
Turbine 是实时流低延时高吞吐量的聚合器。

-
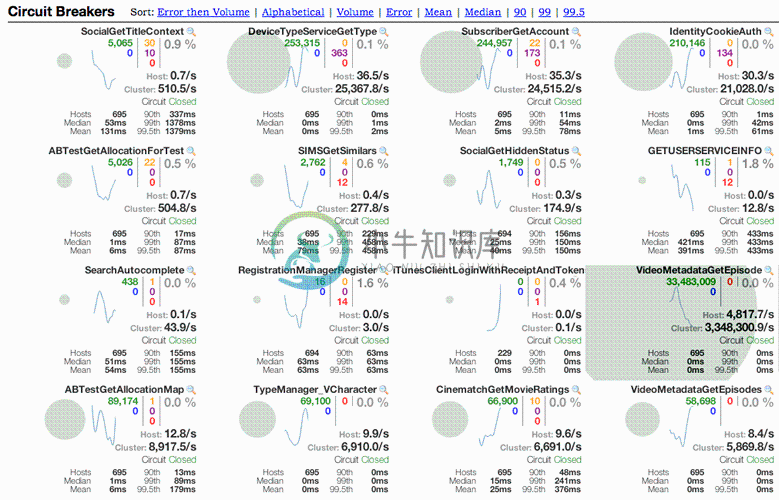
1.turbine是什么?它的作用是什么? Turbine is a tool for aggregating streams of Server-Sent Event (SSE) JSON data into a single stream. The targeted use case is metrics streams from instances in an SOA being aggre
-
com.netflix.turbine.monitor.instance.InstanceMonitor$MisconfiguredHostException: [{"timestamp":"2018-08-07T03:36:31.487+0000","status":404,"error":"Not Found","message":"No message available","path":"
-
Hystrix学习 作用:提供熔断器功能,阻止分布式系统出现联动故障 注意:Feign包中已包含Hystrix 配置 pom.xml <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eu
-
springcloud 2.0 Turbine 异常:com.netflix.turbine.monitor.instance.InstanceMonitor$MisconfiguredHostException: [{"timestamp":"2020-05-17T11:48:25.610+0000","status":404,"error":"Not Found","message":"No
-
在使用包装Ribbon客户端的Hystrix命令时,您希望确保将您的Hystrix超时配置为比配置的Ribbon超时更长的超时,包括可能进行的任何潜在重试。例如,如果您的Ribbon连接超时为一秒,而Ribbon客户机可能重试请求三次,那么您的Hystrix超时应该略多于三秒。 如何引入Hystrix Dashboard 在项目中引入Hystrix Dashboard,通过starter使用gro
-
简介: Turbine是聚合服务器发送事件流数据的一个工具,Hystrix的监控中,只能监控单个节点,实际生产中都为集群,因此可以通过Turbine来监控集群下Hystrix的metrics情况 Turbine的github地址:https://github.com/Netflix/Turbine 使用场景 在复杂的分布式系统中,相同服务的结点经常需要部署上百甚至上千个,很多时候,运维人员希望能够
-
Turbine 聚合 Hystrix 监控数据 连接多台服务器,抓取日志数据,进行聚合, 交给仪表盘在同一个监控界面进行展现 搭建 Turbine 服务 1.添加 Turbine、eureka client 依赖 <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-st
-
我正在尝试运行Flink流媒体作业。我想确定流处理的延迟和吞吐量。我已启动Kafka代理服务器,并收到来自Kafka的传入消息。如何计算每秒的邮件数(吞吐量)?(如rdd.count。是否有类似的方法来获取传入消息的计数) (完整的场景:我已经通过生产者发送了消息作为Json对象。我在Json对象中添加了一些信息,如名称为字符串和System.currentTimeMills。在流式传输期间,我如
-
我为帖子的篇幅感到抱歉,但有很多事情可能会导致我的情况,我已经尝试将我根据其他帖子所做的所有设置更改包括在内。简言之,我的WCF服务似乎一次只能处理3到4个并发客户端请求。如果我将应用程序池最大工作进程数设置得更高(大约10个),或者将服务行为ConcurrencyMode设置为多个,那么吞吐量就会大大提高(快几倍)。然而,这些似乎是真正问题的解决办法,带来了他们自己的问题。是我错了,还是IIS应
-
问题内容: 我为Apache Flink写了一个非常简单的Java程序,现在我对测量统计信息感兴趣,例如吞吐量(每秒处理的元组数)和等待时间(程序需要处理每个输入元组的时间)。 我知道Flink公开了一些指标: https://ci.apache.org/projects/flink/flink-docs- release-1.2/monitoring/metrics.html 但是我不确定如何使
-
我正在对ElasticSearch进行基准测试,以实现非常高的索引吞吐量。 我目前的目标是能够在几个小时内索引30亿(3,000,000,000)文档。为此,我目前有3台windows服务器机器,每台16GB内存和8个处理器。插入的文档有一个非常简单的映射,只包含少数数字非分析字段(被禁用)。 使用这个相对适中的钻机,我能够达到每秒大约120,000个索引请求(使用大桌子监控),我相信吞吐量可以进
-
我是Kafka的新手,正在运行一些性能测试。我正在运行一个由我的笔记本电脑和一个raspberry pi zero W(1 GHz、单核CPU、512 MB RAM、802.11n无线局域网)组成的2台机器集群。最终,pi将运行一个单独的生成器(java),该生成器将二进制传感器数据(理想情况下是更小的记录,例如,10 kb,以最快的速度)发送给kafka,然后由消费者在我的笔记本电脑或另一个pi
-
用户:100 平均Res:2.4秒 吞吐量:10/分钟 错误%:0 通过关闭所有监听器,在非GUI模式下运行测试。Jmeter实例和应用服务器的CPU、内存利用率良好。不超过30%的使用率。
-
本文向大家介绍springboot高并发下提高吞吐量的实现,包括了springboot高并发下提高吞吐量的实现的使用技巧和注意事项,需要的朋友参考一下 公司让做一个全文检索的项目,我使用的是elasticsearch。但是对性能有很高的要求,为了解决性能问题,我简直是寝食难安。 es(elasticsearch)没有使用分布式,单台的。 开发完测试的时候,查询慢,吞吐量低。 网友们建议用异步--使
-
总的来说,我认为我对延迟和吞吐量之间的区别有很好的理解。但是,对于Intel Intrinsics,延迟对指令吞吐量的影响我还不清楚,尤其是在顺序(或几乎顺序)使用多个内在调用时。 例如,让我们考虑: 这有11个延迟,在Haswell处理器上的吞吐量为7。如果我在循环中运行这条指令,我会在11个循环后获得每个循环的连续输出吗?由于这需要一次运行11条指令,并且由于我的吞吐量为7,我是否用完了“执行