
OpenTURNS 是一个 C++ 和 Python 库,内置专用于处理不确定性数据的模型和算法。该库的主要目标是提供处理工业应用研究中的不确定性所需的所有功能。官方表示,该软件的目标用户是所有希望在迄今为止的确定性研究中引入概率维度的工程师。
- 多元概率建模,包括依赖
- 专用于处理不确定性的数值工具
- 与任何类型的物理模型的通用耦合
- 开源,LGPL 许可,C++/Python 库
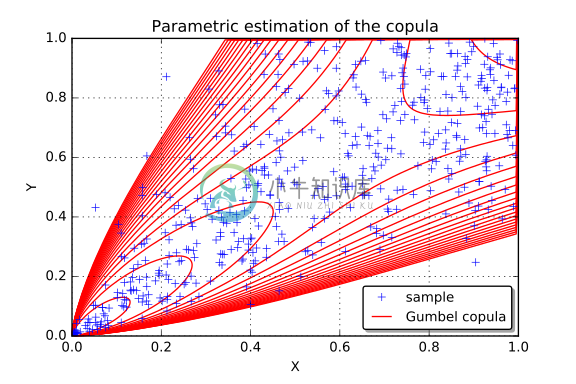
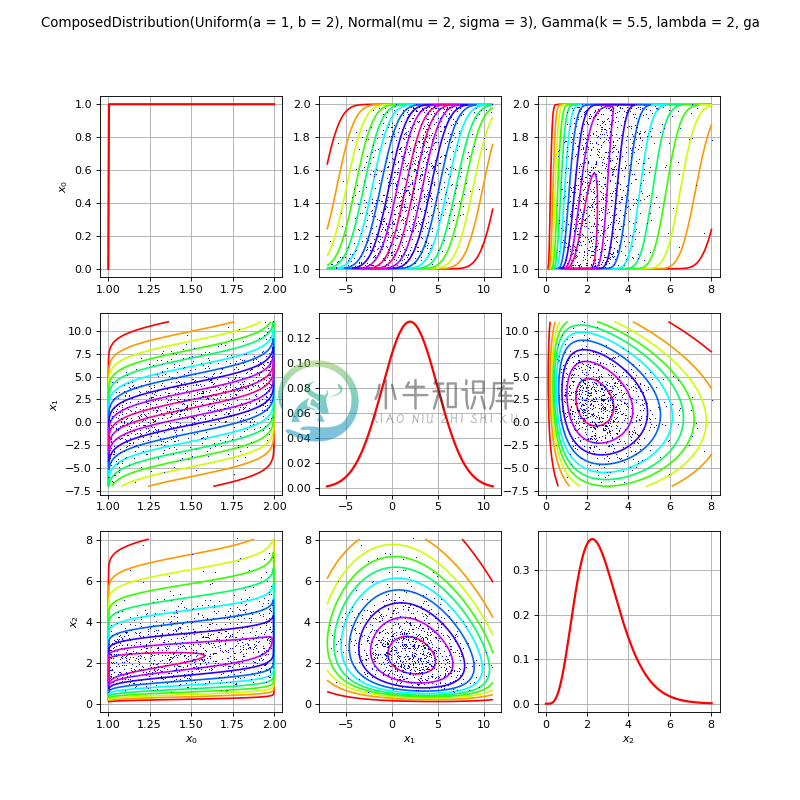
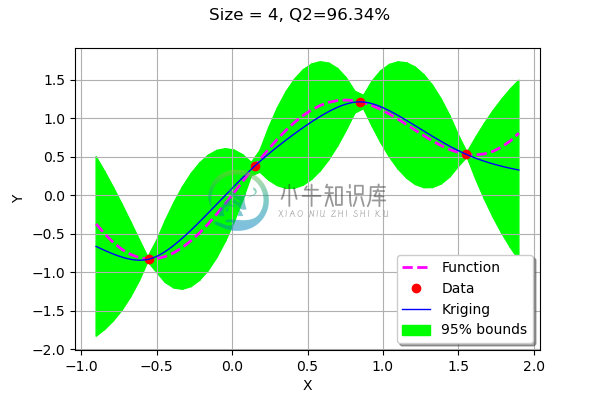
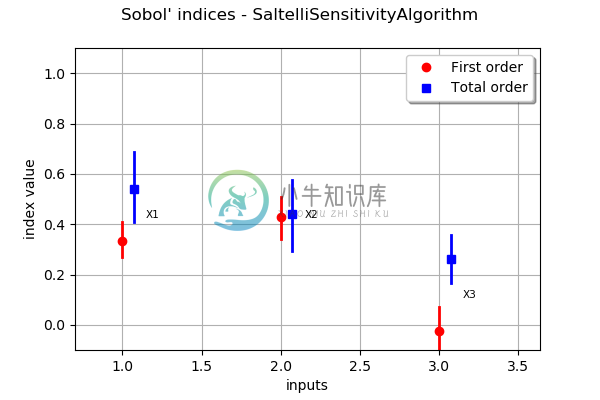
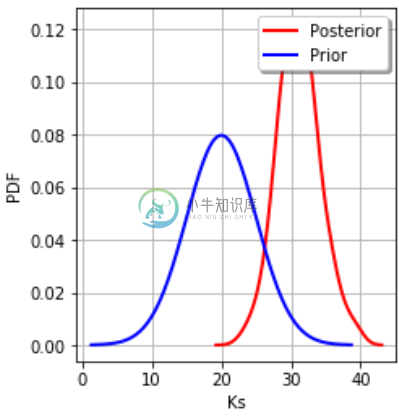
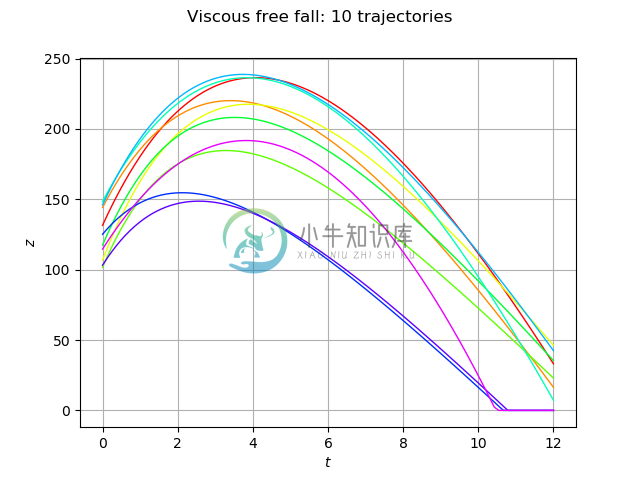
-
本文向大家介绍json数据处理及数据绑定,包括了json数据处理及数据绑定的使用技巧和注意事项,需要的朋友参考一下 一.json数据处理 1.json数据 2.获取数据 数据注入:"{{data}}" 3.数据处理: 4.数据绑定 以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持呐喊教程!
-
本文向大家介绍python数据预处理 :数据共线性处理详解,包括了python数据预处理 :数据共线性处理详解的使用技巧和注意事项,需要的朋友参考一下 何为共线性: 共线性问题指的是输入的自变量之间存在较高的线性相关度。共线性问题会导致回归模型的稳定性和准确性大大降低,另外,过多无关的维度计算也很浪费时间 共线性产生原因: 变量出现共线性的原因: 数据样本不够,导致共线性存在偶然性,这其实反映了缺
