontproperties=my_font)
plt.ylabel('票房/万',rotation=60,color='blue',fontproperties=my_font)
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width()/2,height+0.4,str(height),ha='center',rotation=30)
else:
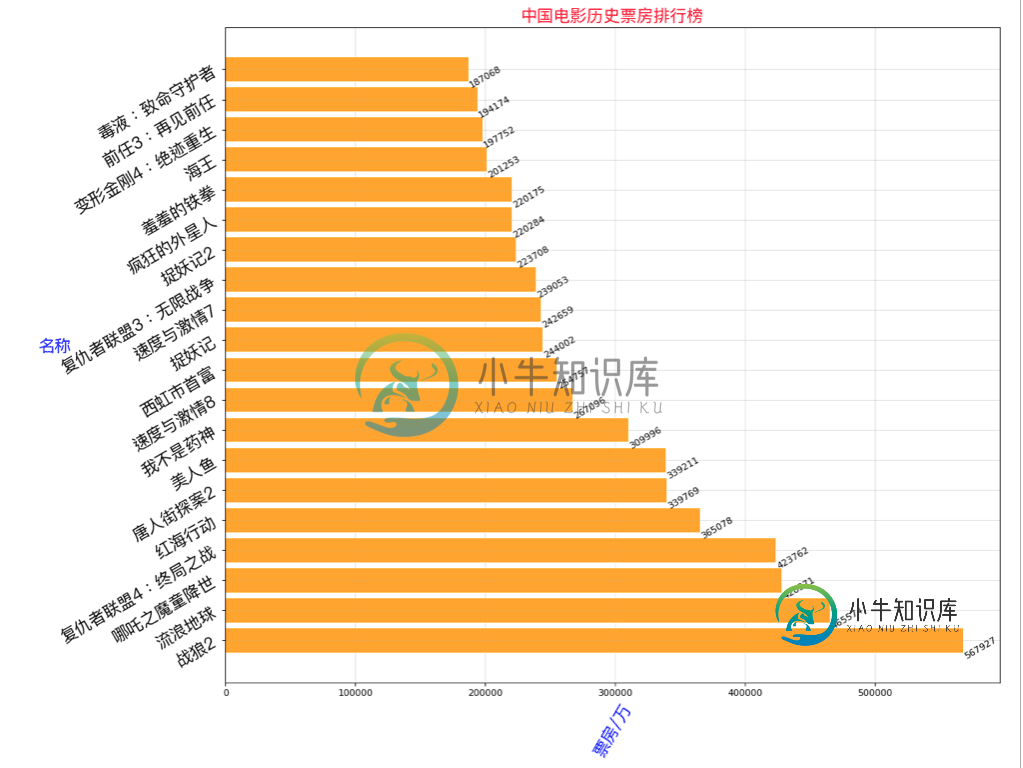
# 横向 plt.barh(y,x)
plt.figure(figsize=(15,13),dpi=80)
rects = plt.barh(range(len(x)),y,height=0.8,color='orange')
plt.yticks(range(len(x)),x,fontproperties=my_font,rotation=30)
plt.ylabel('名称',rotation=0,color='blue',fontproperties=my_font)
plt.xlabel('票房/万',rotation=60,color='blue',fontproperties=my_font)
for rect in rects:
width = rect.get_width()
plt.text(width, rect.get_y()+0.3/2,str(width),va='center',rotation=30)
plt.grid(alpha=0.4)
plt.title('中国电影历史票房排行榜',color='red',size=18,fontproperties=my_font)
plt.show()
#所有操作
def to_run(self,show_type=1):
result = self.__to_request()
self.__to_show(result,show_type)
调用类并展示
if __name__ == '__main__': dy_order = DYOrder(1) # type 1 竖向条形图 2 横向 dy_order.to_run(2)
更多关于Python相关内容可查看本站专题:《Python Socket编程技巧总结》、《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。
-
本文向大家介绍Python爬虫爬取、解析数据操作示例,包括了Python爬虫爬取、解析数据操作示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python爬虫爬取、解析数据操作。分享给大家供大家参考,具体如下: 爬虫 当当网 http://search.dangdang.com/?key=python&act=input&page_index=1 获取书籍相关信息 面向对象思想 利用不
-
本文向大家介绍Python爬虫爬取杭州24时温度并展示操作示例,包括了Python爬虫爬取杭州24时温度并展示操作示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python爬虫爬取杭州24时温度并展示操作。分享给大家供大家参考,具体如下: 散点图 爬虫杭州今日24时温度 https://www.baidutianqi.com/today/58457.htm 利用正则表达式爬取杭州温度
-
本文向大家介绍python爬虫爬取某站上海租房图片,包括了python爬虫爬取某站上海租房图片的使用技巧和注意事项,需要的朋友参考一下 对于一个net开发这爬虫真真的以前没有写过。这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup。python 版本:python3.6 ,IDE :pycharm
-
本文向大家介绍python爬虫爬取网页数据并解析数据,包括了python爬虫爬取网页数据并解析数据的使用技巧和注意事项,需要的朋友参考一下 1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。 只要浏览器能够做的事情,原则上,爬虫都能够做到。 2.网络爬虫的功能 网络爬虫可以代替手工做很多事情,比如可以
-
本文向大家介绍Python制作爬虫抓取美女图,包括了Python制作爬虫抓取美女图的使用技巧和注意事项,需要的朋友参考一下 作为一个新世纪有思想有文化有道德时刻准备着的屌丝男青年,在现在这样一个社会中,心疼我大慢播抵制大百度的前提下,没事儿上上网逛逛YY看看斗鱼翻翻美女图片那是必不可少的,可是美图虽多翻页费劲!今天我们就搞个爬虫把美图都给扒下来!本次实例有2个:煎蛋上的妹子图,某网站的rosi
-
本文向大家介绍python爬虫爬取图片的简单代码,包括了python爬虫爬取图片的简单代码的使用技巧和注意事项,需要的朋友参考一下 Python是很好的爬虫工具不用再说了,它可以满足我们爬取网络内容的需求,那最简单的爬取网络上的图片,可以通过很简单的方法实现。只需导入正则表达式模块,并利用spider原理通过使用定义函数的方法可以轻松的实现爬取图片的需求。 1、spider原理 spider就是定