-
目前我在写一个mariadb的驱动,但是碰到了一个问题。 mariadb的对于查询的数据返回分为了两部分: 1.每个字段的类型,类似于[i32, String] 2.以String表示的每个字段的值["1", "alpha"] 我希望把2中String表示的字段值转换成1中特定数据类型,但是由于每个查询的字段数和字段类型都是不定的,请问这个大概需要怎么做。 烦请各位大佬指一下方向,谢谢。
-
麦卡锡的非确定运算符amb几乎和Lisp一样古老,尽管现在它已经从Lisp中消失了。amb接受一个或多个表达式,并在它们中进行一次“非确定”(或者叫“模糊”)选择,这个选择会让程序趋向于有意义。现在我们来探索一下Scheme内置的amb过程,该过程会对模糊的选项进行深度优先选择,并使用Scheme的控制操作符call/cc来回溯其他的选项。结果是一个优雅的回溯机制,该机制可用于在Scheme中对问
-
我们已经将离散信源表示为马尔可夫过程。我们能不能定义一个量,用来在某种意义上,度量这样一个过程“生成”多少信息?甚至更进一步,度量它以什么样的速率生成信息? 假定有一个可能事件集,这些事件的发生概率为。这些概率是已知的,但关于将会发生哪个事件,我们也就知道这么多了。我们能否找到一种度量,用来测量在选择事件时涉及多少种“选择”,或者输出中会有多少不确定性? 如果存在这样一种度量,比如说,那要求它具有
-
问题内容: 我写了这个查询: 返回结果: 这正是我想要的结果。我的问题是,“援助”中不会总是有四个不同的值。是否可以重写此查询(或使用存储过程),以使“ a *”列的数量取决于“援助”中有多少个不同的值? 问题答案: 您将需要使用“动态数据透视表”来获取所需的列列表。这将首先检索列的列表,然后旋转该列表。类似于以下内容: